JVM字符编码问题
在学习张宏老师的《自己动手写Java虚拟机时》,发现了一个问题。
老师并没有解释为什么在class文件中使用Modified UTF-8,不过,距离这本书出版已有7年之久,所以我尝试去寻找到答案。

1.前置知识:
标准ASCII字符集
由于计算机底层是使用二进制存储,所以要将字符存储进计算机,由于当时还不需要支持中文和其他文字,只需要存储英文字母(大小写)数字,标点符号,特殊字符。就有了ASCII集。
ASCII集对这些需要存储的字符做了编号,总共128个字符。存储进计算机,只需要转成二进制,再补了零,让它刚好一个字节,存储进计算机用一个字节存储。
GBK
为了支持中文,就有了GBK (汉字内码扩展规范,国标)汉字编码字符集,包含了2万多个汉字等字符,GBK中一个中文字符编码成两个字节的形式存储。
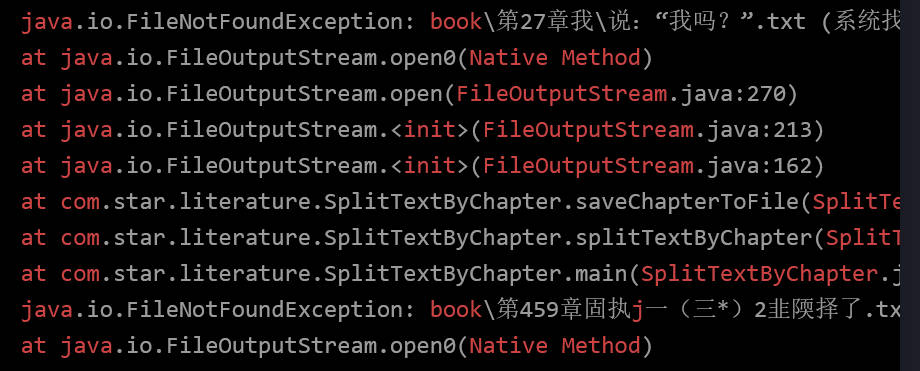
‘我K你’在计算机怎么存储?
两个字节存储“我”,一个字节存储“K”,两个字节存储“你”
而GBK规定:汉字的第一个字节的第一位必须是1,再因为ASCII字符集首位都是零。计算机就可以区分了
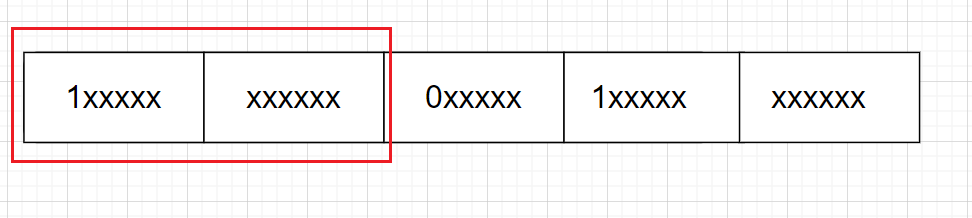
两个字节,第一个为1,剩下15位,可以表示2的15次方(32768)个汉字
Unicode字符集(统一码):
Unicode是国际组织制定的,可以容纳世界上所有文字,符号的字符集。Unicode 字符集的编码范围是 0x0000 – 0x10FFFF (最大21位), 可以容纳一百多万个字符, 每个字符都有一个独一无二的编码,也即每个字符都有一个二进制数值和它对应。
UTF-32,4个字节表示一个字符 ,占存储空间,通信效率变低!所以就产生了UTF-8
UTF-8:
U(Unicode统一码)T(Transformation转换)F(Format格式)-8
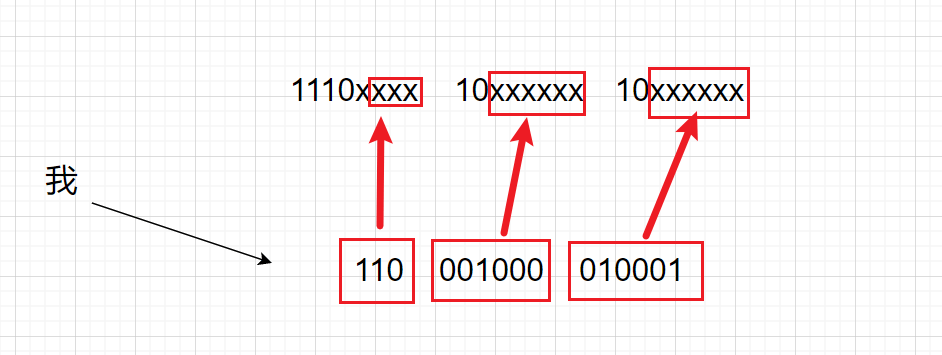
UTF-8是Unicode字符集的一种编码方案,采取可变长编码方案,共分四个长度区:1个字节,2个字节,3个字节,4个字节
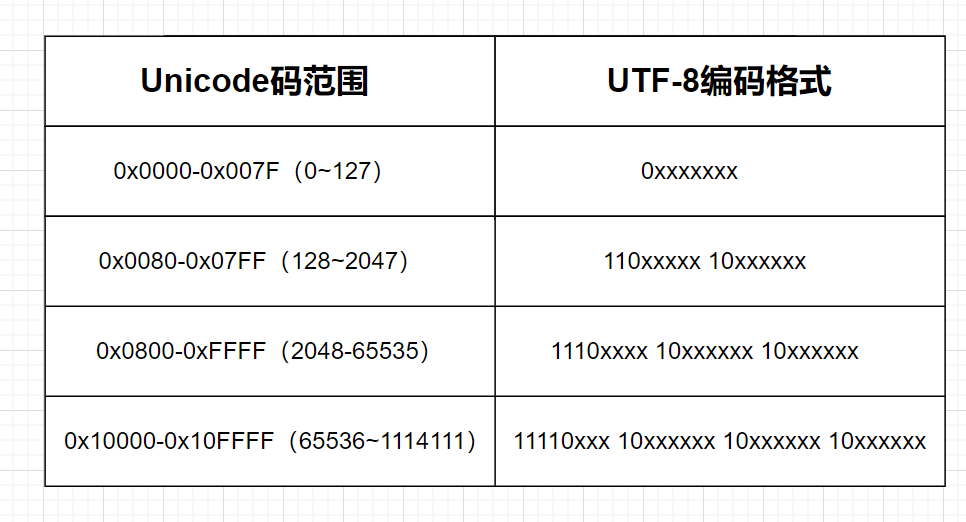
- ASCII字符集首位都是零。计算机直接区分了
- 如果两个字节存储,则要求第一个字节以110开头,第二个字节以10开头
- 如果三个字节存储,则要求第一个字节以1110开头,第二个字节以10开头,第三个字节以10开头,
- 如果四个字节存储,则要求第一个字节以11110开头,第二个字节以10开头,第三个字节以10开头,第四个字节以10开头。
存储方式如图,比如“我”这个汉字:25105
UTF-16:
UTF-16是以双字节为单位的Unicode编码的编码。
问题来了:Unicode 字符集的编码范围是 0x0000 – 0x10FFFF (最大21位),Java的双字节数据类型比如char(16位,双字节),无法表示Unicode全部码点。
所以就有了UTF-16
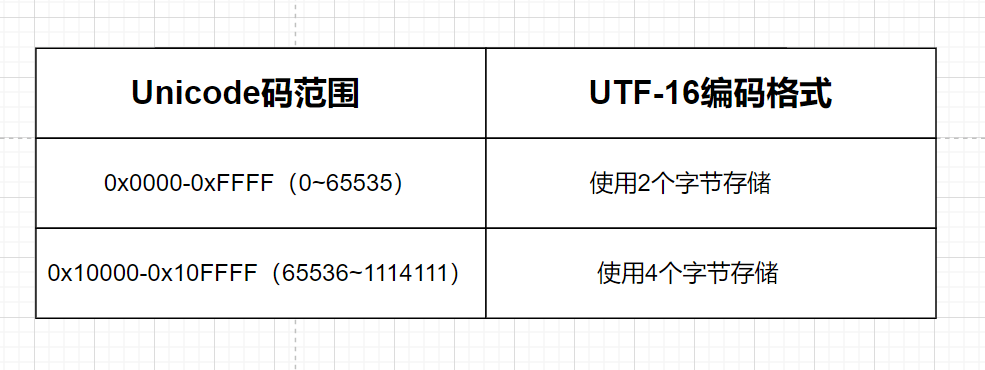
首先,码点0x0000-0xFFFF(0~65535):将十进制码点值,直接转换为2个字节长度的二进制数字,不足补零。
Unicode 字符集的编码范围是 0x0000 – 0x10FFFF (最大21位),而0x10000-0x10FFFF(65536~1114111)即当大于65535,就复杂了,,比如java16位的双字节数据类型完全无法表示,UTF-16使用两个双字节来表示它。
步骤:
- Unicode 字符集的编码范围是 0x10000 – 0x10FFFF (最大21位),为了更好操作,把他变为20位,即对其减去0x10000.这样范围就变为 0x00000 – 0xFFFFF
- 20位刚好可以分为两个10位。前10位放在一个字节称为高位代理项(high surrogate),后10位放在另一个字节称为低位代理项(low surrogate),此时代理项的范围是0x0000-0x03FF.
- 这时,代理项就与BMP冲突了,所以就把代理项平移到保留区(0xD800 – 0DFFF),同时,为了避免高位代理项与低位代理项冲突,就将低位代理项平移到高位代理项在保留区的后面,给高位代理项加上0xD800,平移到0xD800 – 0DBFF区;给底位代理项加上0xDC00,平移到0xDC00 – 0DFFF区
比如,在网站SYMBL (◕‿◕) 符号,表情符号,象形文字,文字,字母表和整个Unicode
找到的这个字符:

Unicode 码是0x1F631
码点为128561
- 将0x1F631减去0x10000等于F631
- 转换为20位比特的二进制数字,不够20位比特,则在前面补0,为0000111101 1000110001
- 将前10个比特单独取出,和 0xD800(1101 1000 0000 0000)相加,得到1101 1000 0011 1101
- 将后10个比特单独取出,和0xDC00(1101 1100 0000 0000)相加,得到1101 1110 0011 0001
- 最后,合并起来,得到的二进制字节就是UTF-16的编码结果,总共是4个字节(1101 1000 0011 1101 1101 1110 0011 0001)
- 区间[0xD800, 0xDFFF]中的码点, 专用于UTF-16的代理项,未定义任何字符,
- 高位代理项的范围是[0xD800, 0xDBFF],而低位代理项的则是[OxDC00, 0xDFFF],是不重叠的。
Modified UTF-8:
MUTF-8编码,其实是对UTF-16字符编码的再编码。

如图:

大致意思是:
此格式与标准UTF-8格式的区别如下:
- 空字节’\u0000’以2字节格式编码,而不是1字节格式,因此编码的字符串永远不会嵌入空。
- 只使用1字节、2字节和3字节格式。
- 补充字符以代理对的形式表示。
总结:
- MUTF-8编码在0x10000-0x10FFFF(65536~1114111)与UTF-8一致,除了’\u0000′
- 对于空字节’\u0000’,在UTF-8直接使用1个字节去存储(0000 0000),而MUTF-8会使用2个字节去存储,最后存储的值为0xC080(1100 0000 1000 0000)。也就是会被编码成2字节:0xC0、0x80;
- 而在0x10000-0x10FFFF(65536~1114111)中,以三个字节存储,要求第一个字节以1110开头,后面的4个比特位用来存放UTF-16编码的高4位。第二个字节以10开头,后面6个比特位用来存放UTF-16编码的中间6位。第三个字节以10开头,后面6个比特位用来存放UTF-16编码的最低6位。
2.解决问题:
问题的答案终于来了:
(1)标志字符串结尾

MUTF-8对数值0做了特殊处理,0被MUTF-8编码用来表示字符串结束,和C语言的字符串表示法相兼容,保证了在已编码字符串中没有嵌入空字节,因为在C语言等语言中,单字节空字符如’\u0000’是用来标志字符串结尾的。也许这更能体现jvm是跨语言的平台了
(2)减少运算量
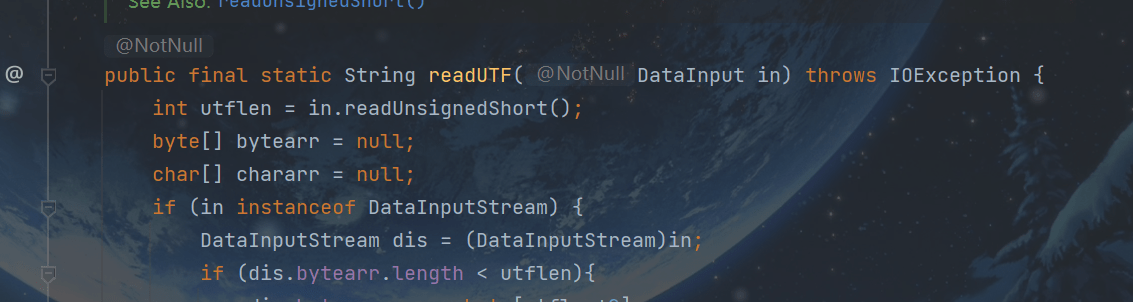
如.class文件modified UTF-8进行编码的,解码出来的码元是UTF-16编码出来的2字节。JVM把UTF-16编码出来的16位长的数据(2字节,操作系统用8位长的数据,即1字节)作为最小单位进行信息交换。而如java的char,java的char是2字节16位,java的内码是UTF-16。modified UTF-8可以一次编为一个UTF-16码,就减少了很多扩展字符从UTF-8转码到UTF-16时的运算量。
那么如何转换呢?
扩展:
内码:程序内部使用的字符编码,如java的char,所以java的char是2字节16位,java的内码是UTF-16。
外码:程序外部交互时使用的字符编码,如class文件。java的外码是MUTF-8。
参考:
Chapter 4. The class File Format (oracle.com)
DataInput (Java Platform SE 8 ) (oracle.com)
unicode – Why does Java use modified UTF-8 instead of UTF-8? – Stack Overflow
Unicode、UTF-8、UTF-16、MUTF-8、Java编码扫盲 – 个人文章 – SegmentFault 思否