1.步骤
一致性哈希环
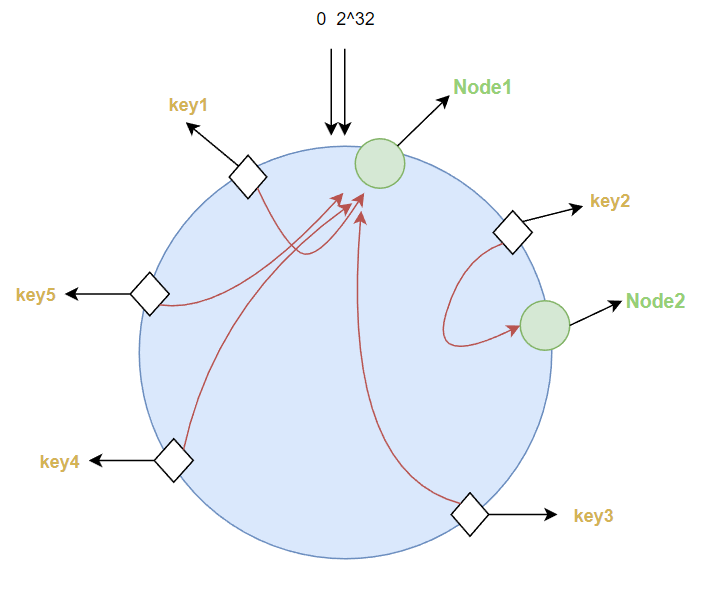
假设一个hash函数所有可能的哈希值的范围为[2,2^32]
我们假设其首尾相连,那么就构成了一个环,这就是一致性哈希环,通过hash函数取到hash值落到该环上。
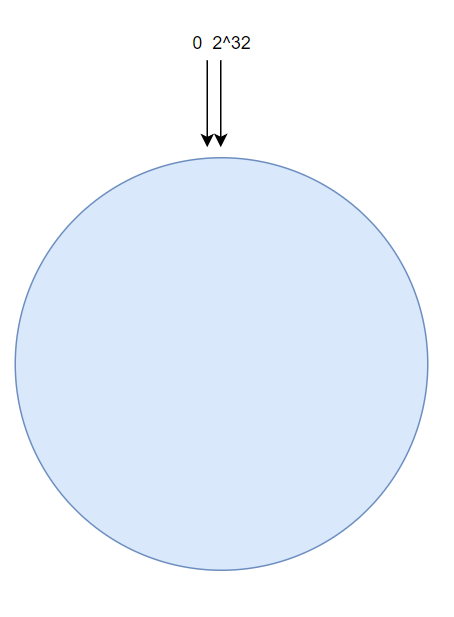
落点
假设redis集群使用该算法分发key值存储。(假设!假设!只是假设,redis集群有更优解算法)
对redis服务器ip使用该Hash函数进行哈希,这样该服务器就能确定其在哈希环上的位置:
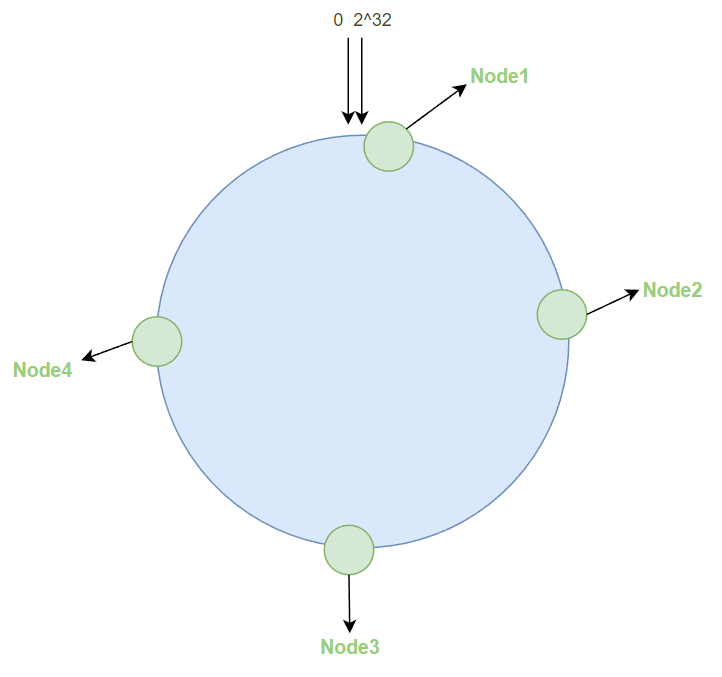
而当接收到key值时,同样对其使用该Hash函数进行哈希,落在环上
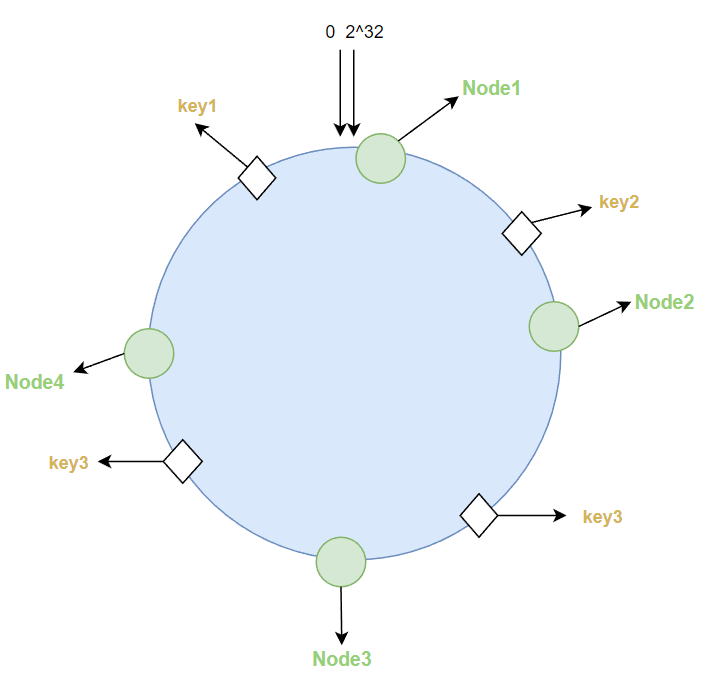
则该key值就归于顺时针下的第一个节点,比如key1就归于node1,key2就归于node2等
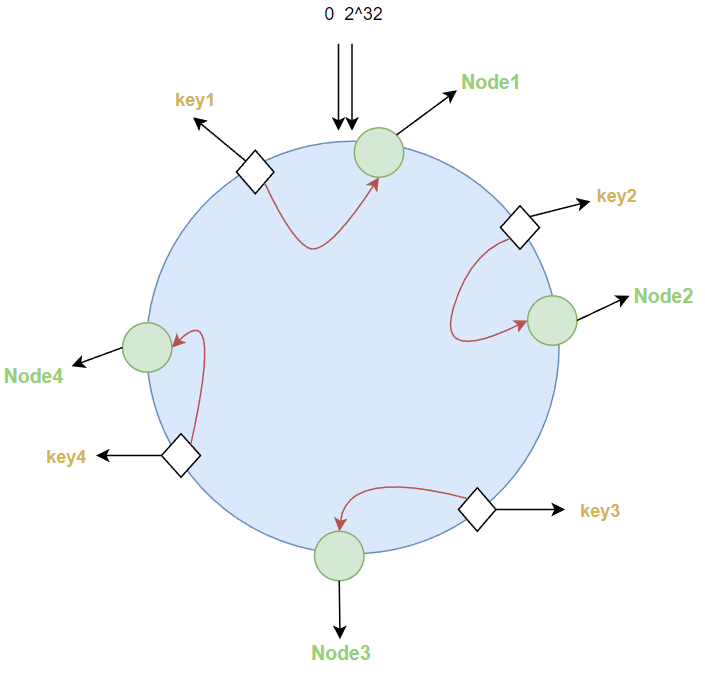
2.优点
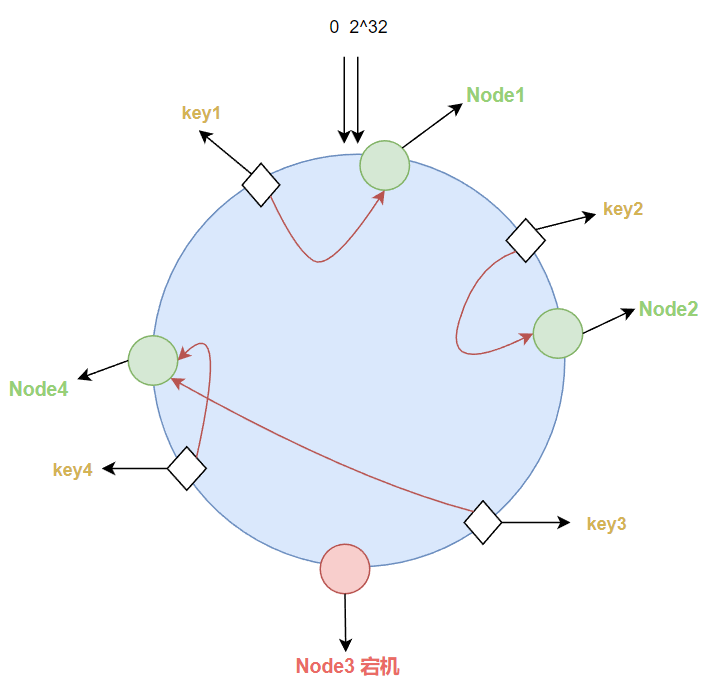
如果其中一个节点宕机如node3,在其身上的值自动归于顺时针下的第一个节点node4,也就是受影响的只有宕机节点前一个节点和后一个节点在hash环上的范围的值。
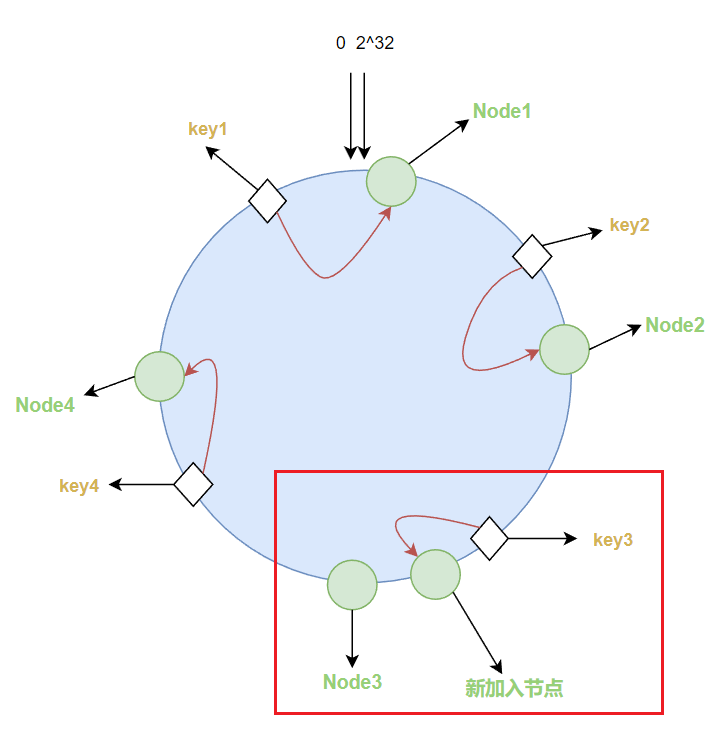
如果新加入一个节点,也只会影响前一个节点到新加入节点在hash环上的范围的值。
3.缺点
数据倾斜,如果服务节点太少,容易因为节点分布不均匀而造成数据倾斜
4.优化
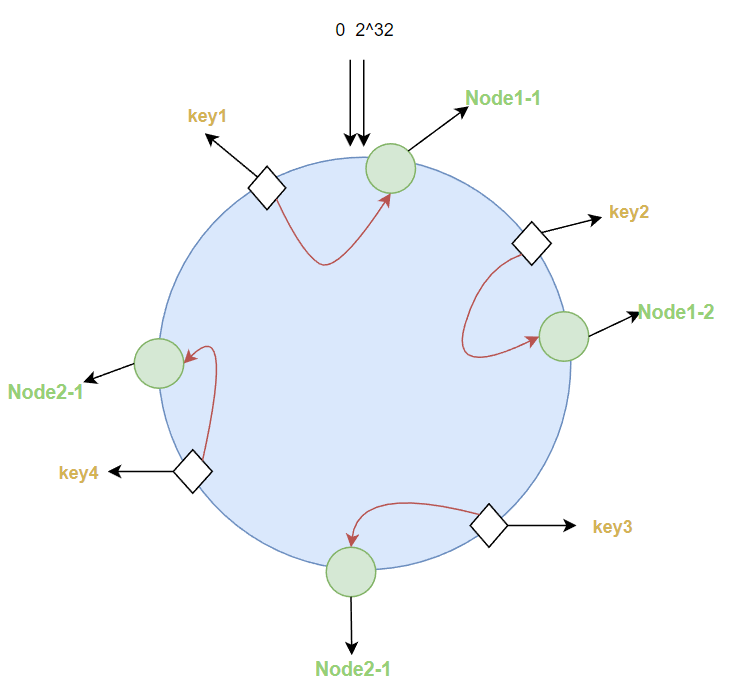
针对数据倾斜问题,一致性哈希算法对每一个服务节点计算多个哈希,比如可以对服务器节点ip添加对应字符串,这样一个服务节点就可以计算多个哈希结果,每个计算结果位置都放置一个,称为虚拟节点。如图的Node1就分为了Node1-1、Node1-2。相对的解决了数据倾斜问题,发布就均匀了一点。
参考