笔记参考于尚硅谷宋红康:JVM全套教程:https://www.bilibili.com/video/BV1PJ411n7xZ
5.JProfiler
1.基本概述
介绍
在运行Java的时候有时候想测试运行时占用内存情况,这时候就需要使用测试工具查看了。在eclipse里面有Eclipse Memory Analyzer tool(MAT)插件可以测试,而在IDEA中也有这么一个插件,就是JProfiler。JProfiler 是由 ej-technologies 公司开发的一款 Java 应用性能诊断工具。功能强大,但是收费。
官网下载地址:Java Profiler – JProfiler (ej-technologies.com)
特点
特点:
- 使用方便、界面操作友好 (简单且强大)
- 对被分析的应用影响小(提供模板)
- CPU,Thread,Memory分析功能尤其强大
- 支持对jdbc,noSql, jsp, servlet, socket等进行分析
- 支持多种模式(离线,在线)的分析
- 支持监控本地、远程的JVM
- 跨平台,拥有多种操作系统的安装版本
主要功能
1.方法调用
对方法调用的分析可以帮助您了解应用程序正在做什么,并找到提高其性能的方法
2.内存分配
通过分析堆上对象、引用链和垃圾收集能帮您修复内存泄漏问题,优化内存使用
3.线程和锁
JProfiler提供多种针对线程和锁的分析视图助您发现多线程问题。
4.高级子系统
许多性能问题都发生在更高的语义级别上。例如,对于JDBC调用,您可能希望找出执行最慢的 SQL语句。JProfiler支持对这些子系统进行集成分析。
2.安装与配置
下载与安装
官网下载地址:Java Profiler – JProfiler (ej-technologies.com)
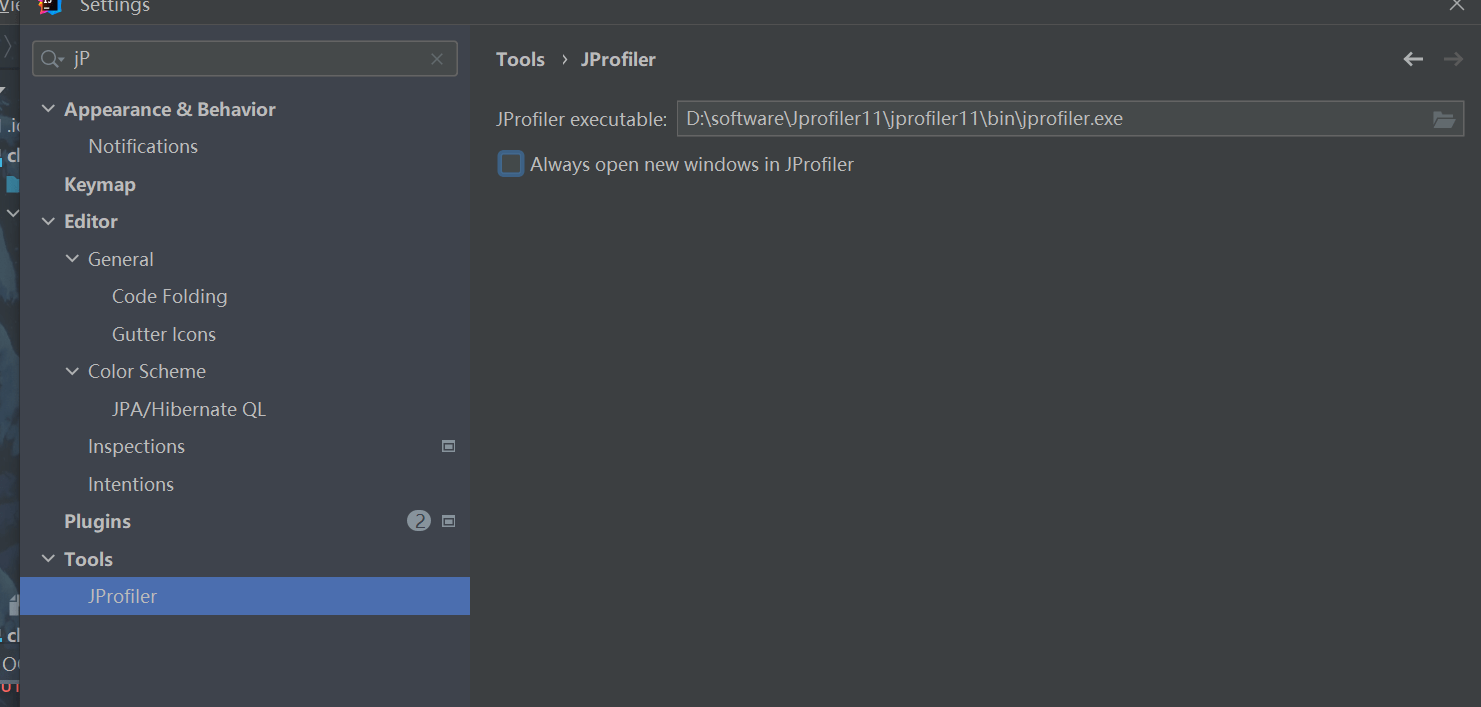
JProfiler中配置IDEA
新版本不需要
IDEA集成JProfiler
下载插件后
进入JProfiler
会出现一个选择:
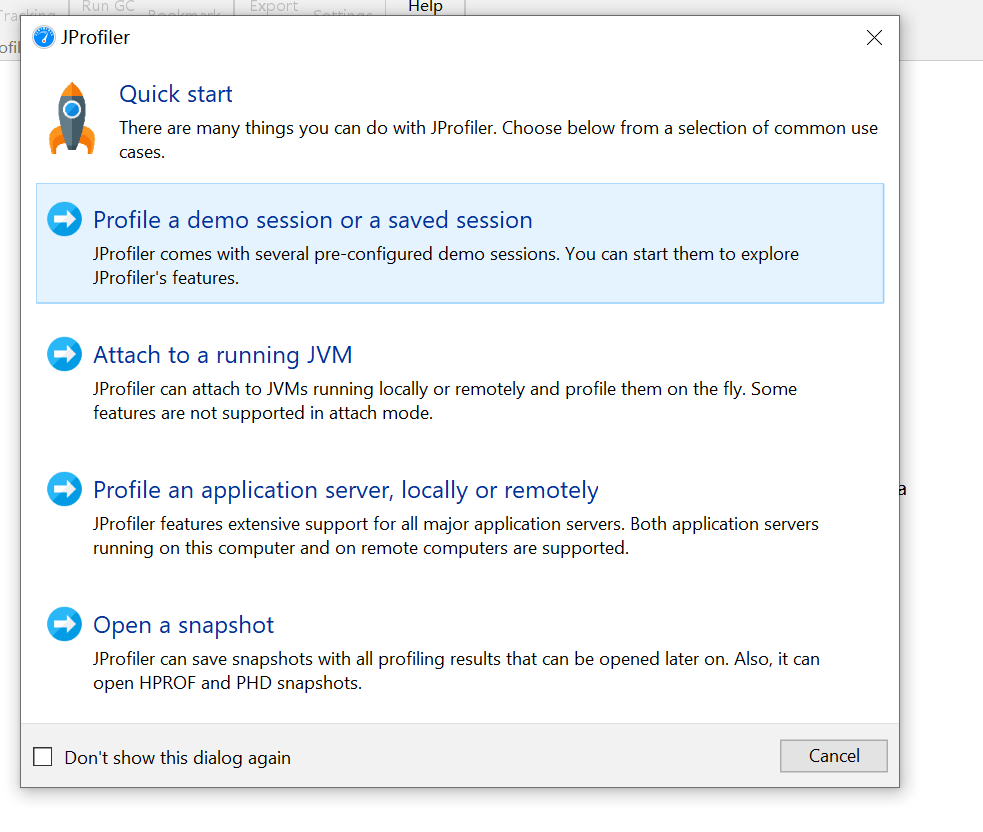
大致为:
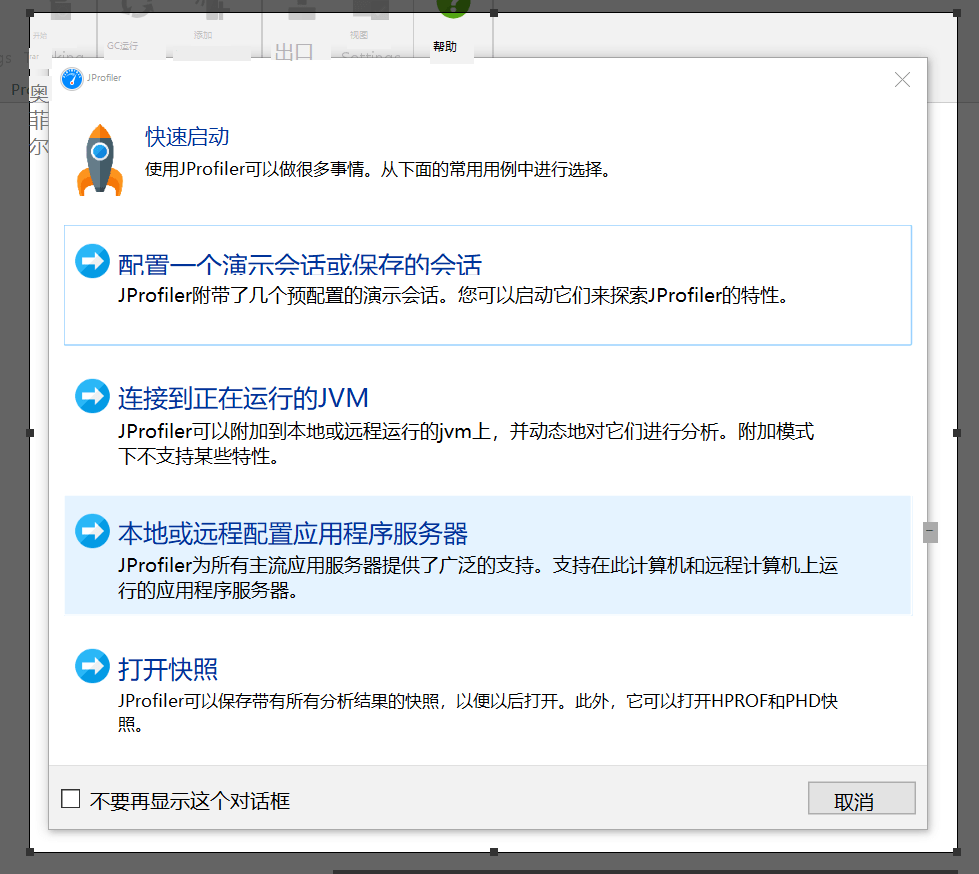
第一个选项:可以保存连接
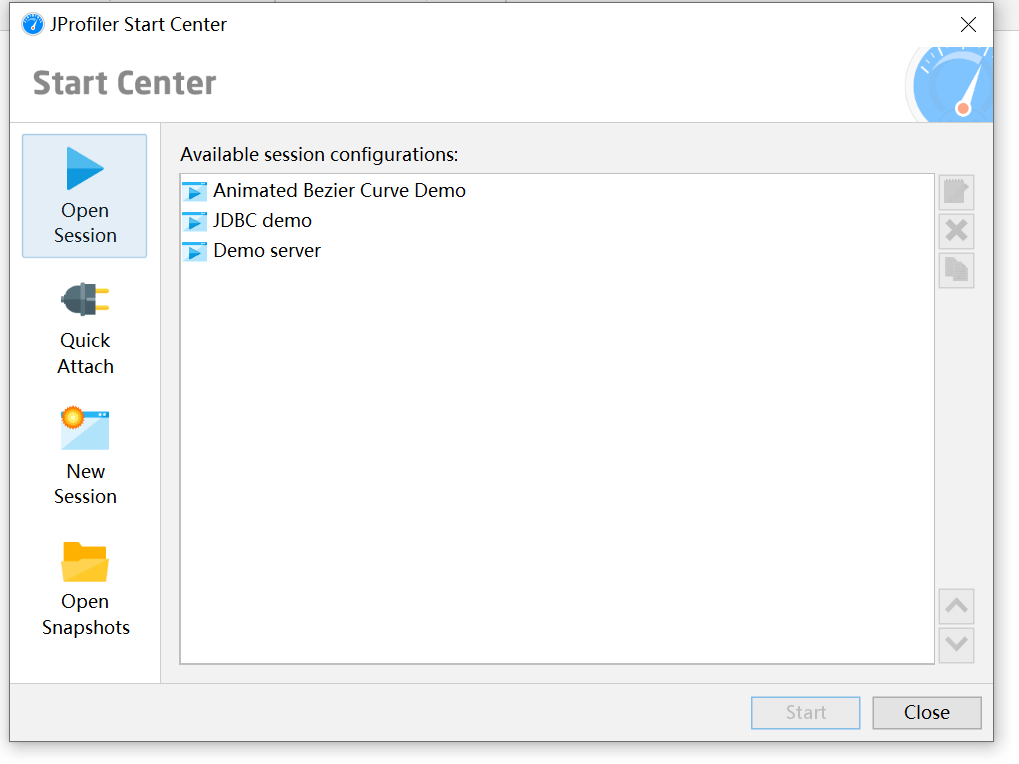
第二个选项可以连接当前运行的程序:
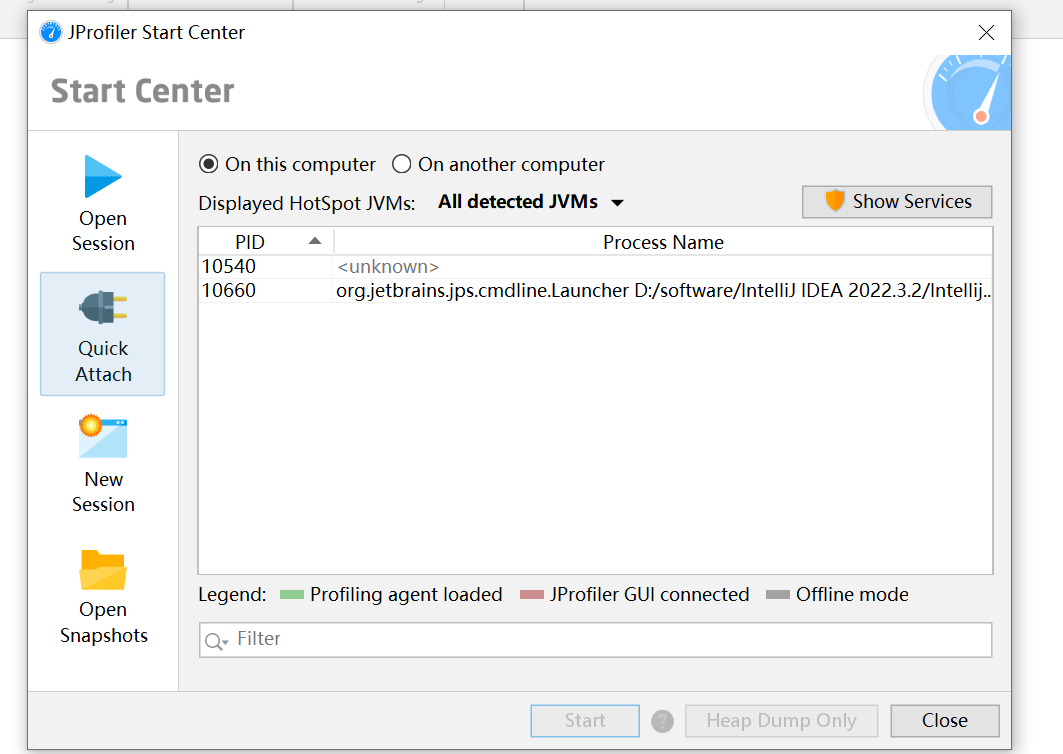
在这里也可以打开:
3.具体使用
数据采集方式
连接后,会让你选择数据采集方式
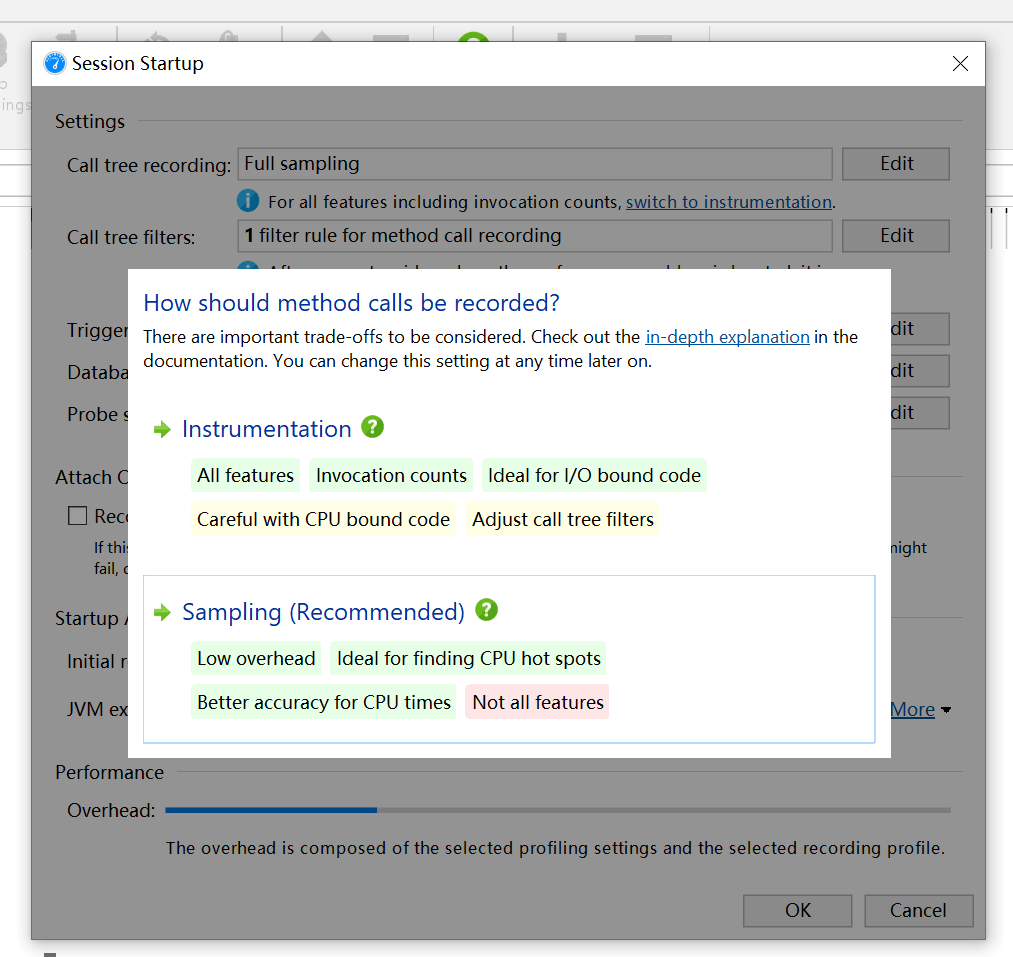
JProfier数据采集方式分为两种: Sampling(样本采集)和Instrumentation (重构模式)
- Instrumentation:这是JProfiler全功能模式。在class加载之前,JProfier把相关功能代码写入到需要分析的class的bytecode中,对正在运行的jvm有一定影响。
优点:功能强大。在此设置中,调用堆栈信息是准确的。
缺点:若要分析的class较多,则对应用的性能影响较大,CPU开销可能很高(取决于Filter的控制),因此使用此模式一般配合Filter使用,只对特定的类或包进行分析 - Sampling:类似于样本统计,每隔一定时间(5ms)将每个线程栈中方法栈中的信息统计出来。
优点:对CPU的开销非常低,对应用影响小(即使你不配置任何Filter)
缺点:一些数据/特性不能提供(例如:方法的调用次数、执行时间)
注: JProfiler本身没有指出数据的采集类型,这里的采集类型是针对方法调用的采集类型。因为JProfiler的绝大多数核心功能都依赖方法调用采集的数据,所以可以直接认为是JProfiler的数据采集类型。
选择Sampling,其余默认即可
进入后,各功能如下:
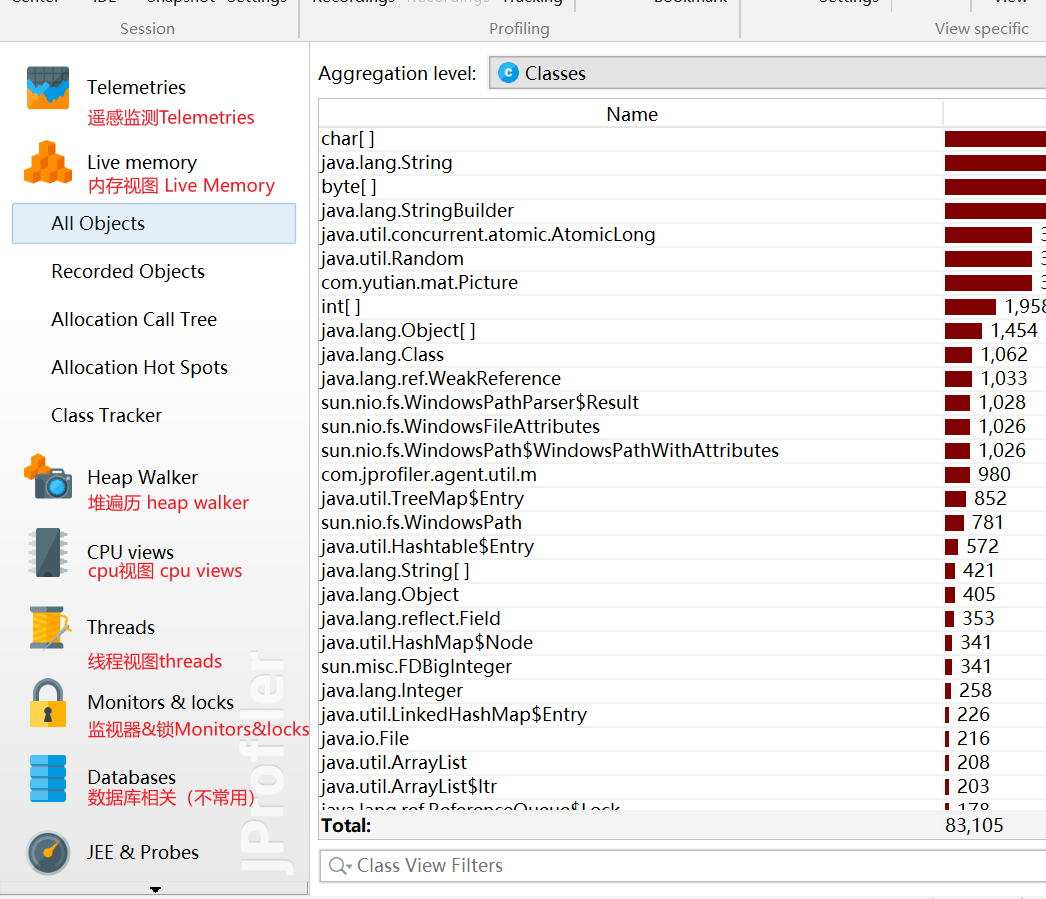
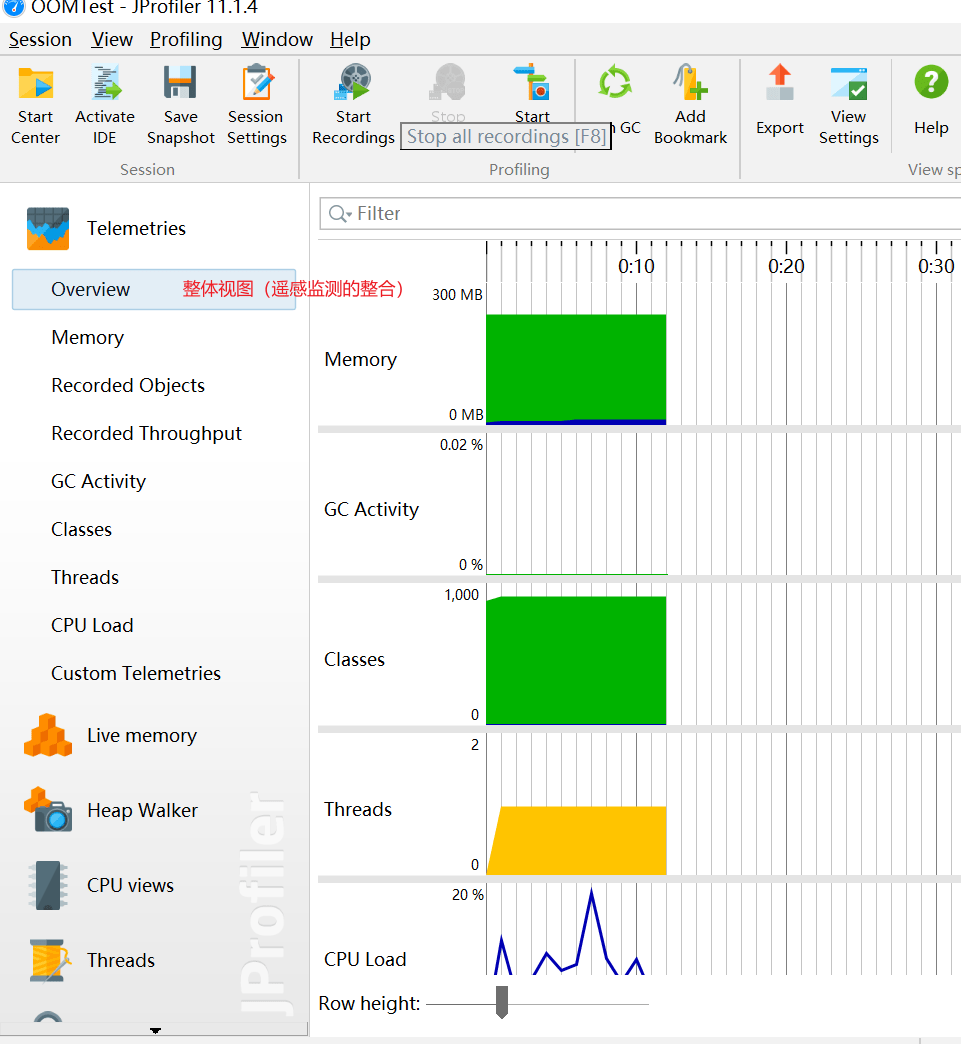
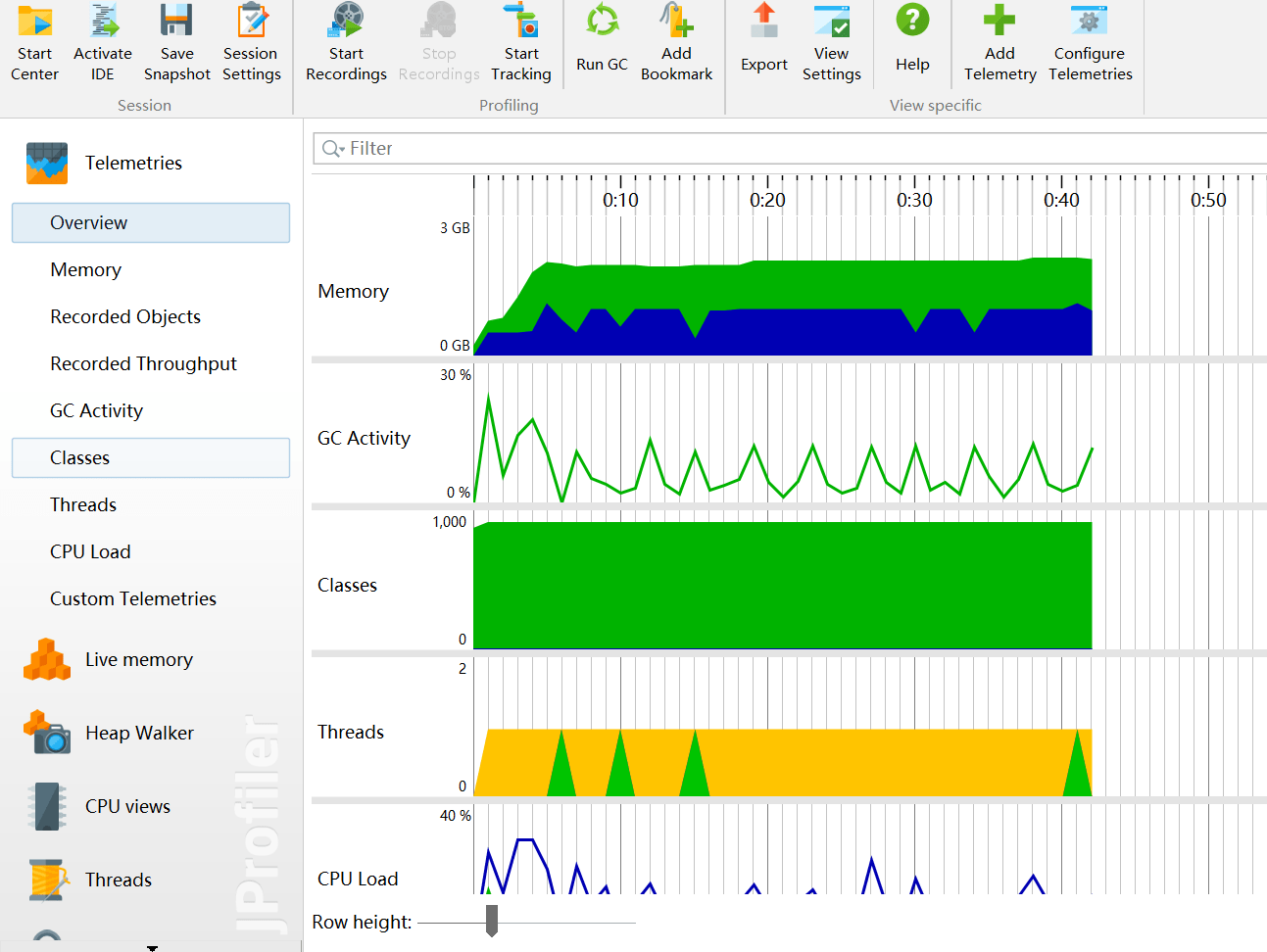
遥感监测Telemetries
遥感监测 Telemetries(查看JVM的运行信息)
- 整体视图Overview:显示堆内存、cpu、线程以及GC等活动视图
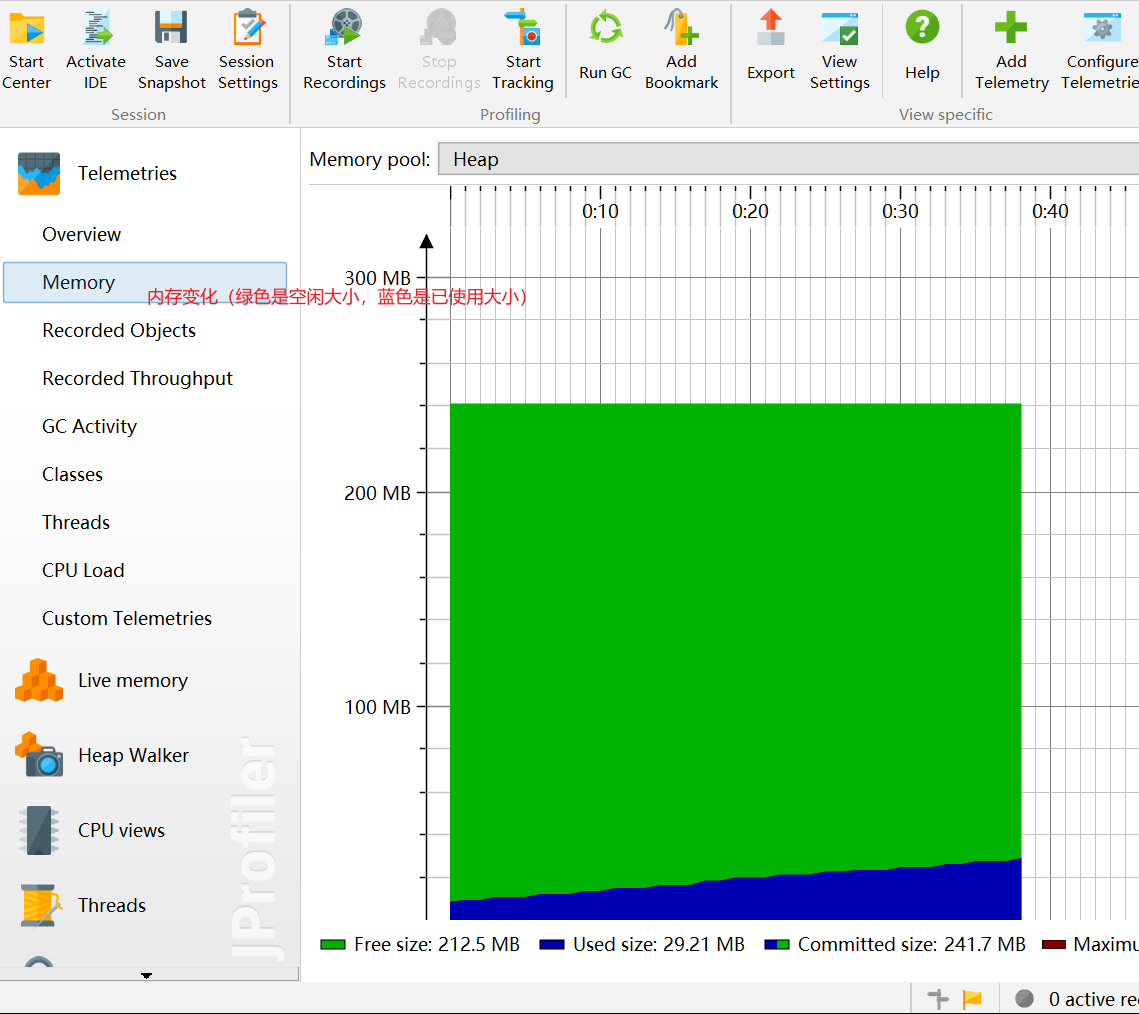
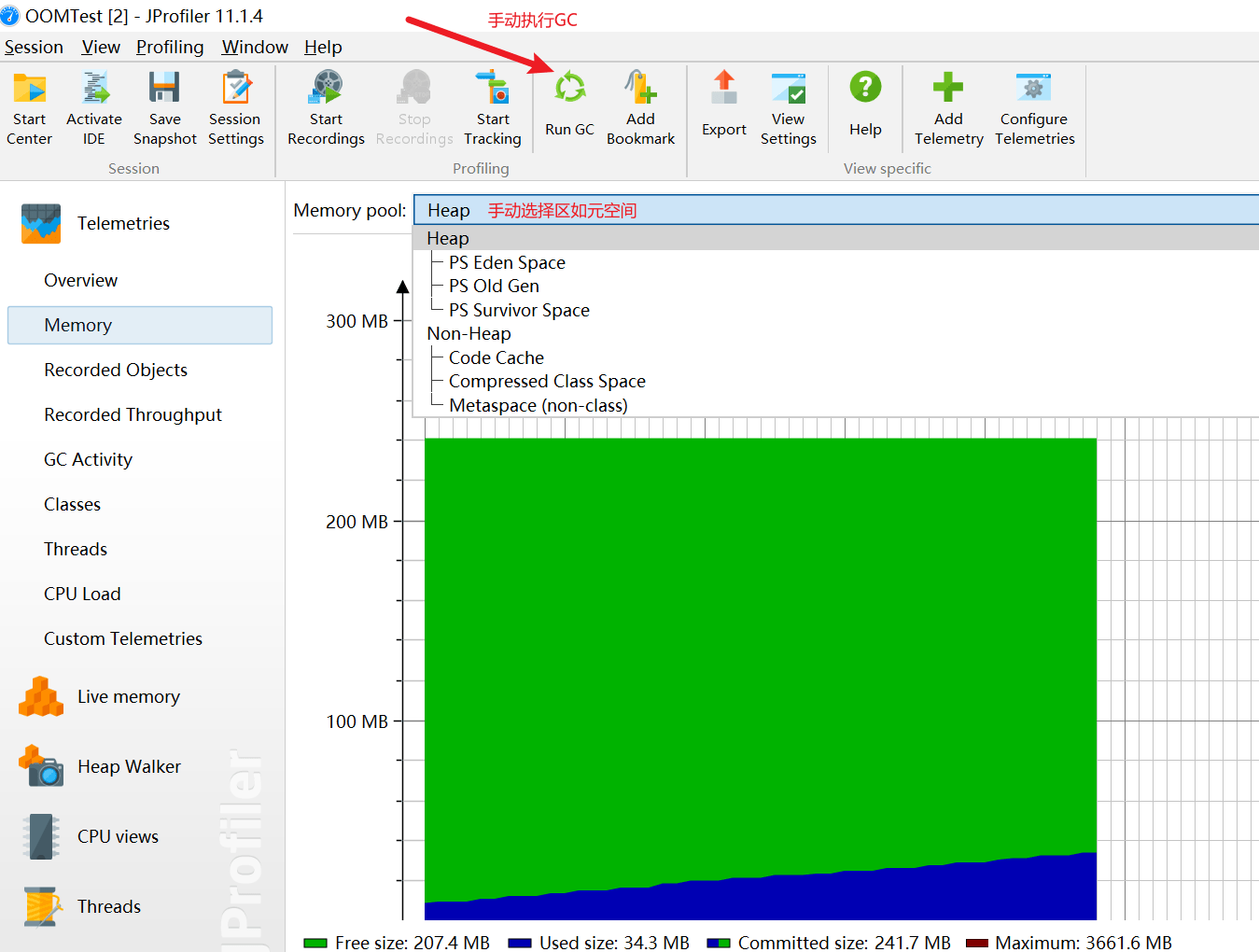
- 内存Memory:显示一张关于内存变化的活动时间表。
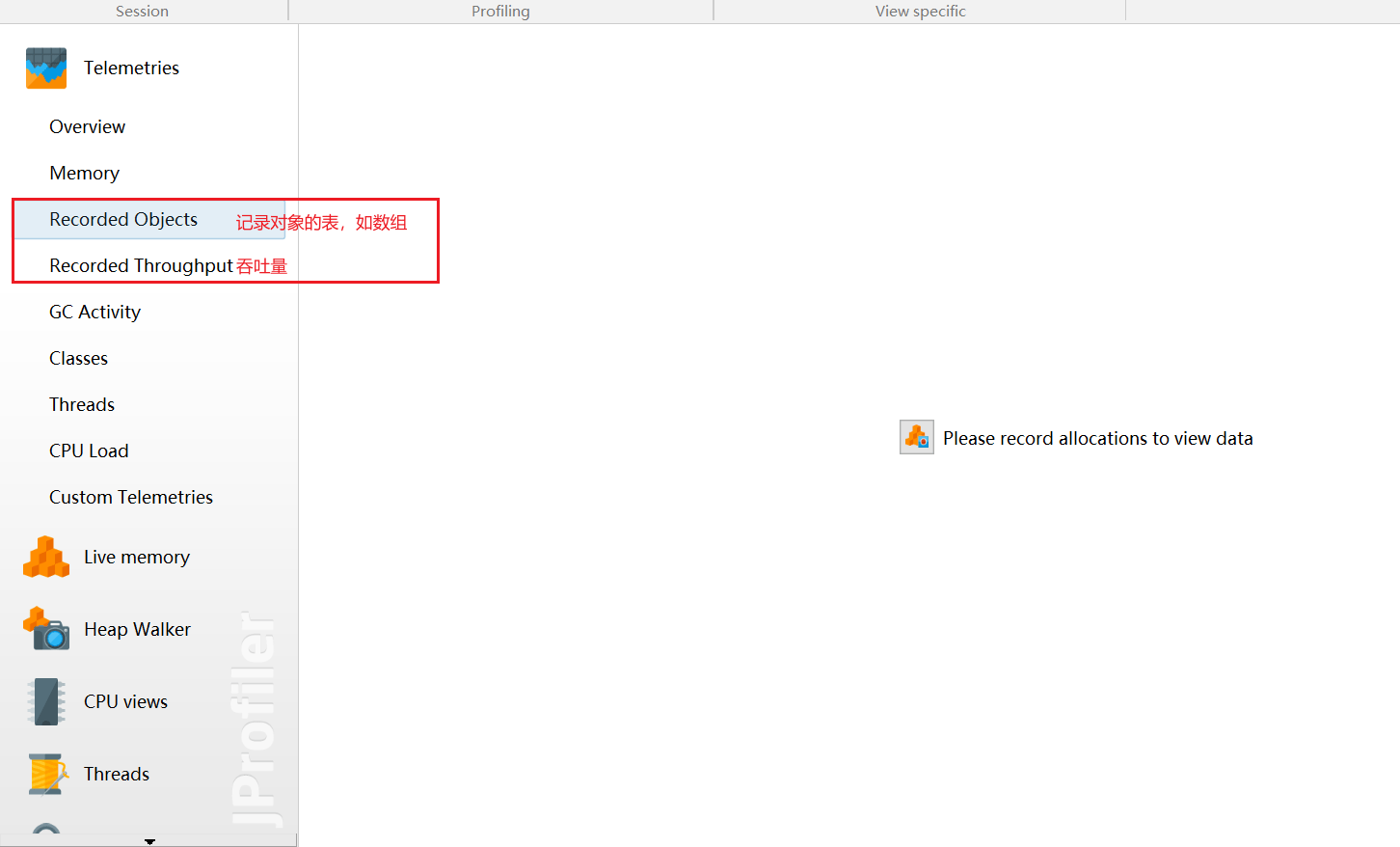
- 记录的对象 Recorded objects:显示一张关于活动对象与数组的图表的活动时间表。
- 记录吞吐量 Record Throughput:显示一段时间累计的JVM生产和释放的活动时间表。
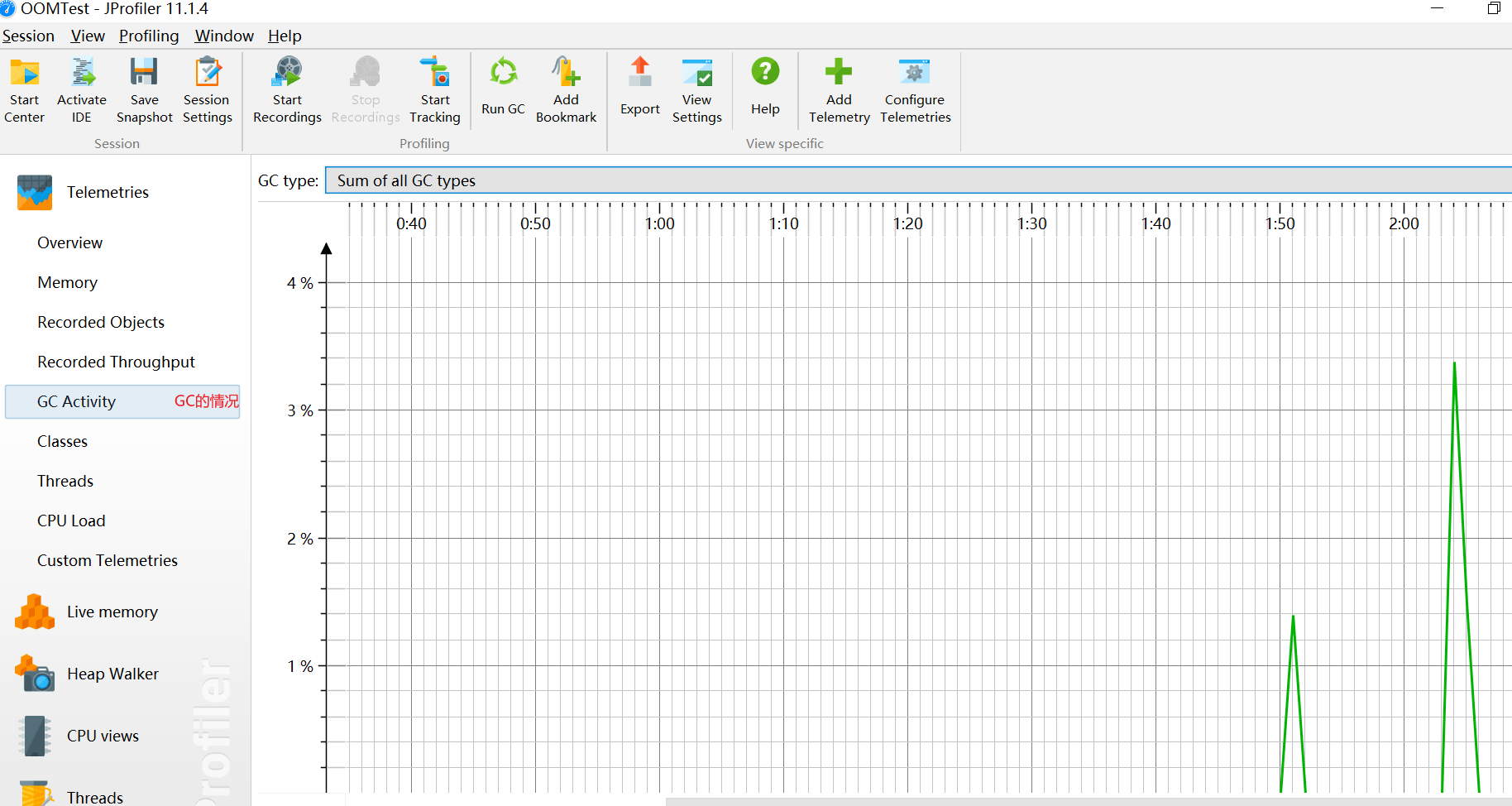
- 垃圾回收活动 GC Activity:显示一张关于垃圾回收活动的活动时间表。
- 类Classes:显示一个与已装载类的图表的活动时间表。
- 线程Threads:显示一个与动态线程图表的活动时间表
- CPU负载 CPU Load:显示一段时间中CPU的负载图表
内存视图 Live Memory
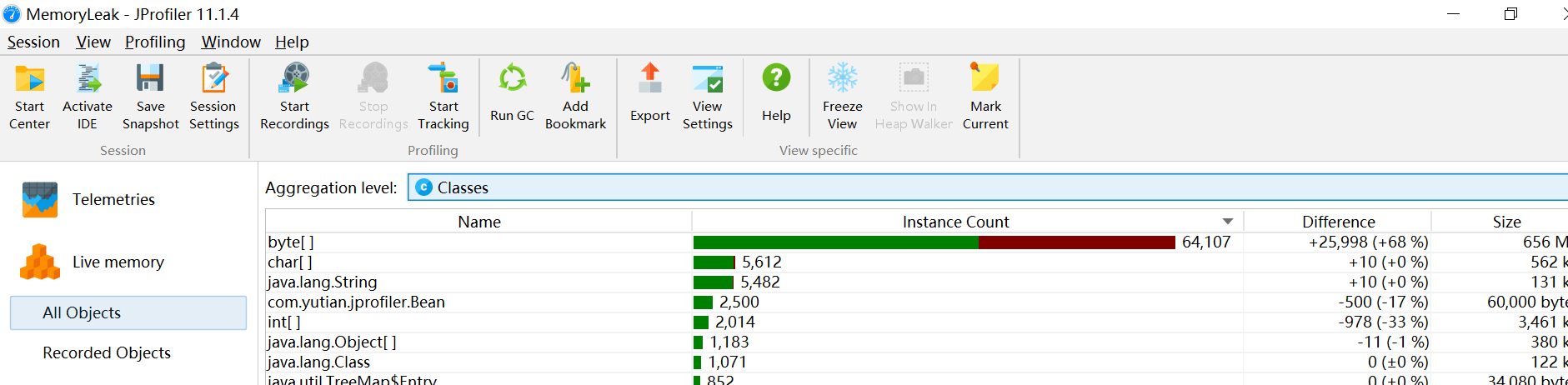
Live memory内存剖析: class/class instance的相关信息。 例如对象的个数,大小,对象创建的方法执行栈,对象创建的热点。
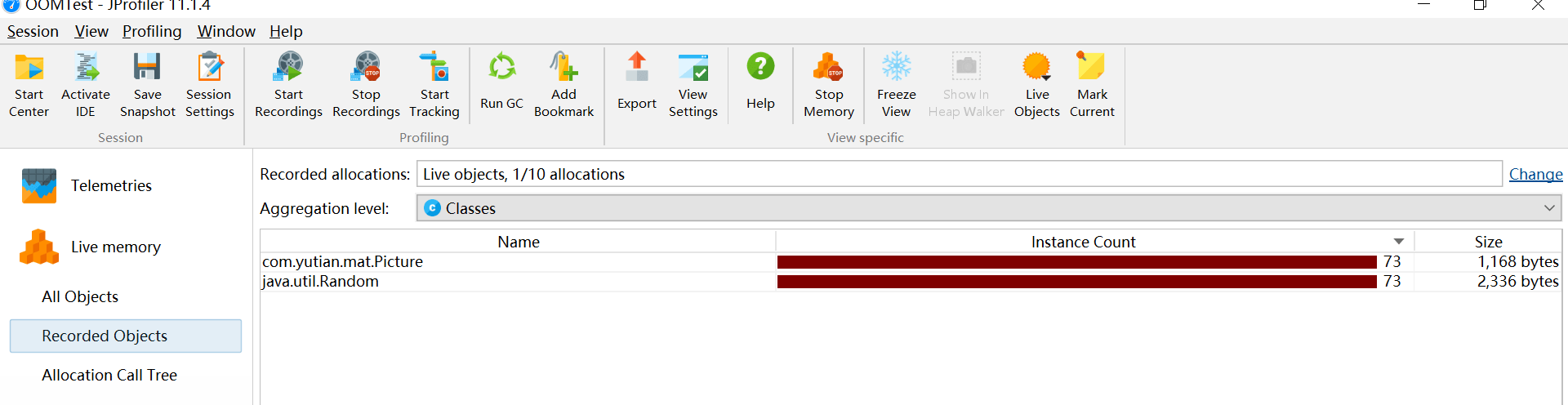
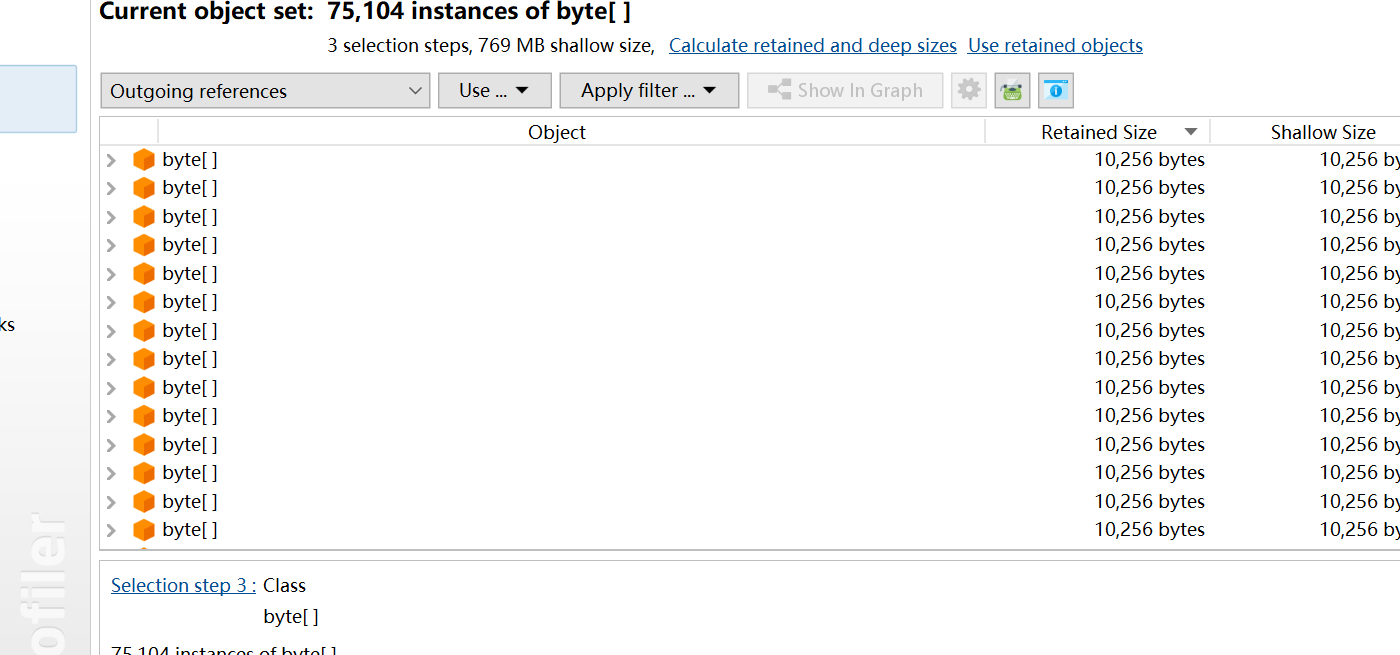
所有对象 All Objects
显示所有加载的类的列表和在堆上分配的实例数。只有Java 1.5 (JVMTI)才会显示此视图。
分析:
- 内存中的对象的情况频繁创建的Java对象:死循环、循环次数过多大
- 存在大的对象:读取文件时,byte[]应该边读边写。如果长时间不写出的话,导致byte[]过大大
- 存在内存泄漏
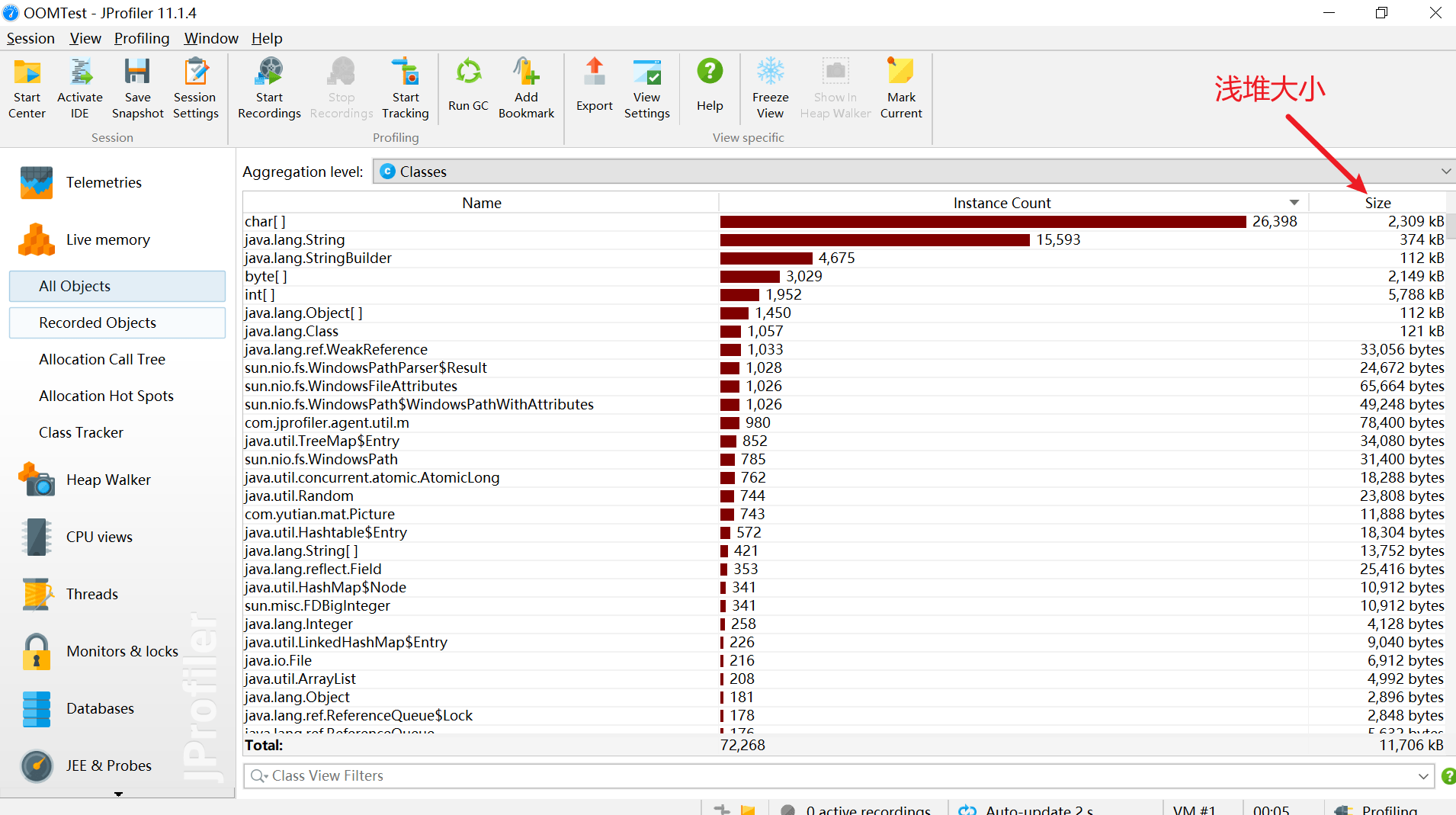
点击此处,变为后面时间与当前时间变化:
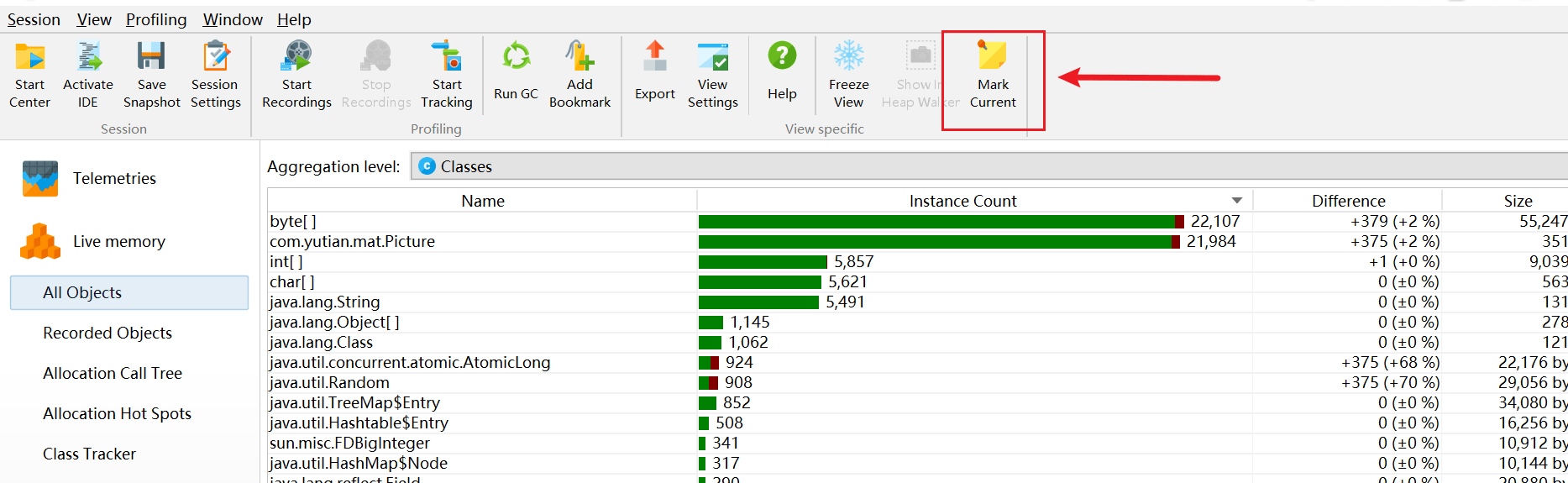
选择使用包展示
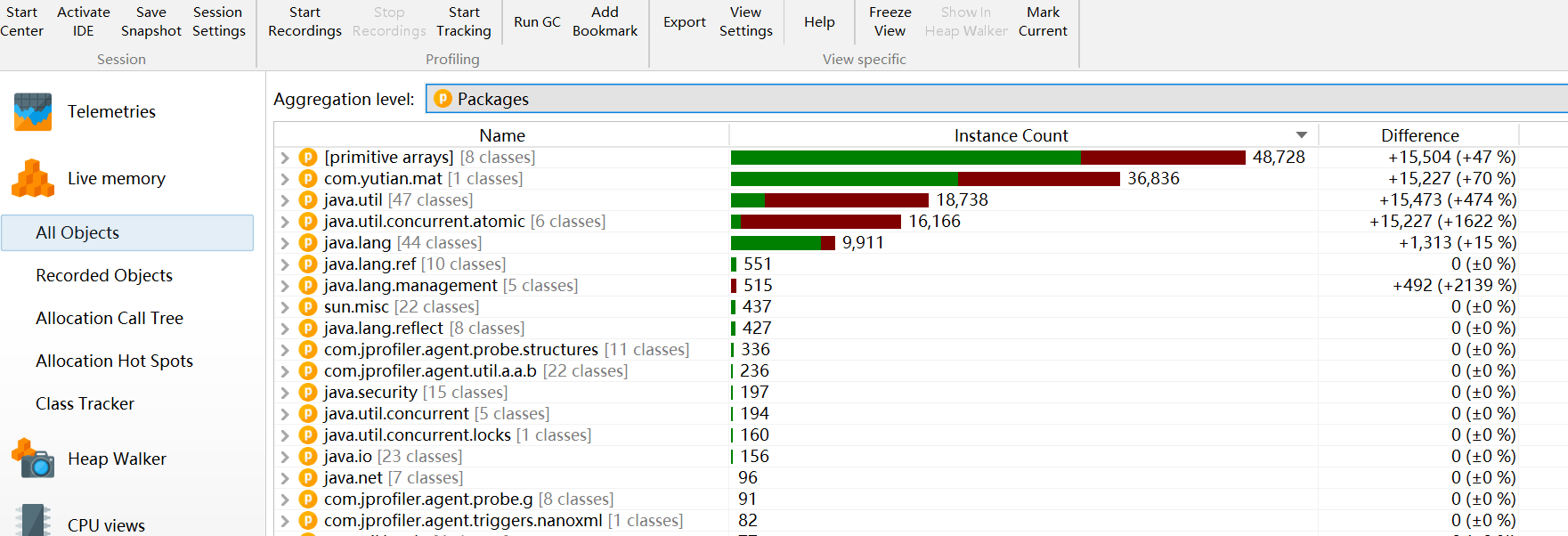
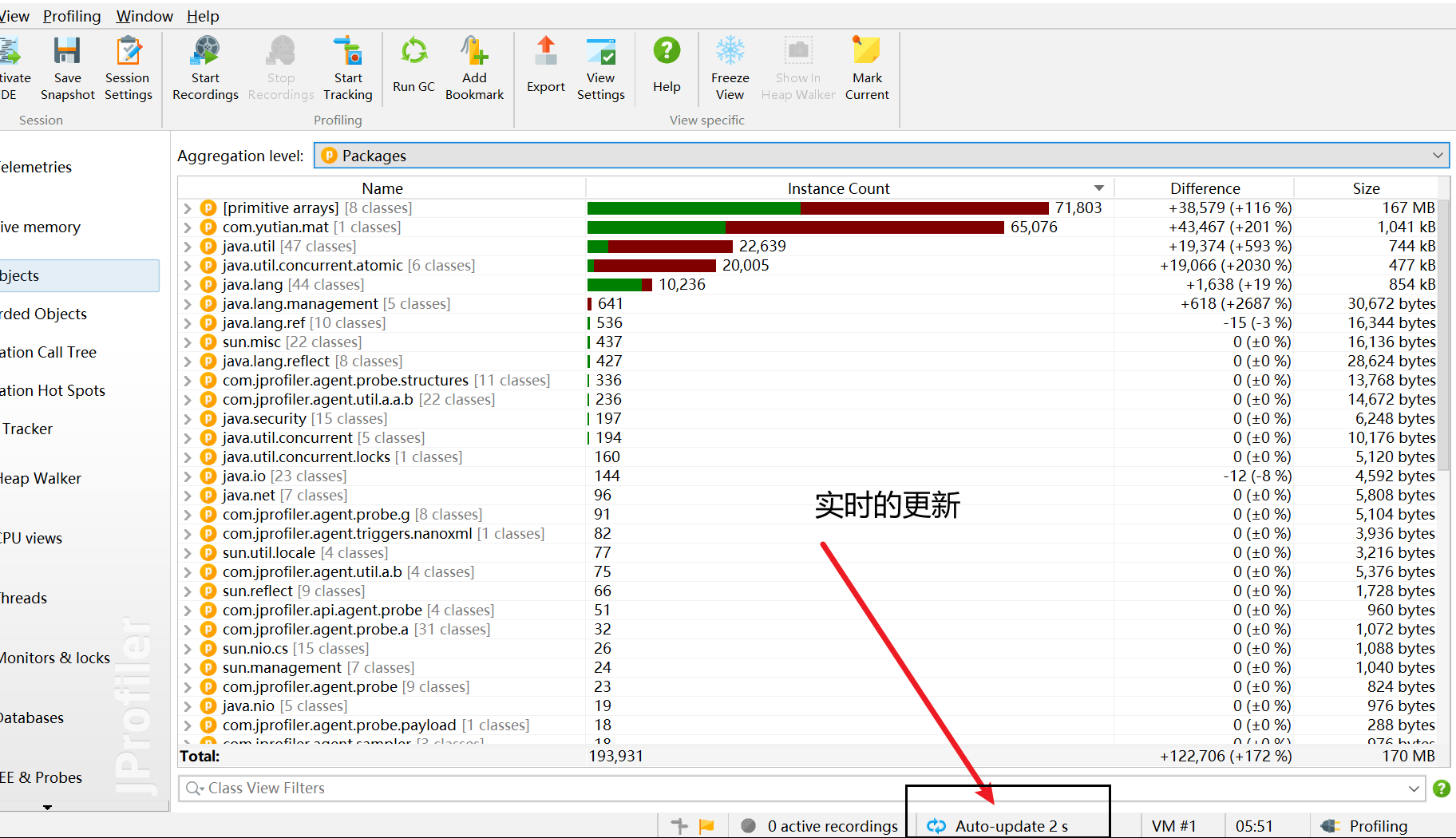
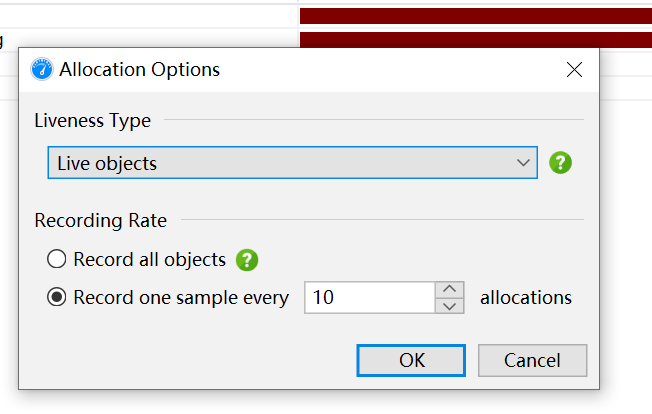
记录对象 Record Objects
查看特定时间段对象的分配,并记录分配的调用堆栈。
注意:开启会影响性能
如图:每次垃圾回收后,剩余对象越来越多,可能存在内存泄漏
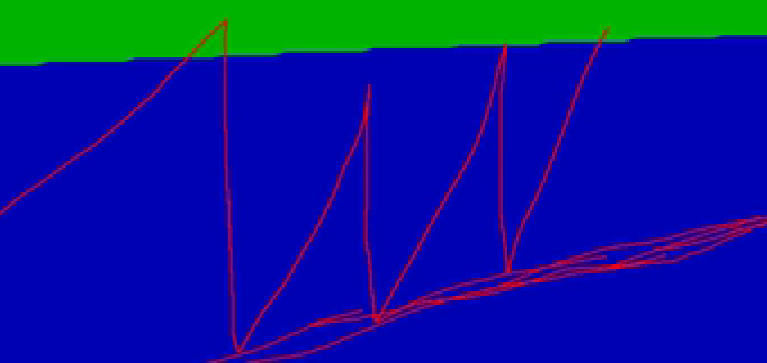
大致意思:
右击
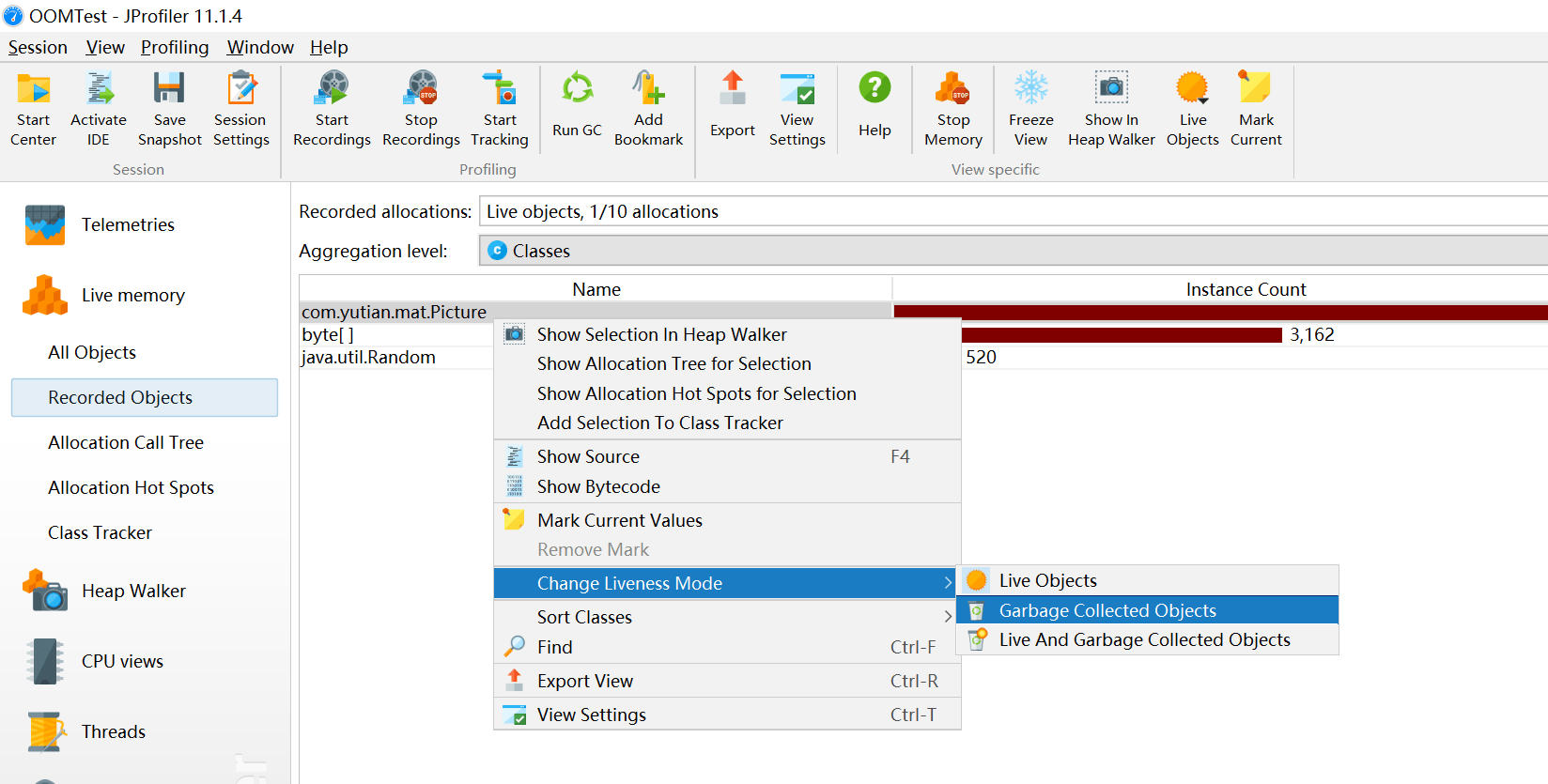
分配访问树Allocation Call Tree
显示一棵请求树或者方法、类、包或对已选择类有带注释的分配信息的J2EE组件
分配热点 Allocation Hot Spots
显示一个列表,包括方法、类、包或分配已选类的J2EE组件。你可以标注当前值并且显示差只值,对于每个热点都可以显示它的跟踪记录树。
类追踪器 Class Tracker
类跟踪视图可以包含任意数量的图表,显示选定的类和包的实例与时间
堆遍历 heap walker
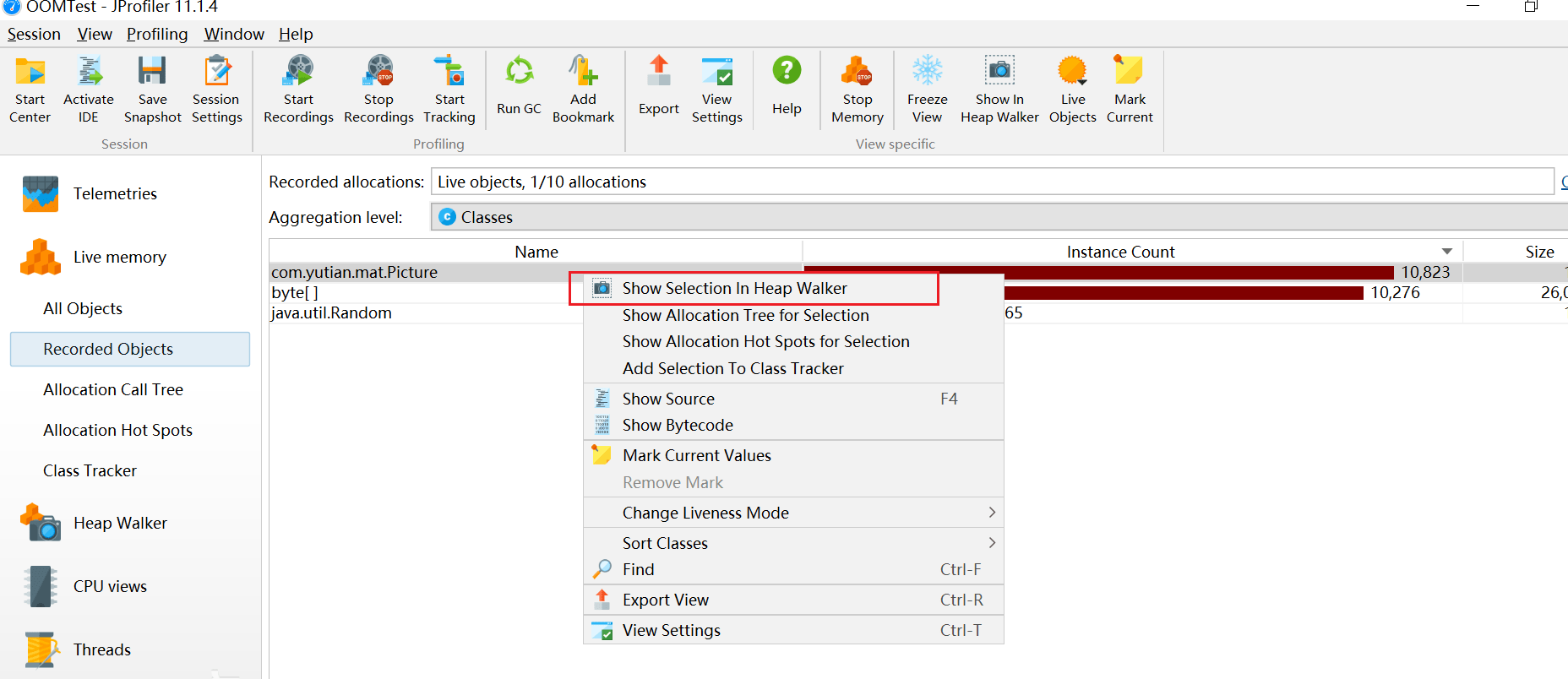
从内存视图 Live Memory里的记录对象 Record Objects,右击怀疑内存泄漏的对象查看堆遍历 heap walker
进入堆遍历 heap walker,后,还可以右击选择引用对象
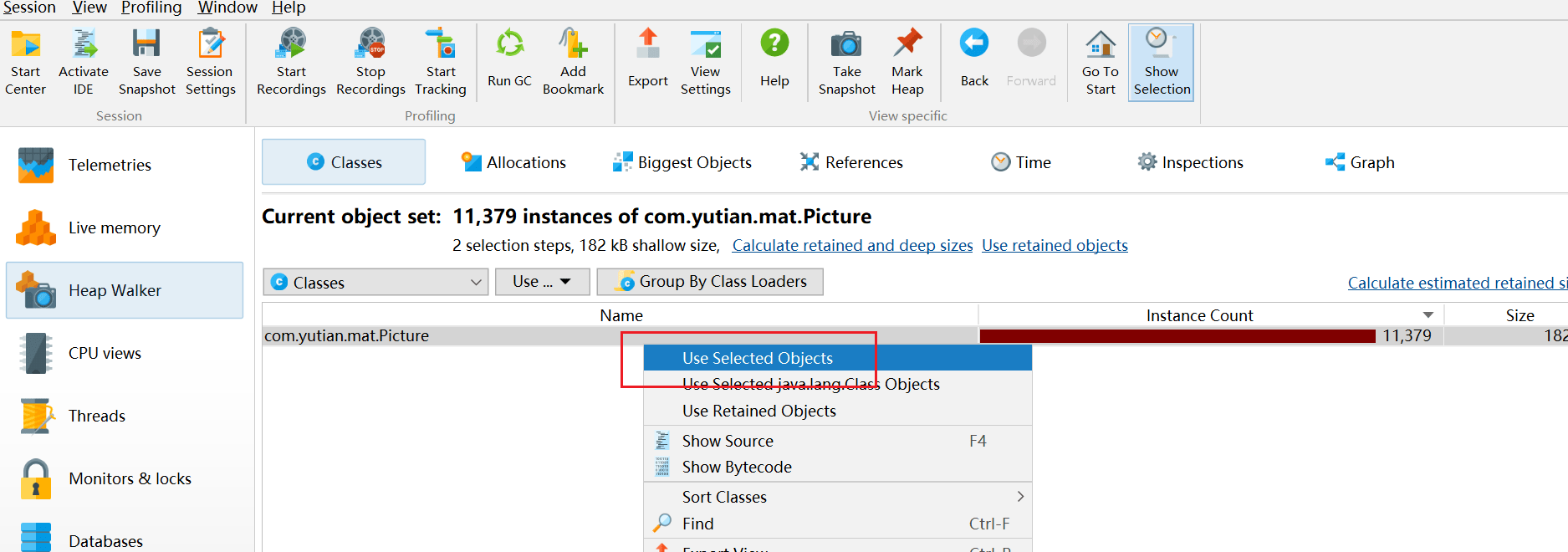
引用视图的视图模式显示了当前对象集中单个实例的传出引用树。您可以导航到引用树中的其他实例。可以查看他引用了谁。
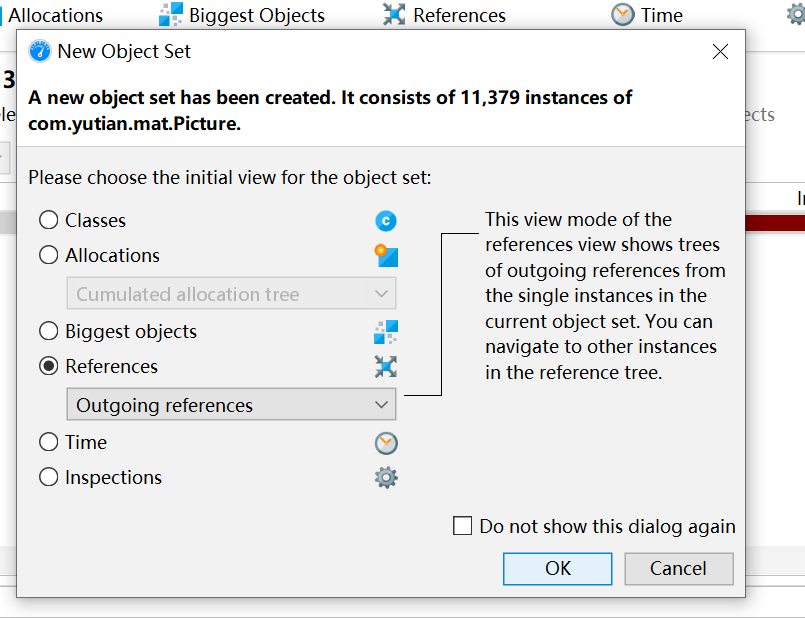
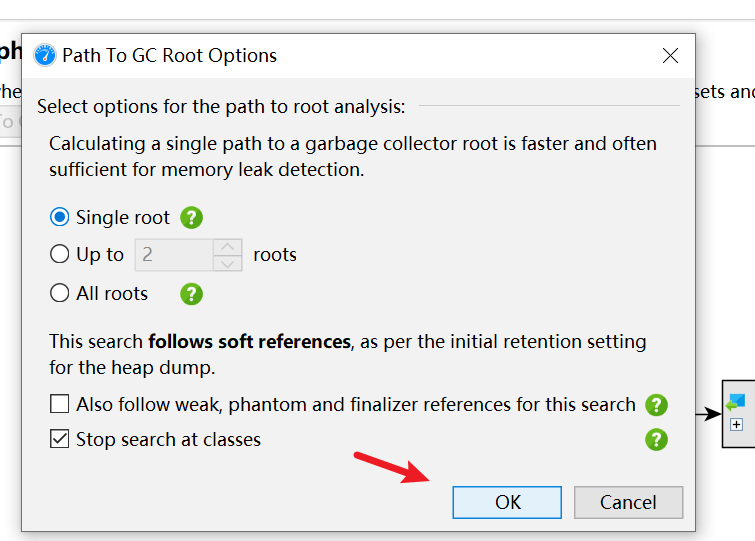
还可以查看GC Root,右击
右击,查看GC Root
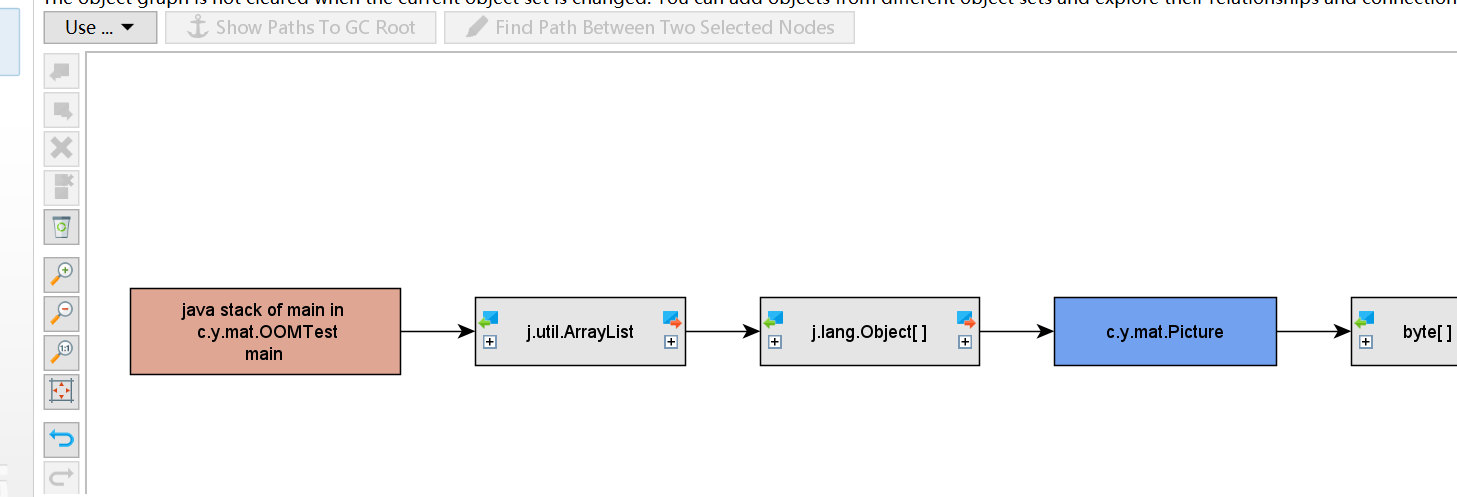
直接使用堆遍历 heap walker
离线查看堆快照
cpu视图 cpu views
我们使用其自带的例子:
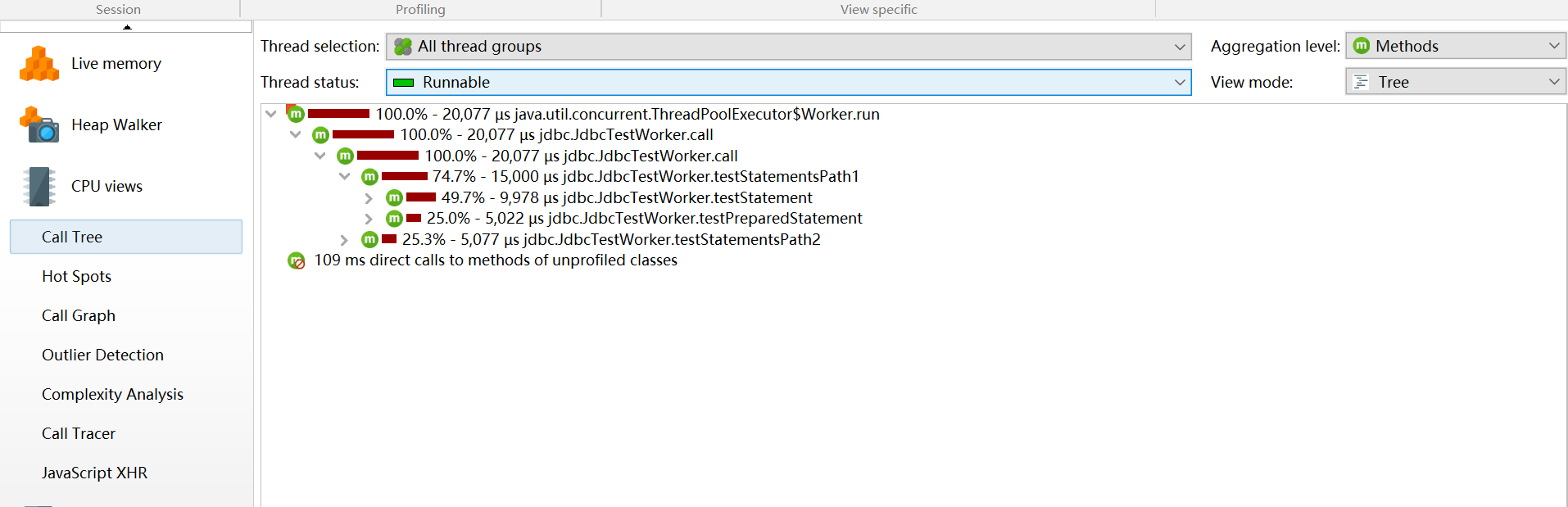
JProfiler提供不同的方法来记录访问树以优化性能和细节。线程或者线程组以及线程状况可以被所有的视图选择。所有的视图都可以聚集到方法、类、包或J2EE组件等不同层上。
访问树 Call Tree
显示一个积累的自顶向下的树,树中包含所有在JVM中己记录的访问队列。JDBC,JMS和JNDI服务请求都被注释在请求树中。请求树可以根据Servlet和JSP对URL的不同需要进行拆分。
方法的执行时间越多,cpu占用越多
还可以查看其他,例如包
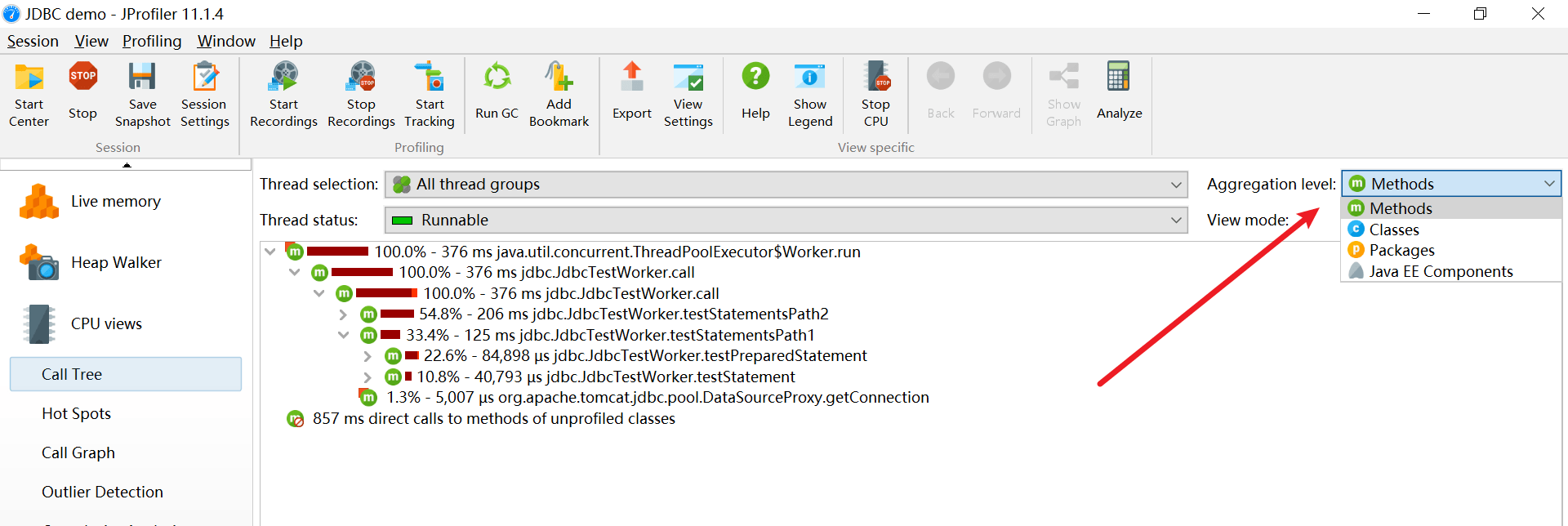
调用情况百分比,执行总的时间,类的完整路径
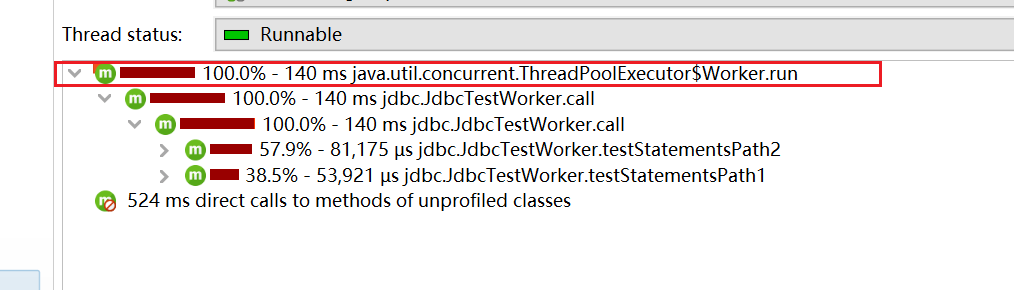
热点Hot Spots
显示消耗时间最多的方法的列表。对每个热点都能够显示回溯树。该热点可以按照方法请求,JDBC,法JMS和JNDI服务请求以及按照URL请求来进行计算。
访问图 Call Graph
显示一个从已选方法、类、包或J2EE组件开始的访问队列的图。
线程视图threads
JProfiler通过对线程历史的监控判断其运行状态,并监控是否有线程阻塞产生,还能将一个线程所管理的方法以树状形式呈现。对线程剖析。
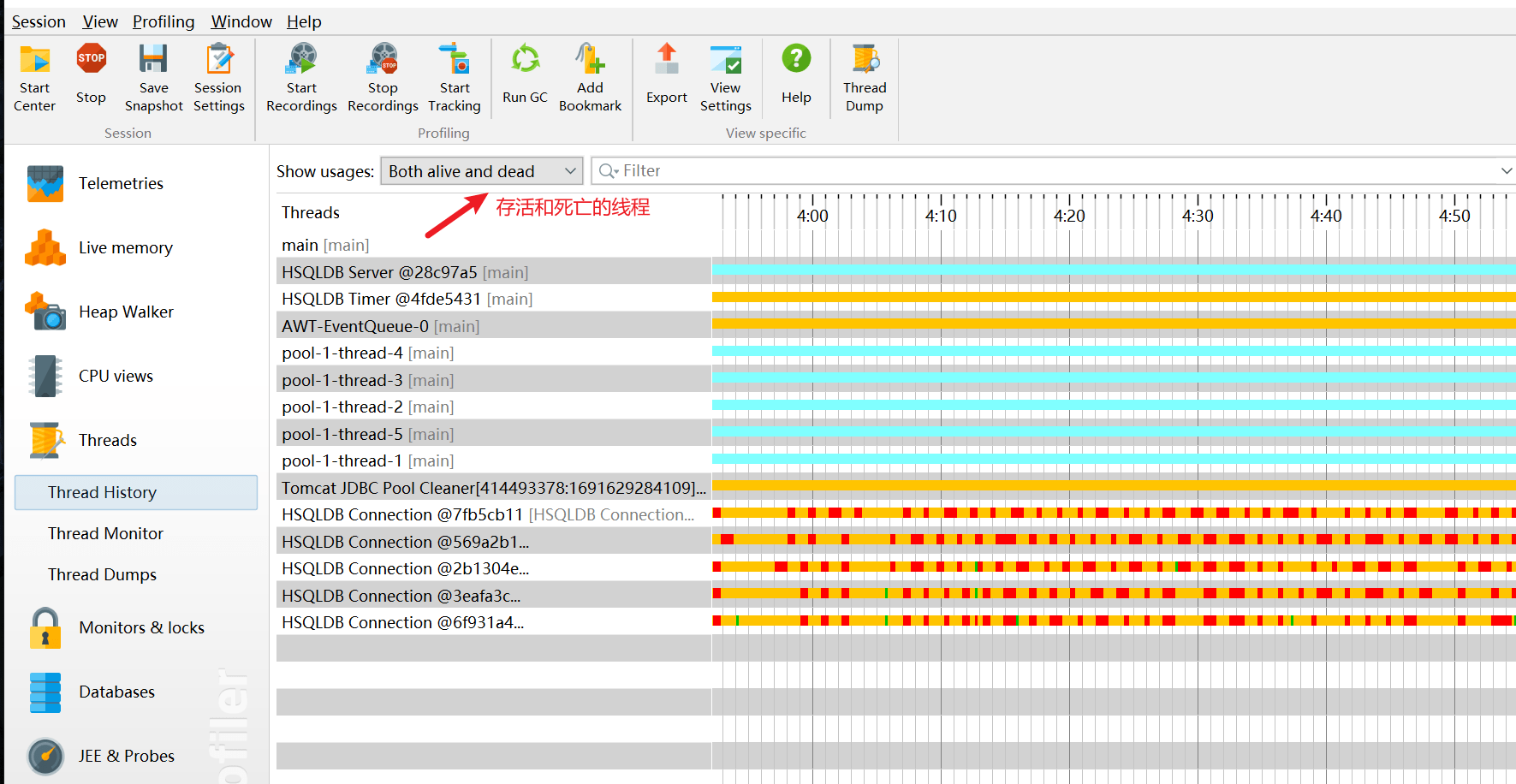
线程历史 Thread History
显示一个与线程活动和线程状态在一起的活动时间表。
线程监控 Thread Monitor
显示一个列表,包括所有的活动线程以及它们目前的活动状况。
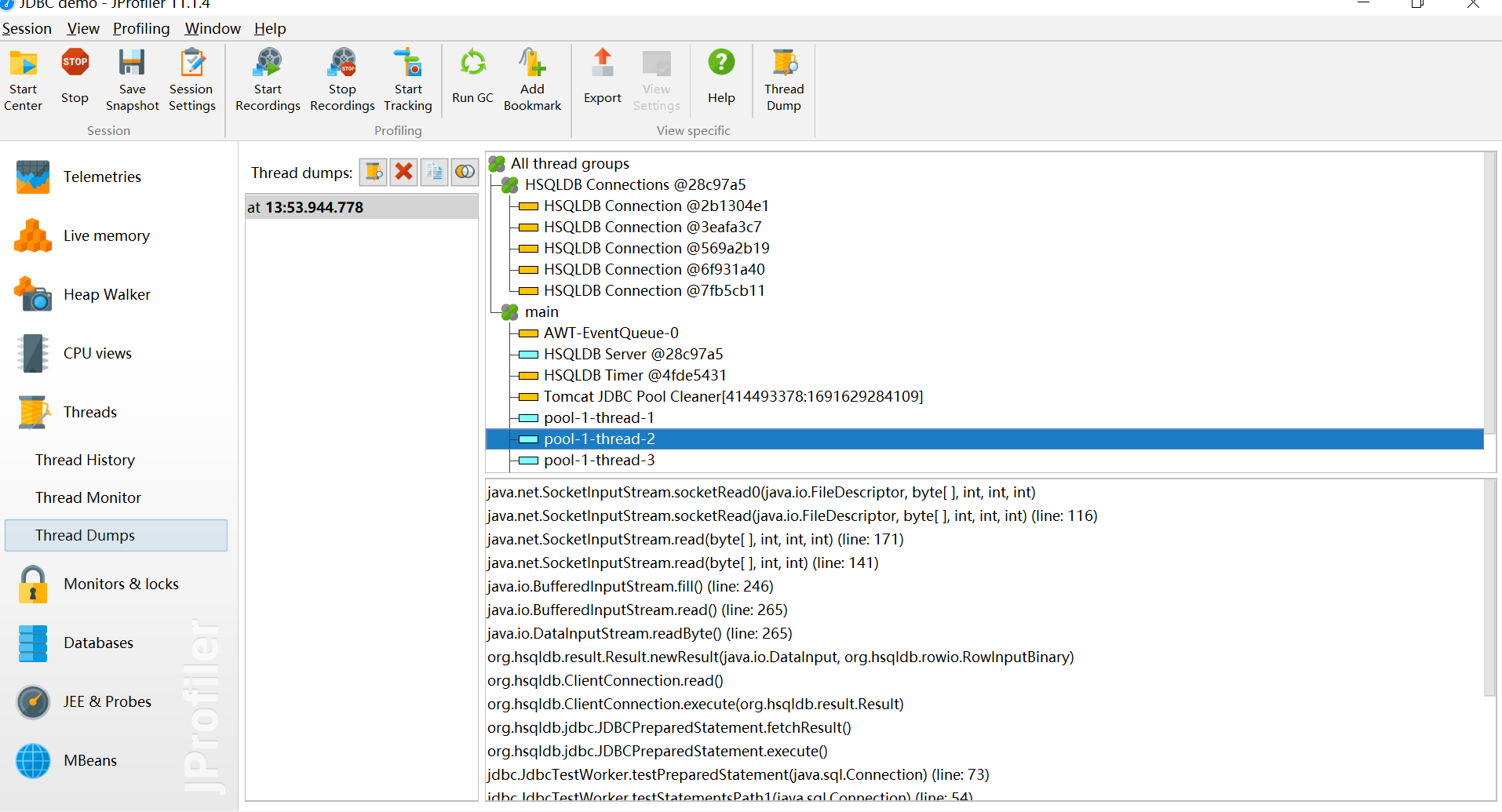
线程转储 Thread Dumps
显示所有线程的堆栈跟踪。
1. web容器的线程最大数。比如: Tomcat的线程容量应该略大于最大并发数。
2. 线程阻塞
3. 线程死锁

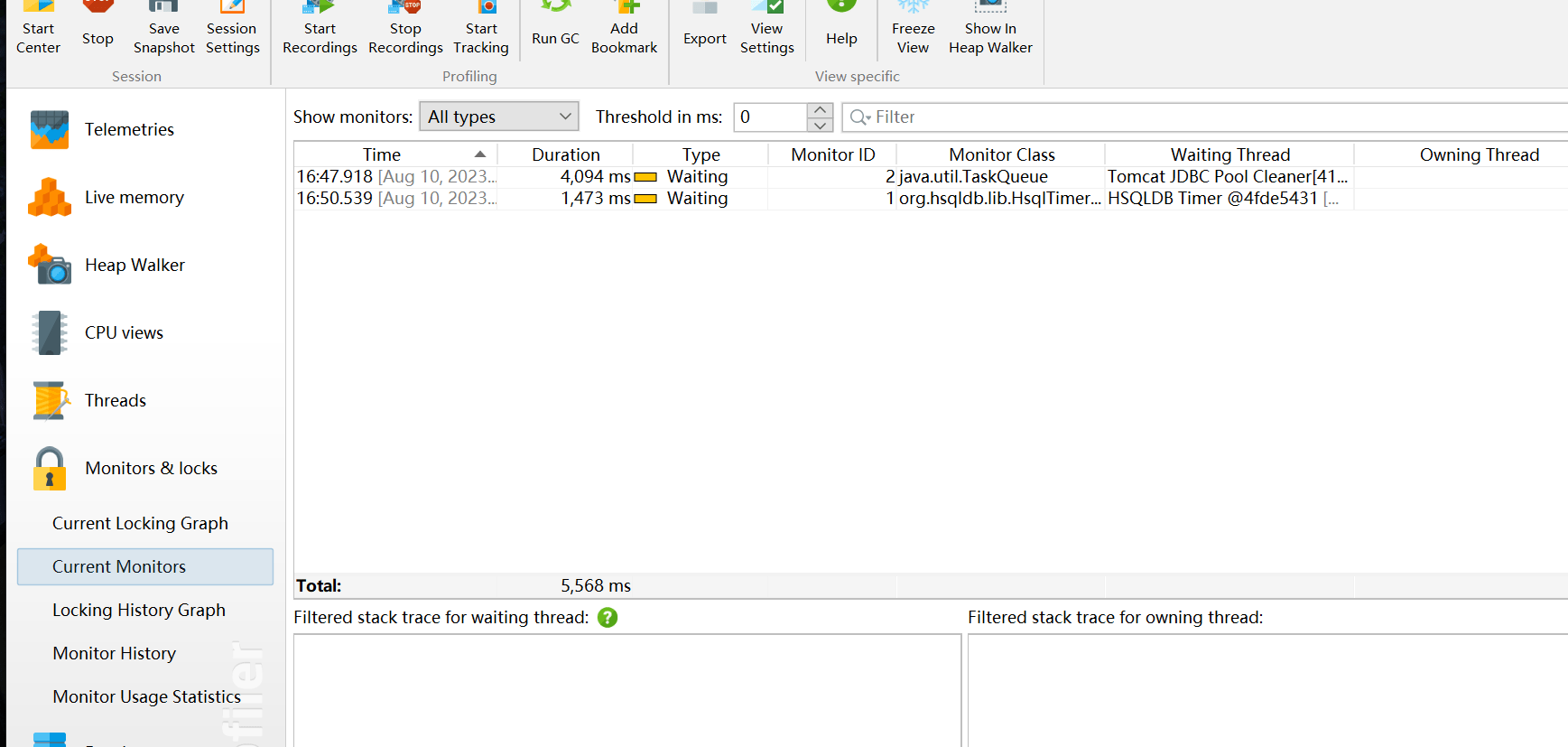
监视器&锁Monitors&locks
监控和锁Monitors & Locks 所有线程持有锁的情况以及锁的信息。
观察JVM的内部线程并查看状态:
- 死锁探测图表 Current Locking Graph :显示JVM中的当前死锁图表。
- 目前使用的监测器 Current Monitors :显示目前使用的监测器并且包括它们的关联线程
- 锁定历史图表 Locking History Graph :显示记录在JVM中的锁定历史。
- 历史检测记录 Monitor History :显示重大的等待事件和阻塞事件的历史记录。
- 监控器使用统计Monitor Usage Statistics :显示分组监测,线程和监测类的统计监测数据
4.案例分析
1.正常情况:
package com.yutian.jprofiler;
import java.util.ArrayList;
import java.util.concurrent.TimeUnit;
/**
* 功能演示测试
*/
public class JProfilerTest {
public static void main(String[] args) {
while (true){
ArrayList list = new ArrayList();
for (int i = 0; i < 500; i++) {
Data data = new Data();
list.add(data);
}
try {
TimeUnit.MILLISECONDS.sleep(500);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
class Data{
private int size = 10;
private byte[] buffer = new byte[1024 * 1024];//1mb
private String info = "hello,崩坏三";
}
2.内存泄漏:
package com.yutian.jprofiler;
import java.util.ArrayList;
import java.util.concurrent.TimeUnit;
public class MemoryLeak {
public static void main(String[] args) {
while (true) {
ArrayList beanList = new ArrayList();
for (int i = 0; i < 500; i++) {
Bean data = new Bean();
data.list.add(new byte[1024 * 10]);//10kb
beanList.add(data);
}
try {
TimeUnit.MILLISECONDS.sleep(500);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
class Bean {
int size = 10;
String info = "hello,崩坏三";
//ArrayList list = new ArrayList();
static ArrayList list = new ArrayList();
}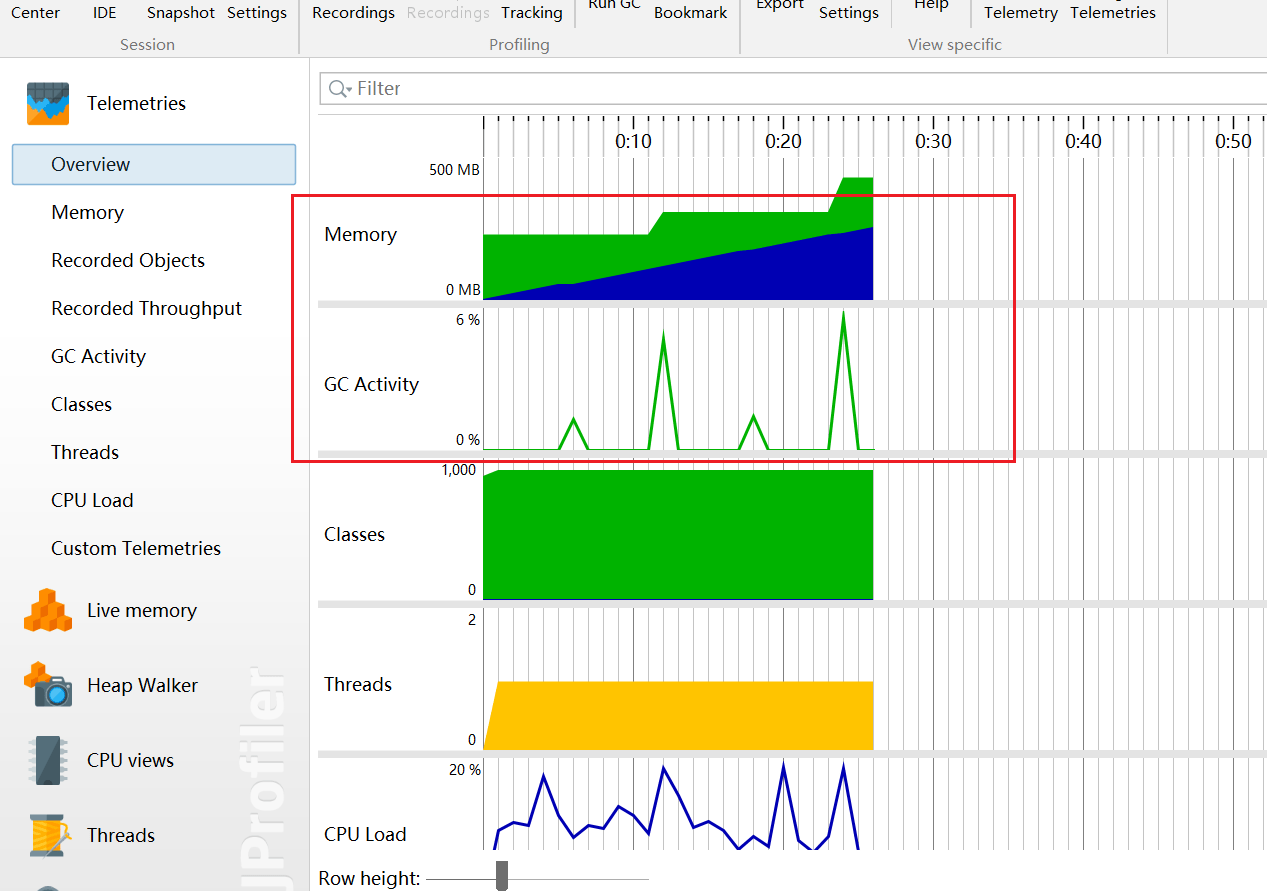
GC回收不了
关联对象
6.Arthas
背景
前面,我们介绍了idk自带的jvisualvm等免费工具,以及商业化工具Jprofiler
这两款工具在业界知名度也比较高,他们的优点是可以图形界面上看到各维度的性能数据,使用者根据这些数据进行综合分析,然后判断哪里出现了性能问题。
但是这两款工具也有个缺点,都必须在服务端项目进程中配置相关的监控参数。然后工具通过远程连接到项目进程,获取相关的数据。这样就会带来一些不便,比如线上环境的网络是隔离的,本地的监控工具根本连不上线上环境。并且类似于Jprofiler这样的商业工具,是需要付费的。那么有没有一款工具不需要远程连接,也不需要配置监控参数,同时也提供了丰富的性能监控数据呢?今天跟大家介绍一款阿里巴巴开源的性能分析神器Arthas(阿尔萨斯)
概述:
Arthas (阿尔萨斯) 是Alibaba开源的Java诊断工具,深受开发者喜爱。在线排查问题,无需重启:动态跟踪Java代码:实时监控JVM状态。
Arthas 支持JDK 6+,支持Linux/Mac/Windows,采用命令行交互模式,同时提供丰富的 Tab 自动补全功能,进一步方便进行问题的定位和诊断。
当你遇到以下类似问题而束手无策时,Arthas可以帮助你解决:
- 这个类从哪个 jar 包加载的?为什么会报各种类相关的 Exception?
- 我改的代码为什么没有执行到?难道是我没 commit?分支搞错了?
- 遇到问题无法在线上 debug,难道只能通过加日志再重新发布吗?
- 线上遇到某个用户的数据处理有问题,但线上同样无法 debug,线下无法重现!
- 是否有一个全局视角来查看系统的运行状况?
- 有什么办法可以监控到JVM的实时运行状态?
基于哪些工具开发而来:
- greys-anatomy: Arthas代码基于Greys二次开发而来,非常感谢Greys之前所有的工作,以及Greys原作者对Arthas提出的意见和建议!
- termd: Arthas的命令行实现基于termd开发,是一款优秀的命令行程序开发框架,感谢termd提供了优秀的框架。
- crash: Arthas的文本渲染功能基于crash中的文本渲染功能开发,可以从这里看到源码,感谢crash在这方面所做的优秀工作。
- cli: Arthas的命令行界面基于vert.x提供的cli库进行开发,感谢vert.x在这方面做的优秀工作。
- compiler Arthas里的内存編绎器代码来源
- Apache Commons Net Arthas里的Telnet Client代码来源
- JavaAgent:运行在main方法之前的拦截器,它内定的方法名叫premain ,也就是说先执行premain 方法然后再执行 main 方法
- ASM:一个通用的Java字节码操作和分析框架。它可以用于修改现有的类或直接以二进制形式动态生成类。ASM提供了一些常见的字节码转换和分析算法,可以从它们构建定制的复杂转换和代码分析工具,ASM提供了与其他Java字节码框架类似的功能,但是主要关注性能,因为它被设计和实现得尽可能小和快,所以非常适合在动态系统中使用(当然也可以以静态方式使用,倒如在编译器中)
官方便用文档:
安装与使用
wget https://alibaba.github.io/arthas/arthas-boot.jar
ls -l
启动:
Arthas 只是一个 java 程序,所以可以直接用 java -jar 运行。
执行成功后, arthas提供了一种命令行方式的交互方式, arthas会检测当前服务器上的Java进程,并将进程列表展示出来,用户输入对应的编号(1、2、3、4…)进行选择,然后回车。
比如:
方式1:
java -jar arthas-boot.jar
方式2:
运行时选择Java进程PID
java -jar arthas-boot.jar [PID]
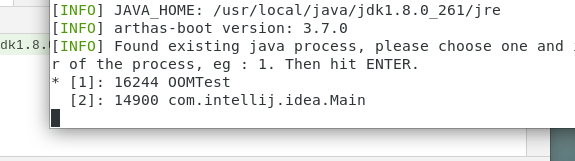
为了测试方便,把idea下载在linux中,同时启动之前的代码OOMTest
运行后:
再运行Arthas
java -jar arthas-boot.jar
第一次启动,会慢,稍等
选择1,回车
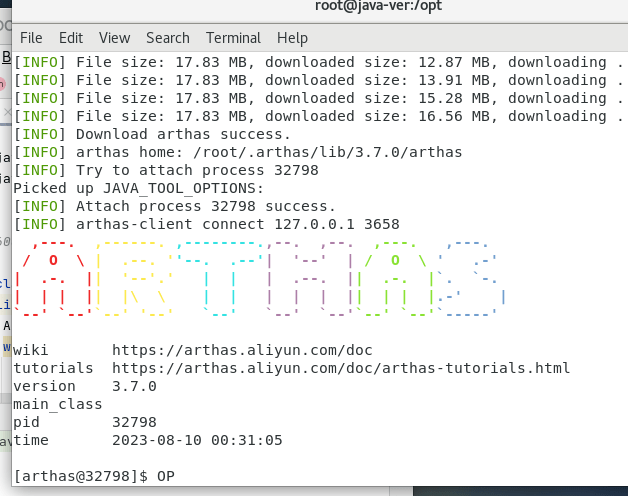
除了在命令行查看外, Arthas目前还支持Web Console.在成功启动连接进程之后就已经自动启动,可以直接访问http://127.0.9.1:8563/访问,页面上的操作模式和控制台完全一样。
相关:
最后一行[arthas@7457]$,说明打开进入了监控客户端,在这里就可以执行相关命令进行查看了。
- 使用quit\exit:退出当前客户端
- 使用stop\shutdown:关闭arthas服务端,并退出所有客户端。
- 查看日志cat -/logs/arthas/arthas.log
- 参看帮助java -jar arthas-boot.jar -h
相关诊断指令
官网很详细,推荐去官网学习:
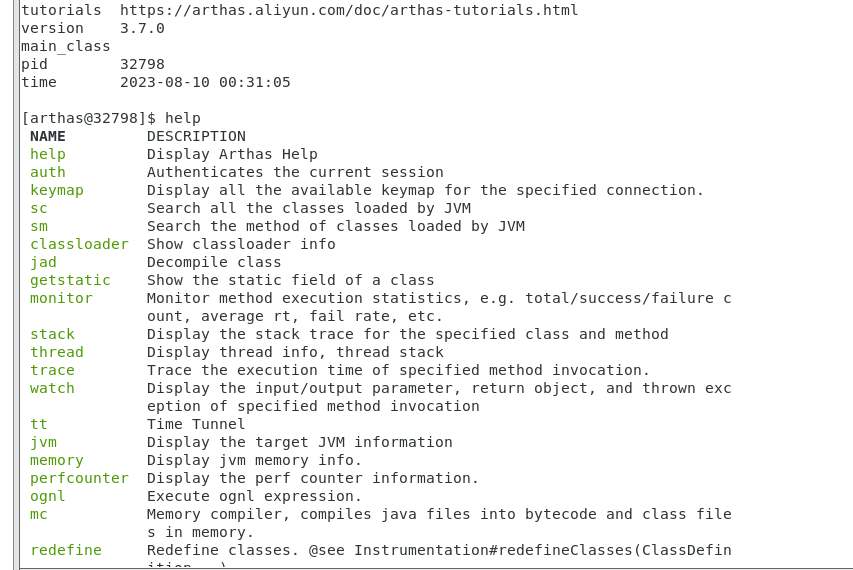
基础指令:
- help——查看命令帮助信息
- cat——打印文件内容,和linux里的cat命令类似
- echo——打印参数,和linux里的echo命令类似
- grep——匹配查找,和linux里的grep命令类似
- tee——复制标准输入到标准输出和指定的文件,和linux里的tee命令类似
- pwd——返回当前的工作目录,和linux命令类似
- cls——清空当前屏幕区域
- session——查看当前会话的信息
- reset——重置增强类,将被 Arthas 增强过的类全部还原, Arthas服务端关闭时会重置所有增强过的类
- version—-输出当前目标Java进程所加载的 Arthas 版本号
- history——打印命令历史
- quit——退出当前 Arthas 客户端,其他 Arthas 客户端不受影响
- stop——关闭 Arthas 服务端,所有 Arthas 客户端全部退出
- keymap——Arthas快捷键列表及自定义快捷键
如:
jvm相关:
- dashboard – 当前系统的实时数据面板
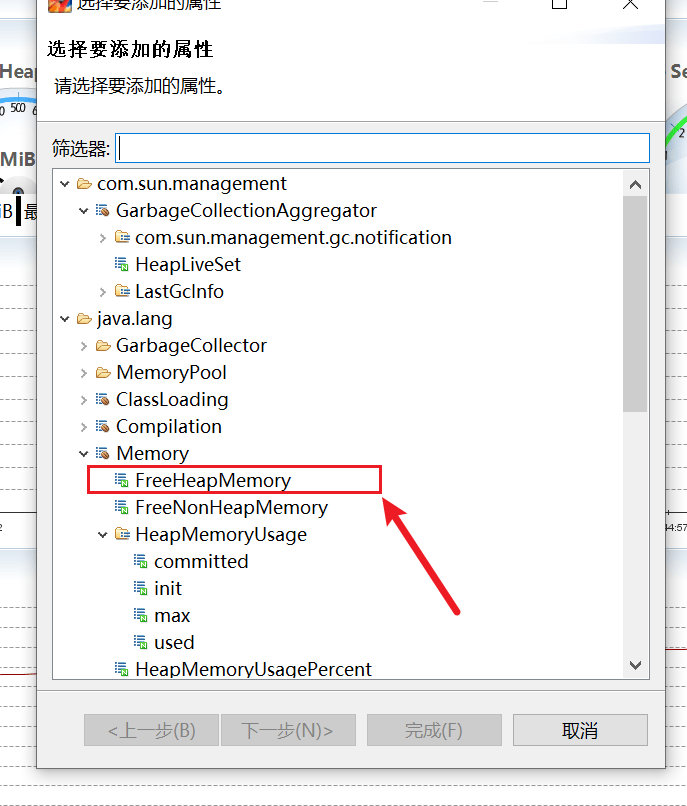
- getstatic – 查看类的静态属性
- heapdump – dump java heap, 类似 jmap 命令的 heap dump 功能
- jvm – 查看当前 JVM 的信息
- logger – 查看和修改 logger
- mbean – 查看 Mbean 的信息
- memory – 查看 JVM 的内存信息
- ognl – 执行 ognl 表达式
- perfcounter – 查看当前 JVM 的 Perf Counter 信息
- sysenv – 查看 JVM 的环境变量
- sysprop – 查看和修改 JVM 的系统属性
- thread – 查看当前 JVM 的线程堆栈信息
- vmoption – 查看和修改 JVM 里诊断相关的 option
- vmtool – 从 jvm 里查询对象,执行 forceGc
dashboard:当前系统的实时数据面板,按 ctrl+c 退出。
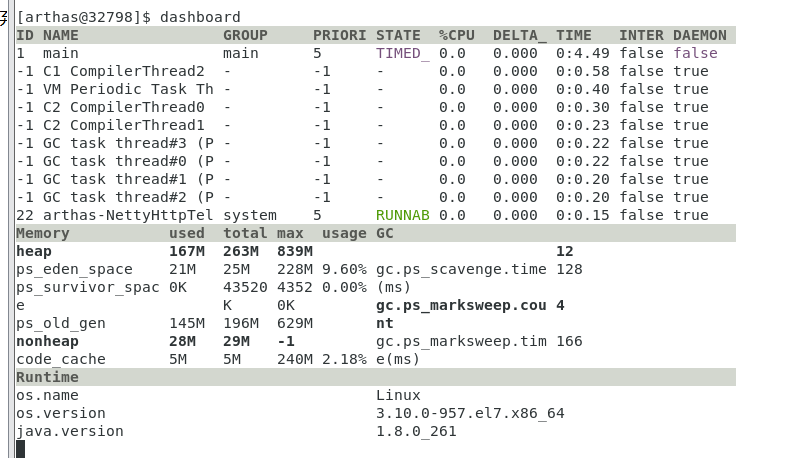
- ID: Java 级别的线程 ID,注意这个 ID 不能跟 jstack 中的 nativeID 一一对应。
- NAME: 线程名
- GROUP: 线程组名
- PRIORITY: 线程优先级, 1~10 之间的数字,越大表示优先级越高
- STATE: 线程的状态
- CPU%: 线程的 cpu 使用率。比如采样间隔 1000ms,某个线程的增量 cpu 时间为 100ms,则 cpu 使用率=100/1000=10%
- DELTA_TIME: 上次采样之后线程运行增量 CPU 时间,数据格式为
秒 - TIME: 线程运行总 CPU 时间,数据格式为
分:秒 - INTERRUPTED: 线程当前的中断位状态
- DAEMON: 是否是 daemon 线程
1000毫秒打印一次
dashboard -i 1000
共打印一次
dashboard -n 4
thread:
查看当前线程信息,查看线程的堆栈
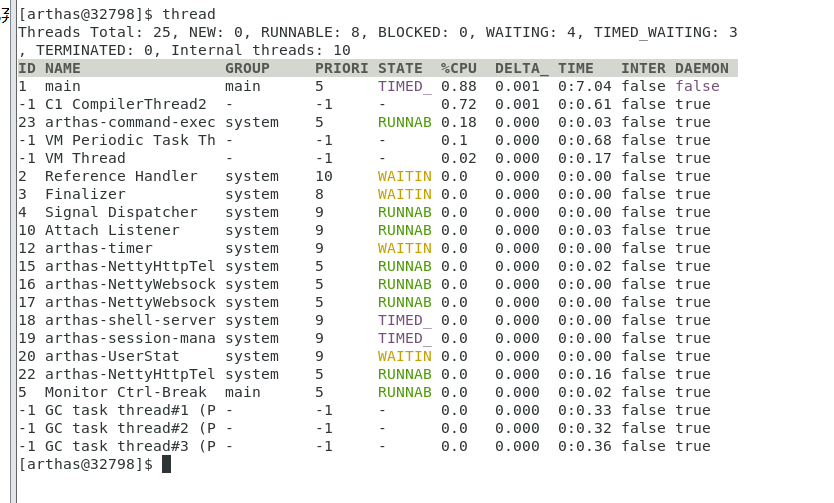
查看ID为1的线程:
thread 1
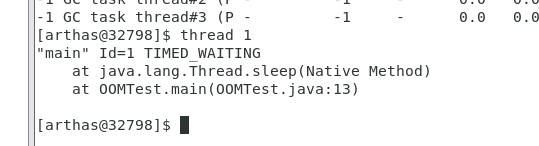
找出当前阻塞其他线程的线程
thread -b
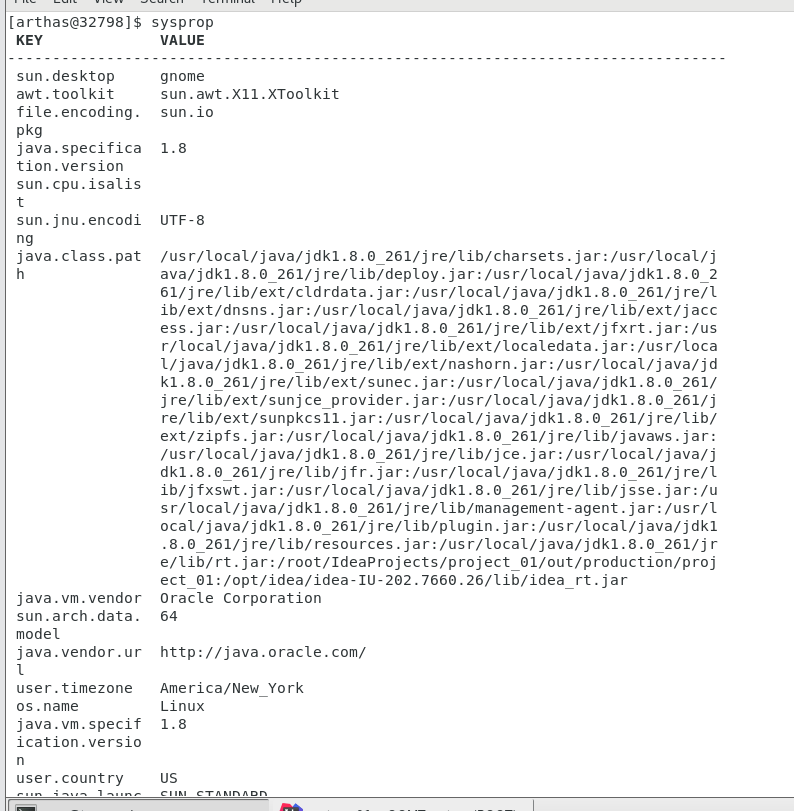
sysprop:
查看当前 JVM 的系统属性
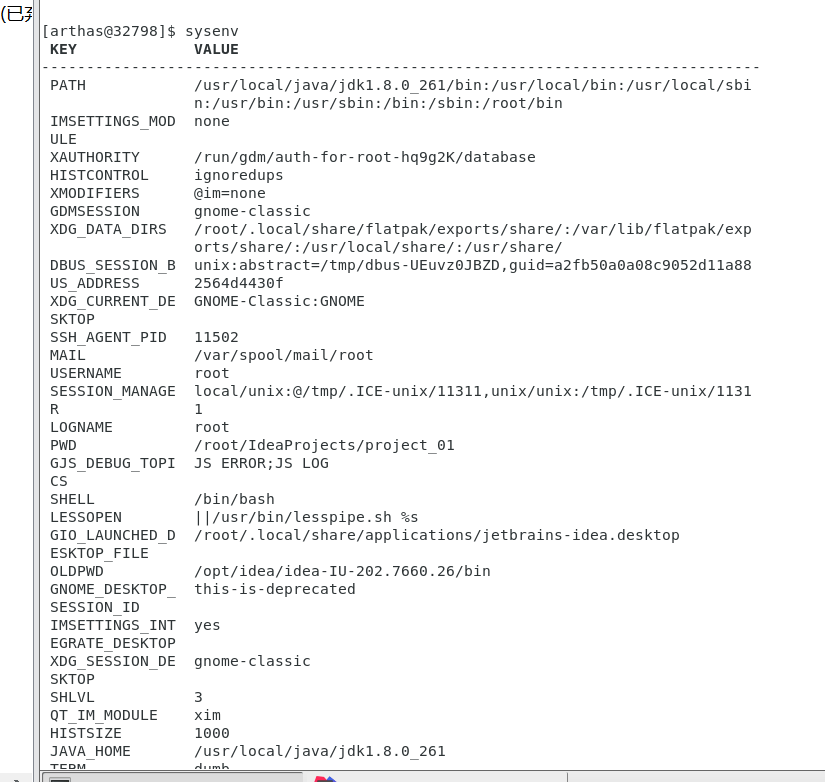
sysenv:
查看当前 JVM 的环境属性
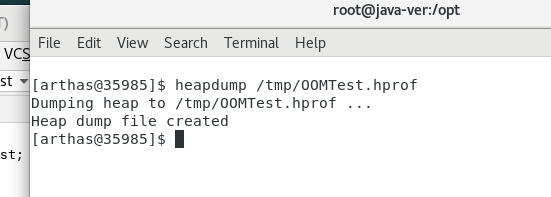
heapdump:
heapdump /tmp/dumpwj/OOMTest.hprof
heapdump --live /tmp/OOMTest.hprof
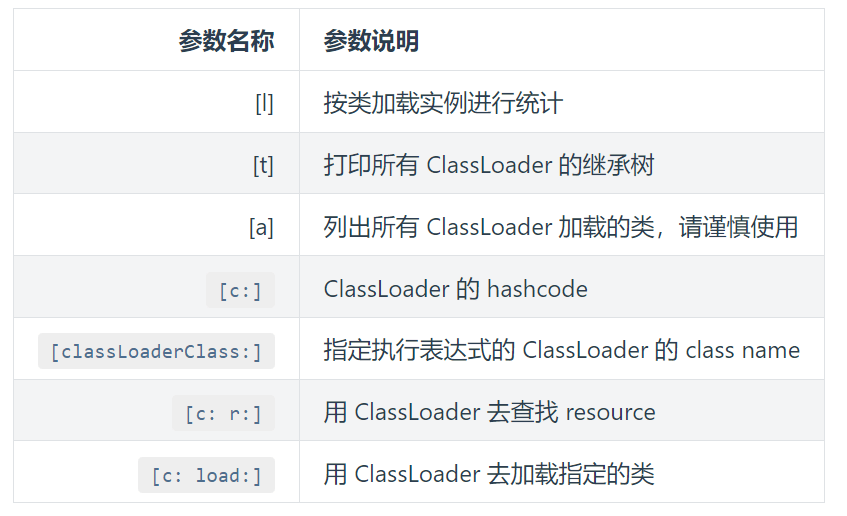
class/classloader 相关
- classloader – 查看 classloader 的继承树,urls,类加载信息,使用 classloader 去 getResource
- dump – dump 已加载类的 byte code 到特定目录
- jad – 反编译指定已加载类的源码
- mc – 内存编译器,内存编译
.java文件为.class文件 - redefine – 加载外部的
.class文件,redefine 到 JVM 里 - retransform – 加载外部的
.class文件,retransform 到 JVM 里 - sc – 查看 JVM 已加载的类信息
- sm – 查看已加载类的方法信息
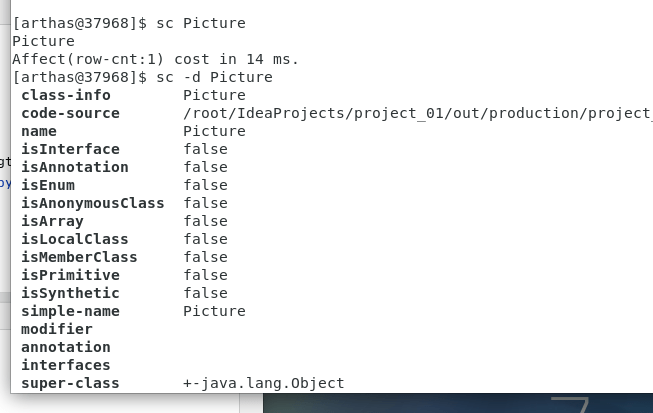
sc:
查看 JVM 已加载的类信息
查看类
sc 全类名
输出当前类的详细信息,包括这个类所加载的原始文件来源、类的声明、加载的 ClassLoader 等详细信息。
sc -d 全类名
注意,是全类名,下图只是刚好没有包名而已
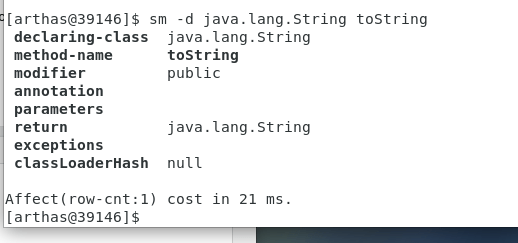
sm :查看已加载类的方法信息

-d 展示每个方法的详细信息
sm -d java.lang.String toString
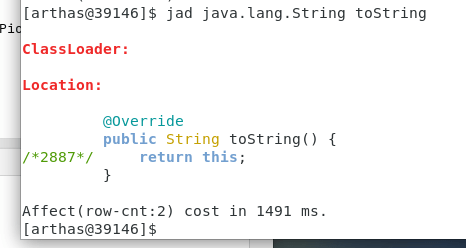
jad:反编译指定已加载类的源码
jad java.lang.String toString
mc:Memory Compiler/内存编译器,编译.java文件生成.class。
mc /tmp/Test.java
redefine(推荐使用 retransform 命令)加载外部的.class文件,redefine jvm 已加载的类
redefine /tmp/Test.class
classloader:查看 classloader 的继承树,urls,类加载信息
classloader
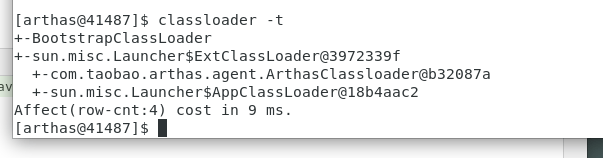
monitor/watch/trace 相关
- monitor – 方法执行监控
- stack – 输出当前方法被调用的调用路径
- trace – 方法内部调用路径,并输出方法路径上的每个节点上耗时
- tt – 方法执行数据的时空隧道,记录下指定方法每次调用的入参和返回信息,并能对这些不同的时间下调用进行观测
- watch – 方法执行数据观测
monitor命令:
- 方法执行监控对匹配 class-pattern /method-pattern的类、方法的调用进行监控。涉及方法的调用次数、执行时间、失败率等
- monitor 命令是一个非实时返回命令
常用参数:
- class-pattern 类名表达式匹配
- method-pattern 方法名表达式匹配
- -c统计周期,默认值为120秒

watch:
观察函数调用返回时的参数、this 对象和返回值:
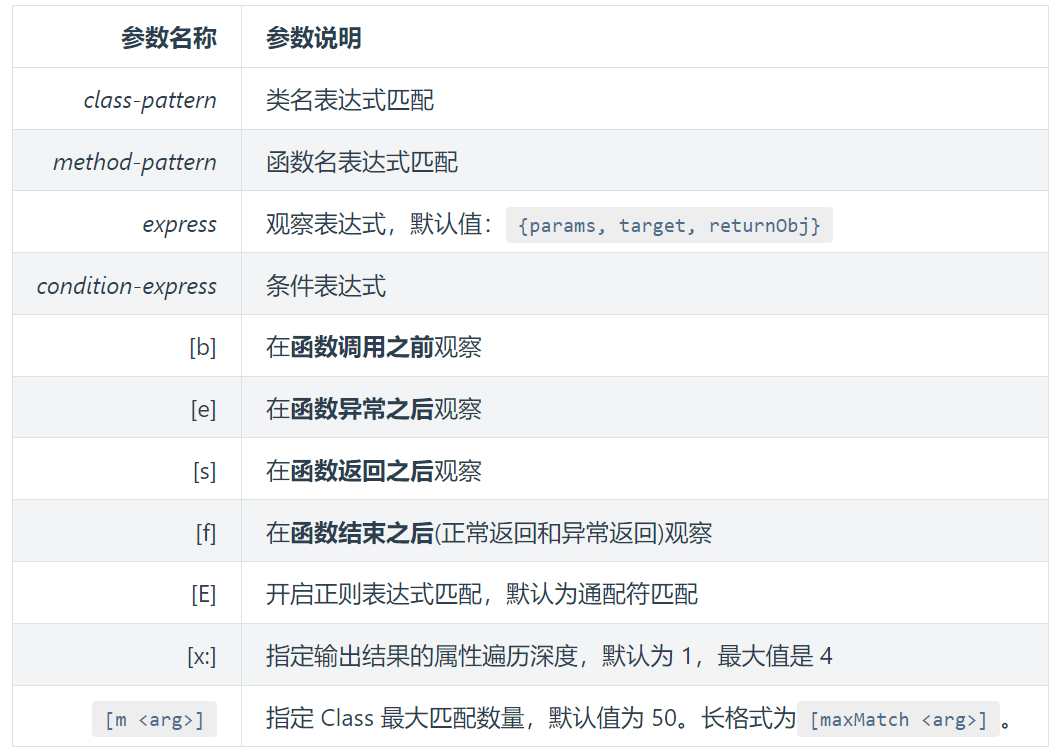
watch Picture <init> "{params,returnObj}" -x 2
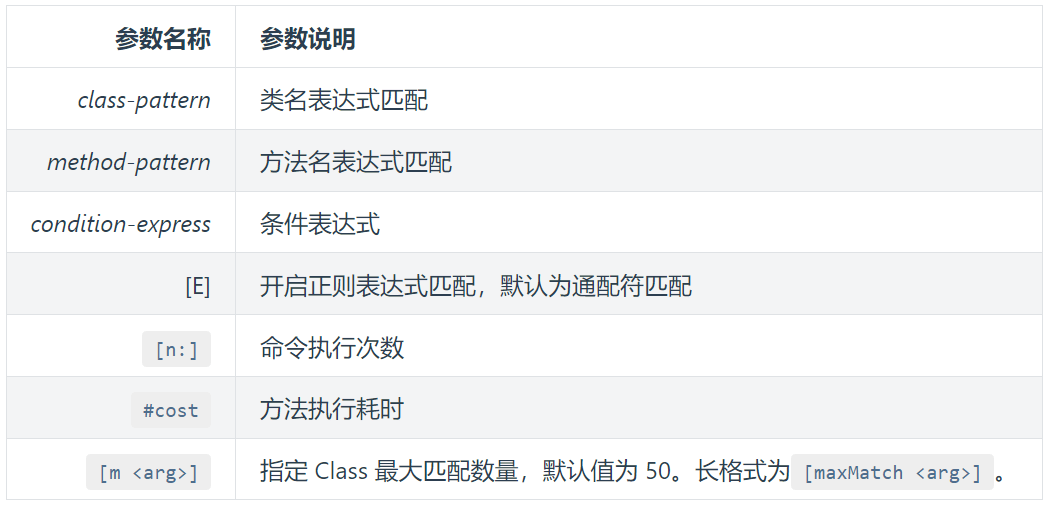
trace命令:
方法内部调用路径,并输出方法路径上的每个节点上耗时
补充说明:
- trace命令能主动搜索class-pattern/method-pattern对应的方法调用路径,渲染和统计整个调用链路上的所有性能开销和追踪调用链路。
- trace能方便的帮助你定位和发现因RT高而导致的性能问题缺陷,但其每次只能跟踪一级方法的调用链路
- trace在执行的过程中本身是会有一定的性能开销,在统计的报告中并未像JProfiler一样预先减去其自身的统计开销。所以这统计出来有些许的不准,渲染路径上调用的类、方法越多,性能偏差越大。但还是能让你看清一些事情的。

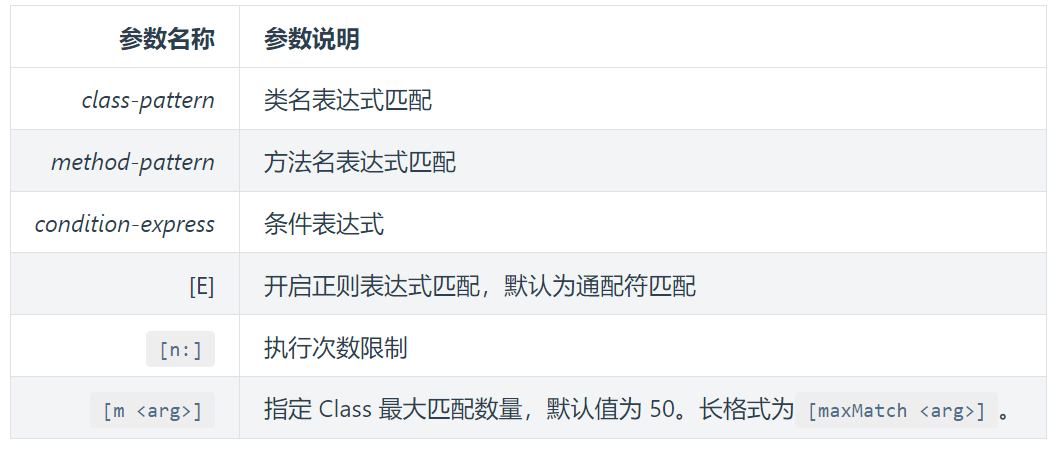
stack命令:
输出当前方法被调用的调用路径

profiler生成火焰图:
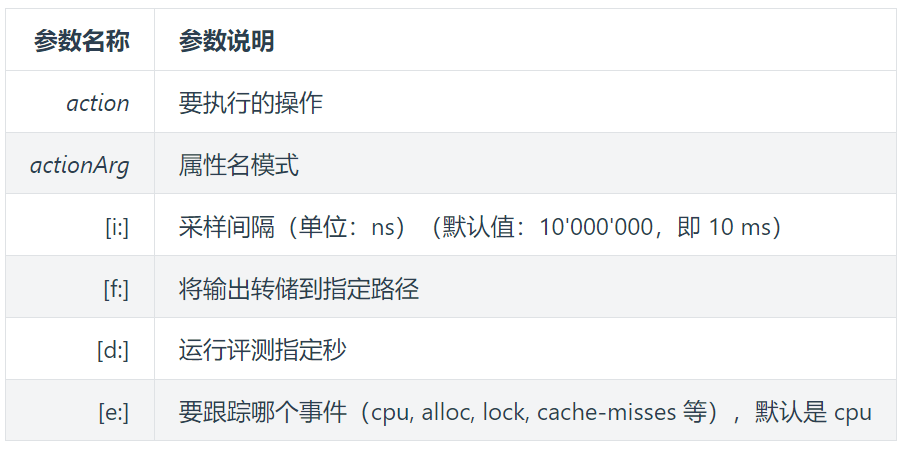
启动 profiler
profiler start
获取已采集的 sample 的数量
profiler getSamples
获取已采集的 sample 的数量
profiler status

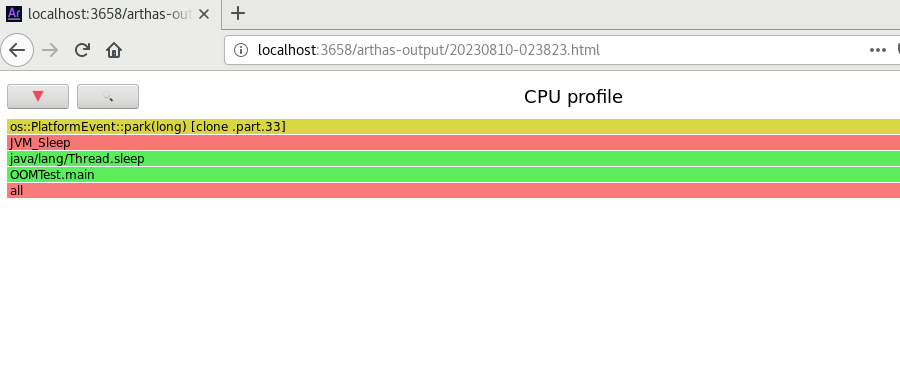
生成火焰图,生成 html 格式结果
profiler stop --format html
通过浏览器查看 arthas-output 下面的 profiler 结果
http://localhost:3658/arthas-output/
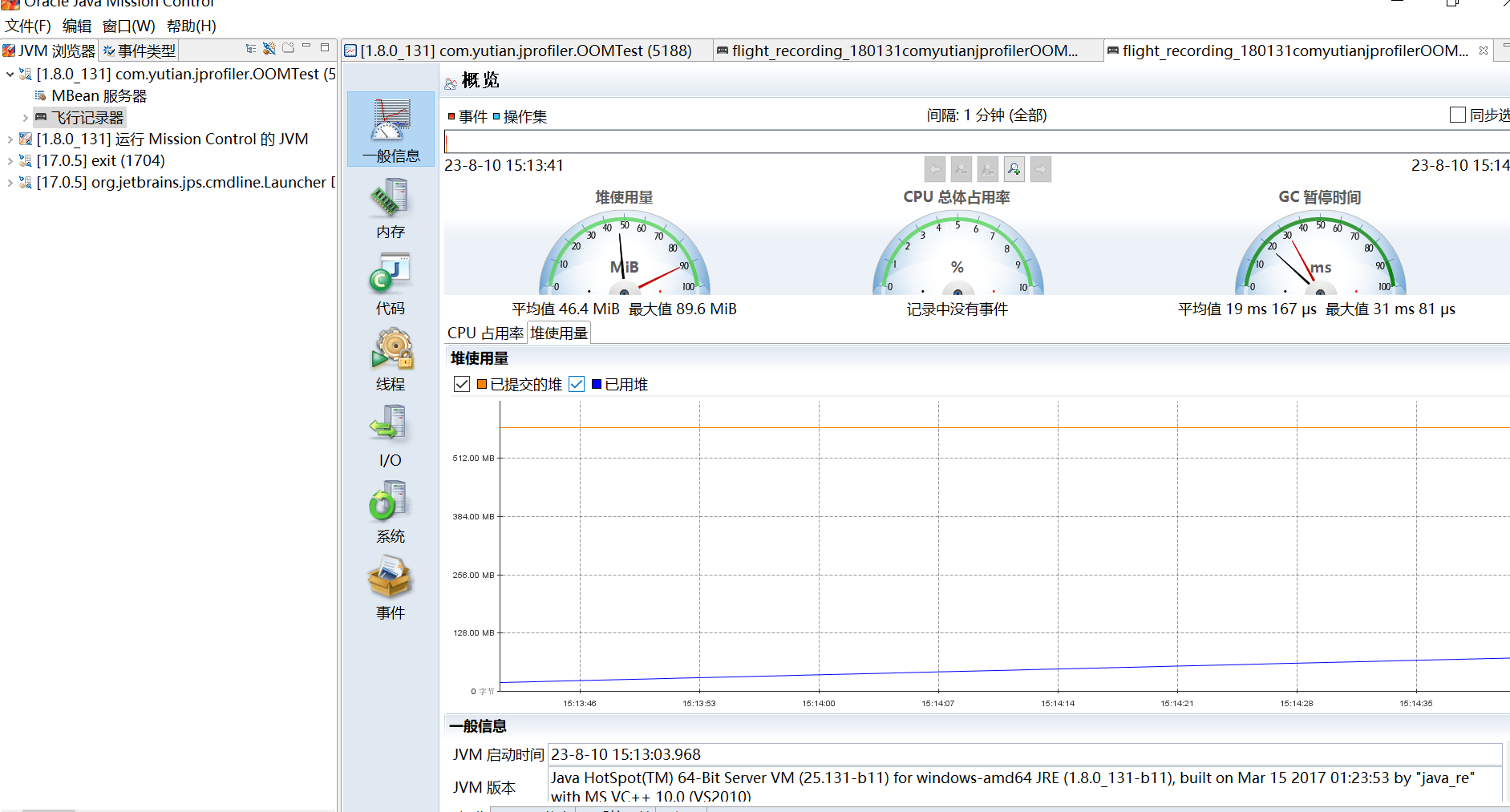
7.Java Mission Control
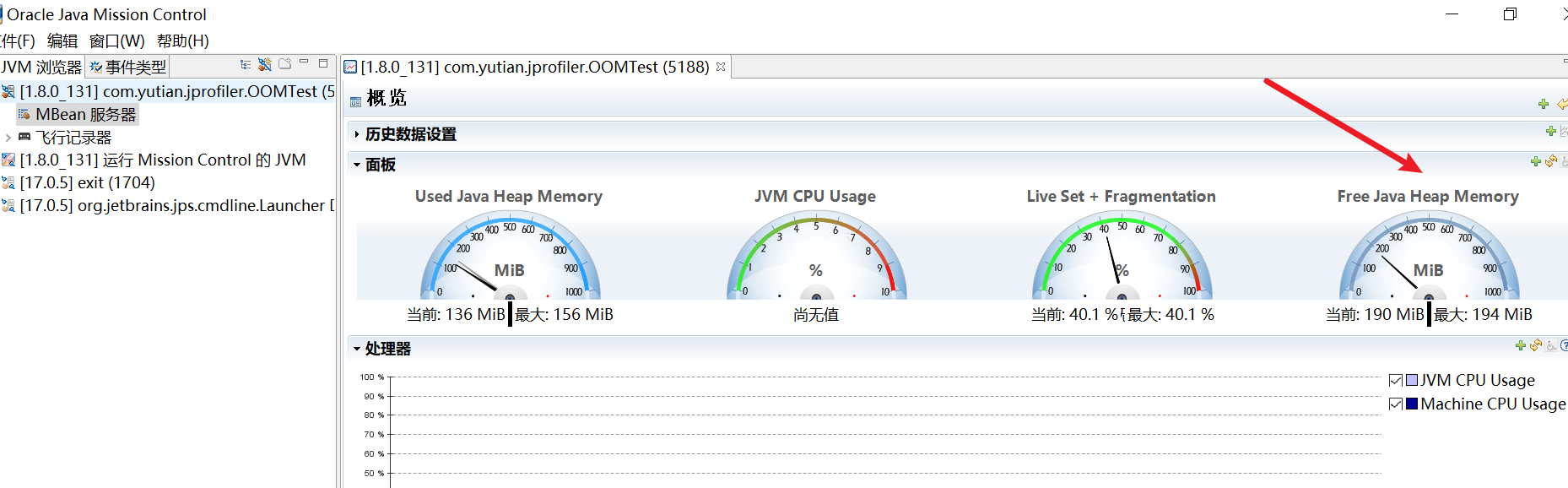
Java Mission Control (简称JMC) ,Java官方提供的性能强劲的工具。是一个用于对Java应用程序进行管理、监视、概要分析和故障排除的工具套件。
它包含一个GUI客户端,以及众多用来收集Java虚拟机性能数据的插件,如JMXConsole (能够访问用来存放虚拟机各个子系统运行数据的MXBeans) ,以及虚拟机内置的高效profiling 工具 Java Flight Recorder (JFR)。
JMC的另一个优点就是:采用取样,而不是传统的代码植入技术,对应用性能的影响非常非常小,完全可以开着JMC来做压测(唯一影响可能是full gc多了)。
在JDK下载目录下,双击打开即可:
比如:
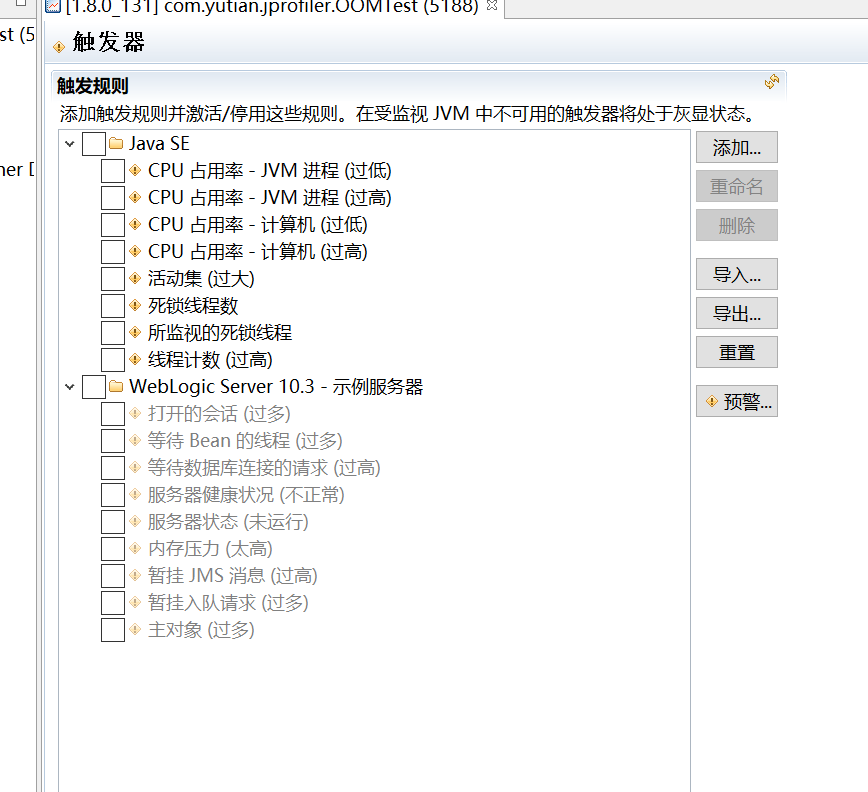
触发器:
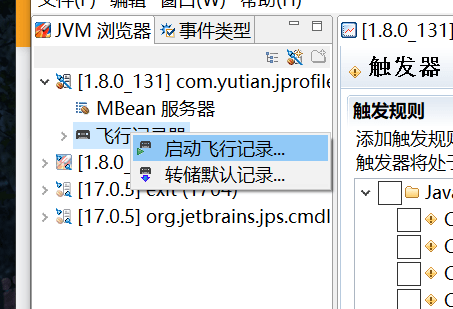
Java Flight Recorder:
右击,启动:
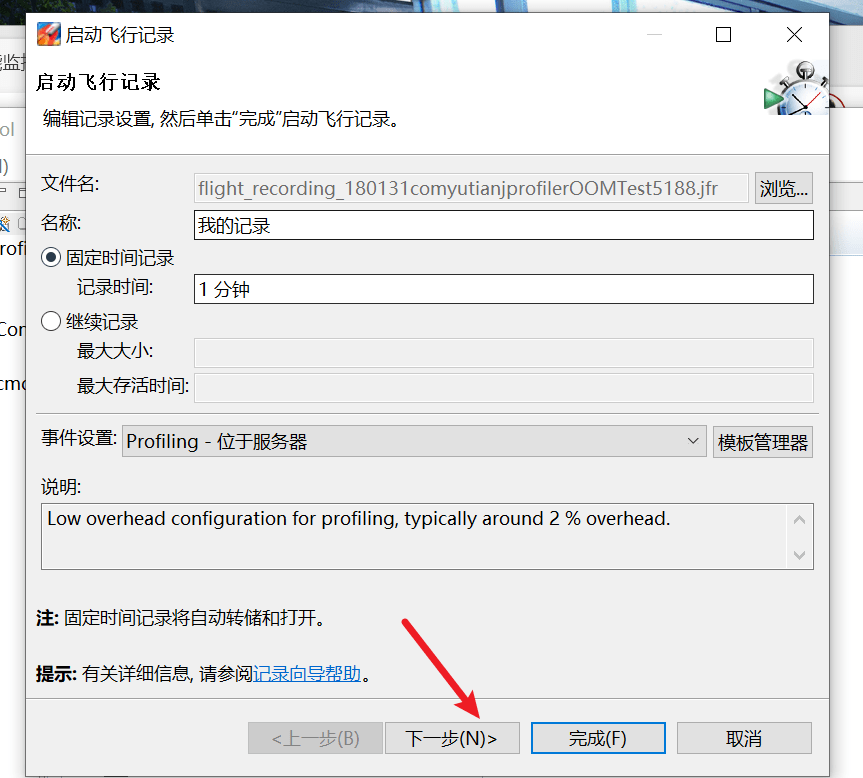
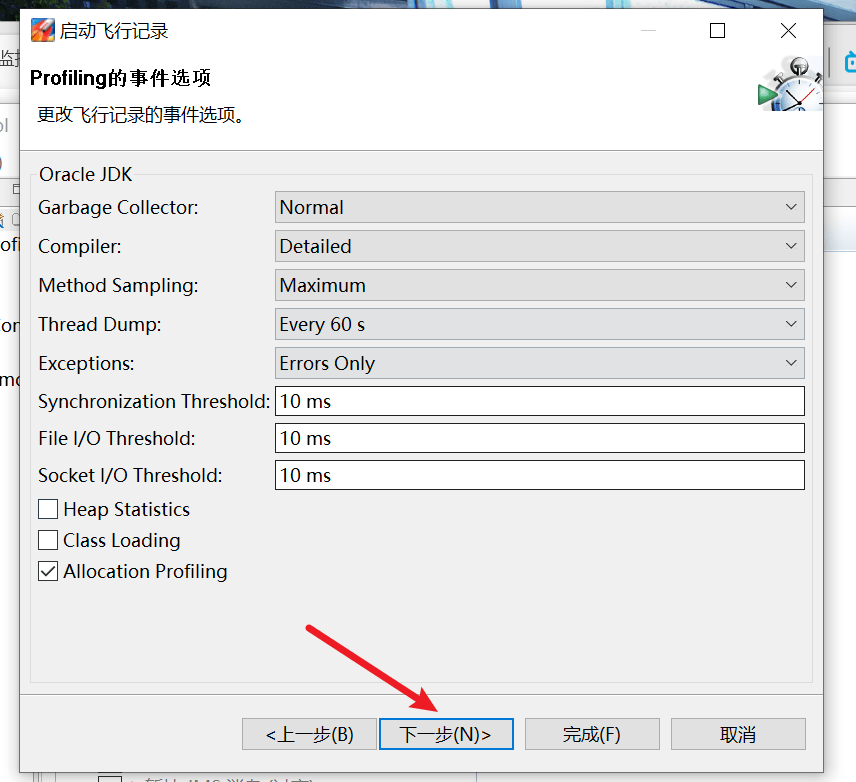
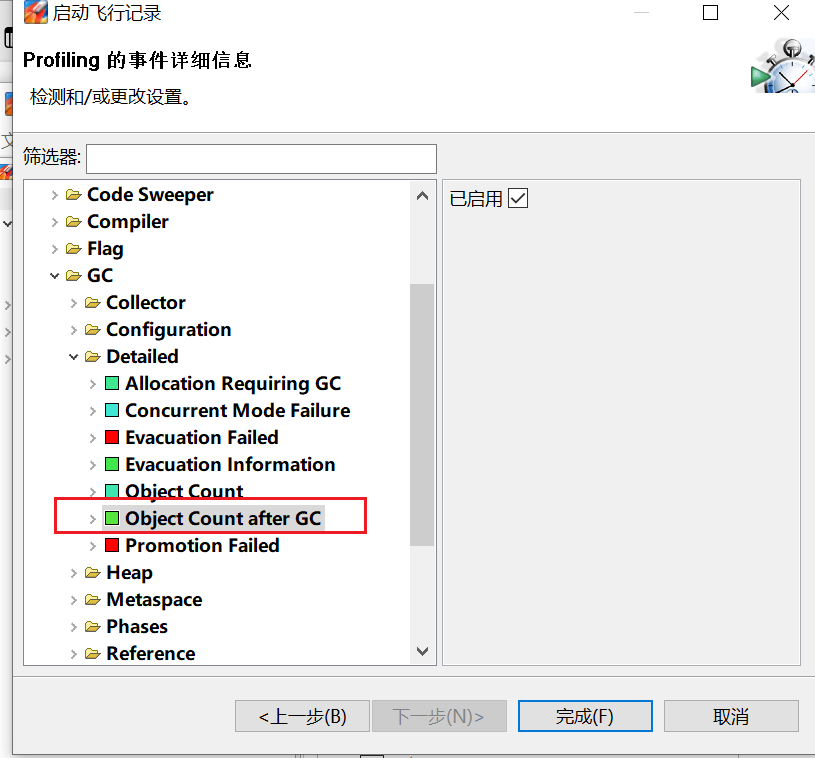
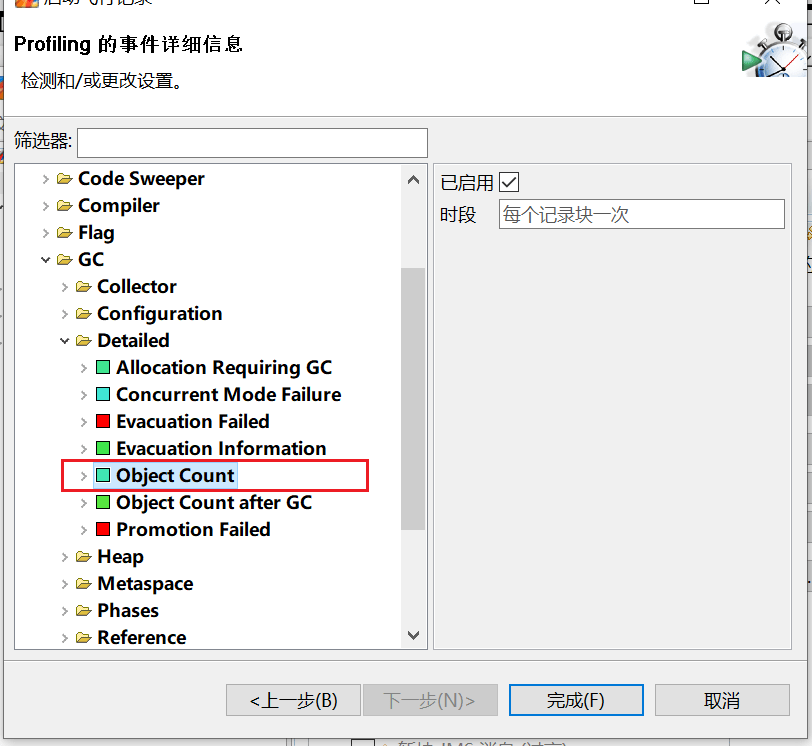
- 加上对象数量的统计: Java Virtual Machine -> GC -> Detailed -> ObjectCount/Object Count after GC
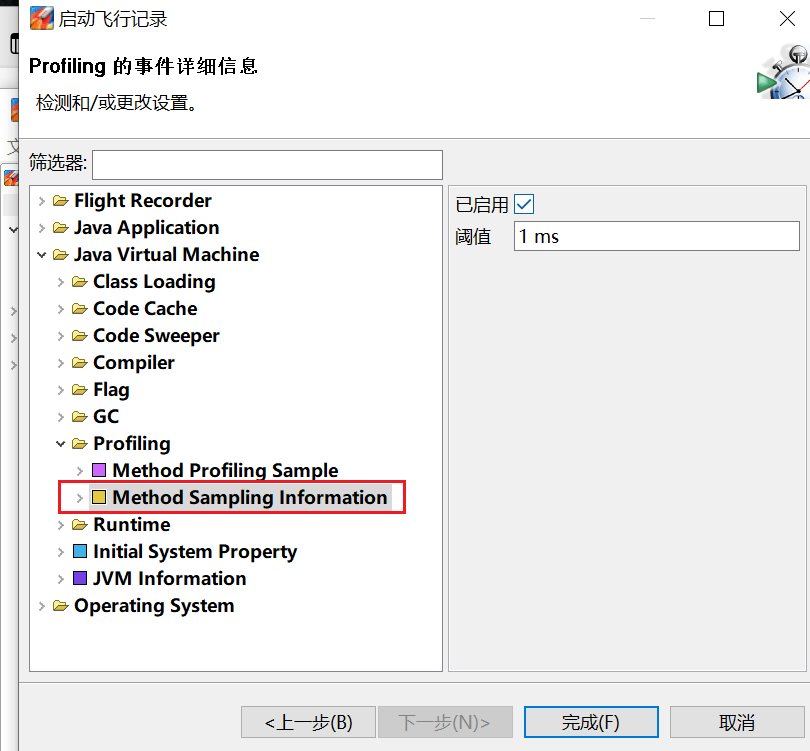
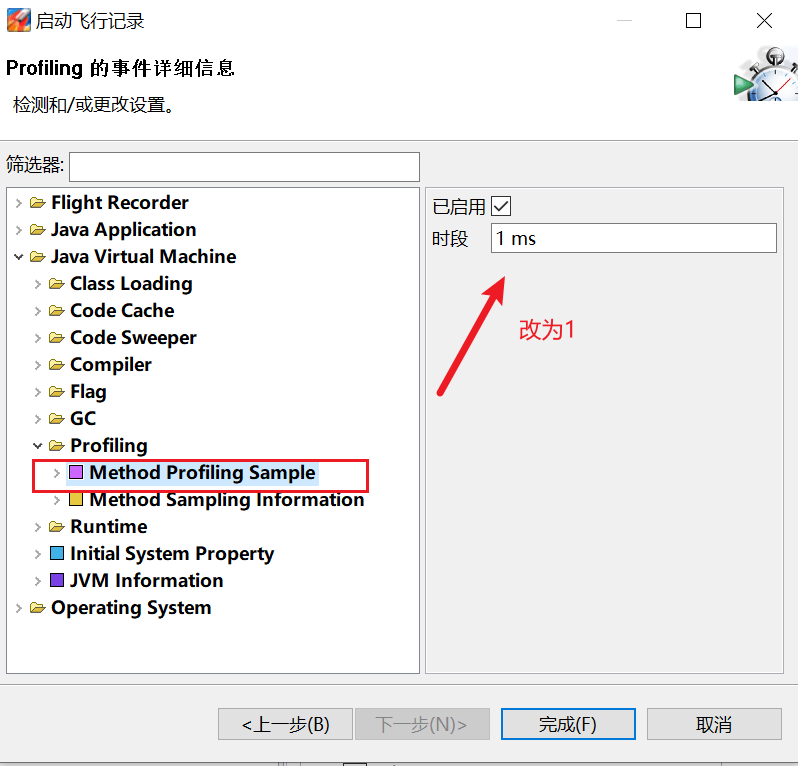
- 方法调用采样的间隔从 10ms 改为 1ms(但不能低于 1ms,否则会影响性能了): JavaVirtual Machine -> Profiling -> Method Profiling Sample/Method Sampling Information
- Socket 与 File 采样,10ms 太久,但即使改为 1ms 也未必能抓住什么,可以干脆取消掉: Java Application->File Read/FileWrite/Socket Read/Socket Write
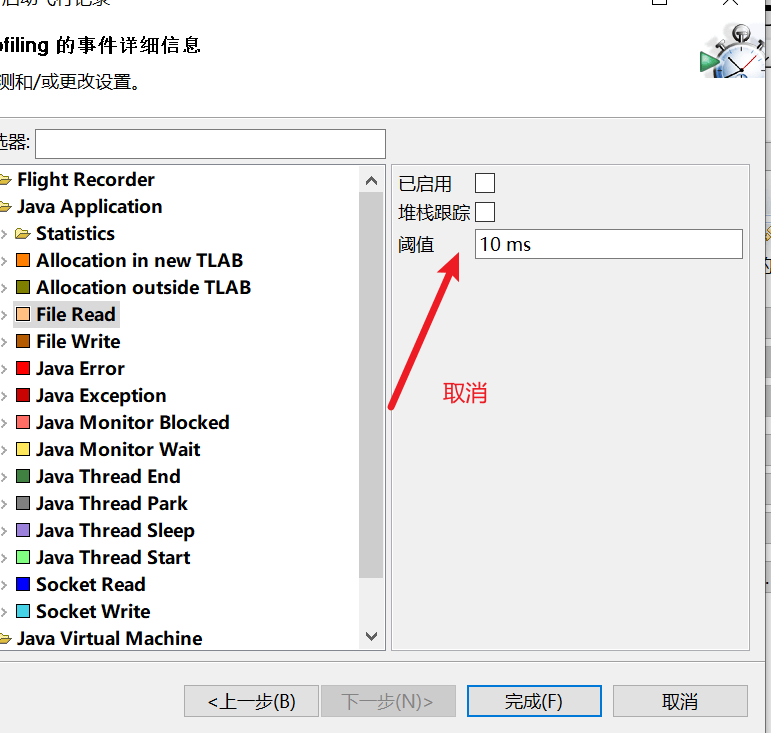
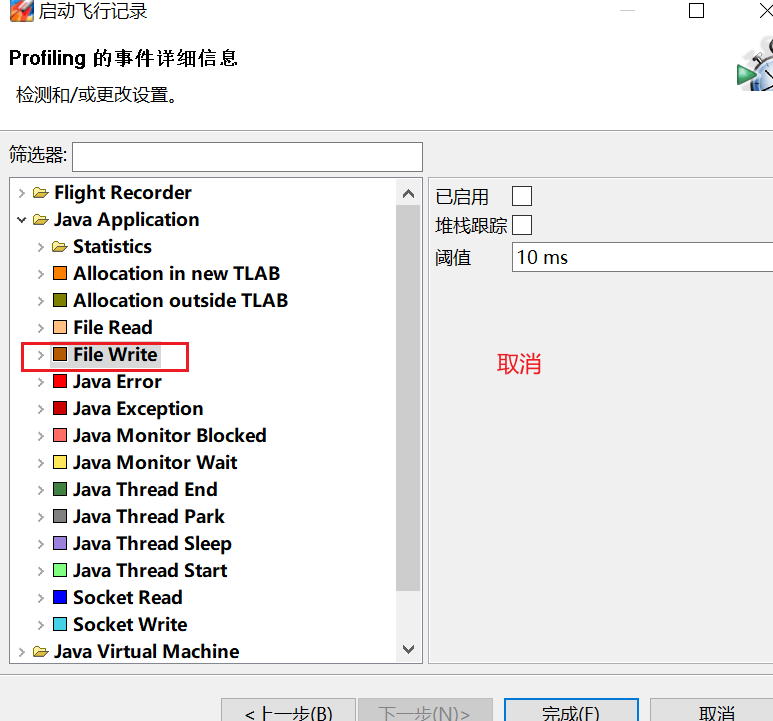
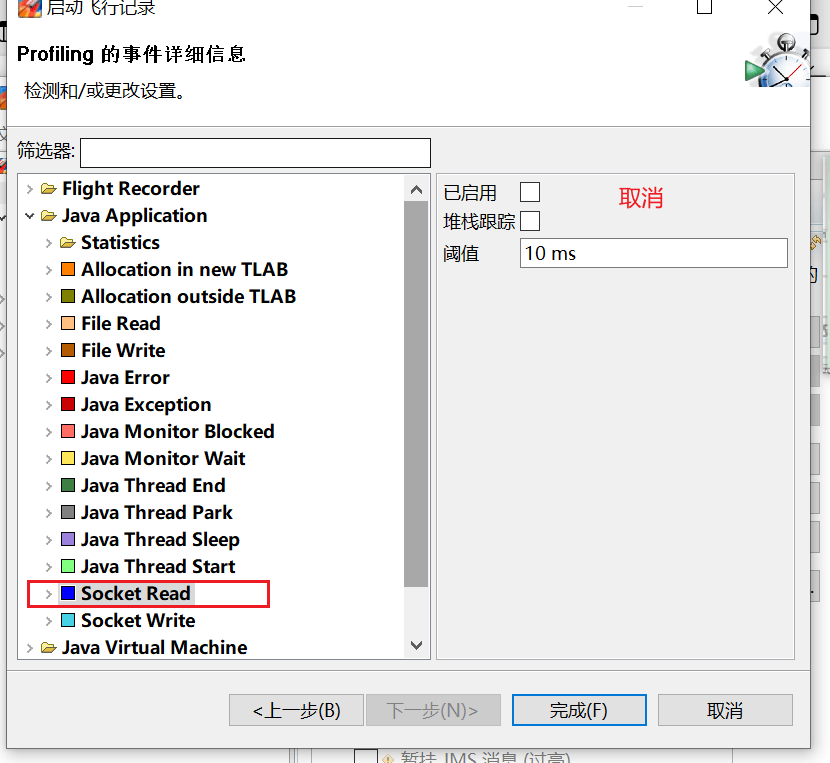
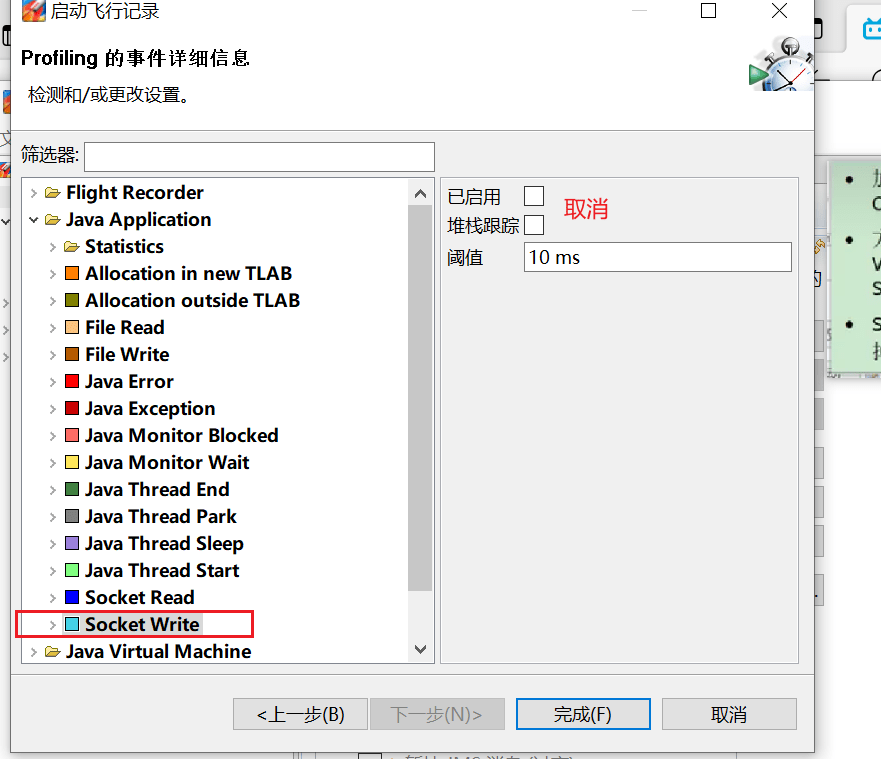
要采用取样,必须先添加参数:
-XX:+UnlockCommercialFeatures
-XX:+FlightRecorder
如:
-Xms600m -Xmx600m -XX:SurvivorRatio=8 -XX:+UnlockCommercialFeatures -XX:+FlightRecorder
事件类型
当启用时, JFR将记录运行过程中发生的一系列事件。其中包括Java层面的事件,如线程事件、锁事件,以及Java虚拟机内部的事件,如新建对象、垃圾回收和即时编译事件。
按照发生时机以及持续时间来划分,JFR的事件共有四种类型,它们分别为以下四种。
- 瞬时事件(Instant Event),用户关心的是它们发生与否,例如异常、线程启动事件。
- 持续事件(Duration Event),用户关心的是它们的持续时间,例如垃圾回收事件。
- 计时事件(Timed Event),是时长超出指定阈值的持续事件。
- 取样事件(Sample Event) ,是周期性取样的事件。
取样事件的其中一个常见例子便是方法抽样(Method Sampling) ,即每隔一段时间统计各个线程的栈轨迹。如果在这些抽样取得的栈轨迹中存在一个反复出现的方法,那么我们可以推测该方法是热点方法。
上述为第三种启动方式:
方式1: 使用-XX:StartFlightRecording=参数
第一种是在运行目标 Java 程序时添加-XX:StartFlightRecording=参数。
比如:下面命令中, JFR将会在 Java虚拟机启动 5s后(对应delay=5s)收集数据,持续20s (对应duration=20s) 。当收集完毕后, JFR会将收集得到的数据保存至指定的文件中(对应filename=myrecording.jfr)
java-XX:StartFlightRecording=delay=5s,duration=20s, filename=myrecording-jfr, settings=profile MyApp
由于JFR将持续收集数据,如果不加以限制,那么JFR可能会填满硬盘的所有空间。因此,我们有必要对这种模式下所收集的数据进行限制。比如:
java -XX:StartFlightRecording=maxage=10m,maxsize=100m,name=SomeLabel MyApp
方式2:使用jcmd的JFR.*子命令
通过jcmd来让JFR开始收集数据、停止收集数据,或者保存所收集的数据,对应的子命令分别为JFR.start, JFR.stop,以及JFR.dump.
jcmd <PID> JFR.start settings=profile maxage=10m maxsize=150m name=SomeLabel
上述命令运行过后,目标进程中的 JFR 已经开始收集数据。此时,我们可以通过下述命令来导出已经收集到的数据:
jcmd <PID> JFR.dump name=SomeLabel filename=myrecording.jfr
最后,我们可以通过下述命令关闭目标进程中的 JFR:
jcmd <PID> JFR.stop name=SomeLabel
8.其他工具
Flame Graphs (火焰图)
在追求极致性能的场景下,了解你的程序运行过程中cpu在干什么很重要,火焰图就是一种非常直观的展示cpu在程序整个生命周期过程中时间分配的工具。火焰图对于现代的程序员不应该陌生,这个工具可以非常直观的显示出调用栈中的CPU消耗瓶颈。网上的关于java火焰图的讲解大部分来自于
Brendan Gregg的博客:http://www.brendangregg.com/flamegraphs.html
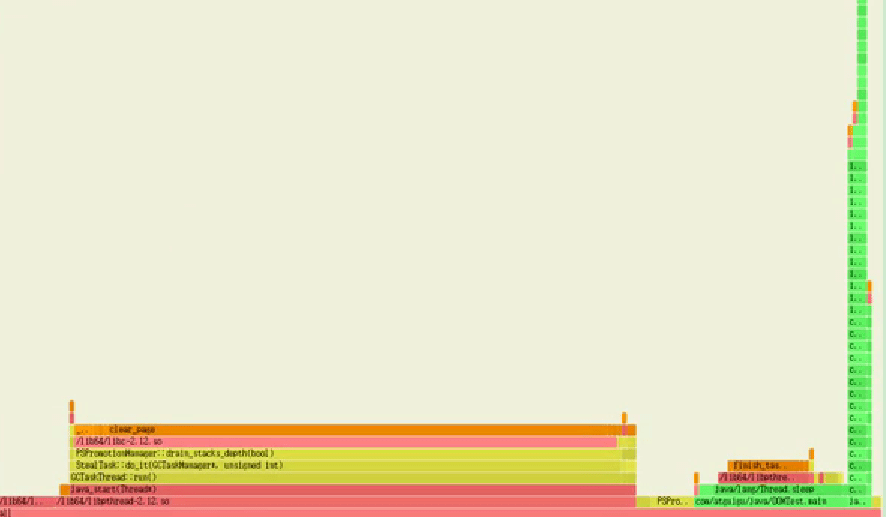
横轴,调用的时间
纵轴,调用的栈帧
火焰图,简单通过x轴横条宽度来度量时间指标, y轴代表线程栈的层次。
Tprofiler
Tprofiler案例:使用JDK自身提供的工具进行JVM调优可以将TPS由2.5提升到20 (提升了7倍),并准确定位系统瓶颈。
系统瓶颈有:应用里静态对象不是太多、有大量的业务线程在频繁创建一些生命周期很长的临时对象,代码里有问题。
那么,如何在海量业务代码里边准确定位这些性能代码?这里使用阿里开源工具TProfiler来定位这些性能代码,成功解决掉了 GC 过于频繁的性能瓶颈,并最终在上次优化的基础上将 TPS 再提升了4 倍,即提升到 100.
TProfiler配置部署、远程操作、日志阅读都不太复杂,操作还是很简单的。但是其却是能够起到一针见血、立竿见影的效果,帮我们解决了 GC 过于频繁的性能瓶颈。
TProfiler 最重要的特性就是能够统计出你指定时间段内 JVM 的 top method,这些 top method极有可能就是造成你JVM性能瓶颈的元凶。这是其他大多数JVM调优工具所不具备的,包括JRockit Mission Control, JRokit首席开发者Marcus Hirt在其私人博客《Low Overhead Method Profiling with Java Mission Control》下的评论中曾明确指出JRMC 并不支持 TOP 方法的统计。
TProfiler的下载:
https://github.com/alibaba/TProfiler
Btrace
Btrace是SUN Kenai云计算开发平台下的一个开源项目, 旨在为java提供安全可靠的动态跟踪分析工具。
一个Java平台的安全的动态追踪工具。可以用来动态地追踪一个运行的Java程序。BTrace动态调整目标应用程序的类以注入跟踪代码(“字节码跟踪”)。
参考资料:
尚硅谷宋红康:JVM全套教程:https://www.bilibili.com/video/BV1PJ411n7xZ
周志明:深入理解java虚拟机