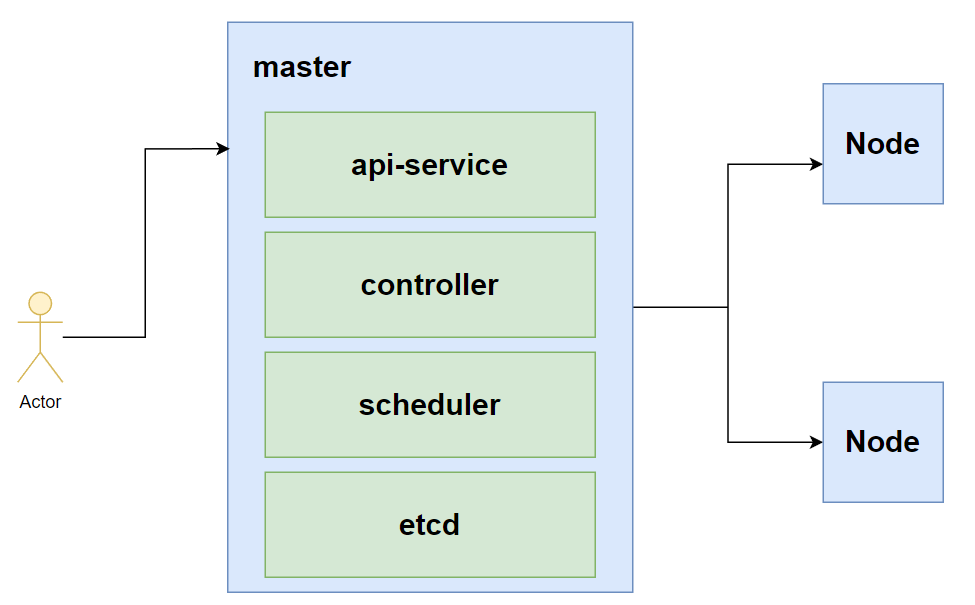
5.服务发现
Service
基本配置
Kubernetes 中 Service 是 将运行在一个或一组 Pod上的网络应用程序公开为网络服务的方法。
使用 Service 让一组 Pod 可在网络上访问,这样客户端就能与之交互。
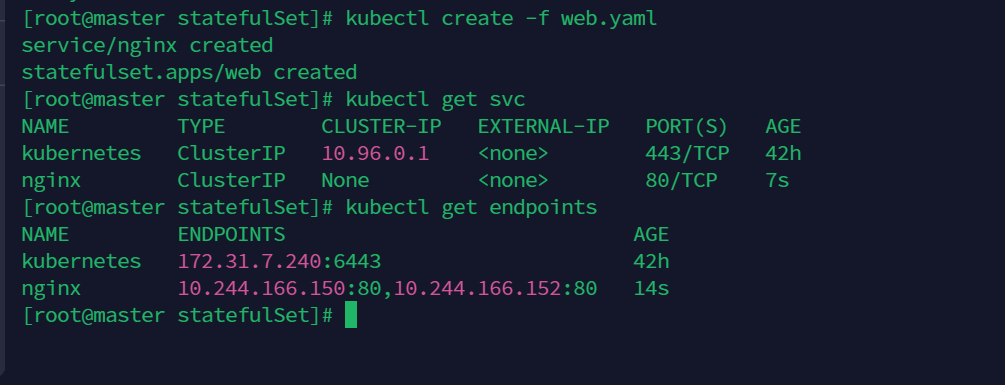
当service被创建时还会创建一个endpoint,Endpoints 是实现实际服务的端点的集合。
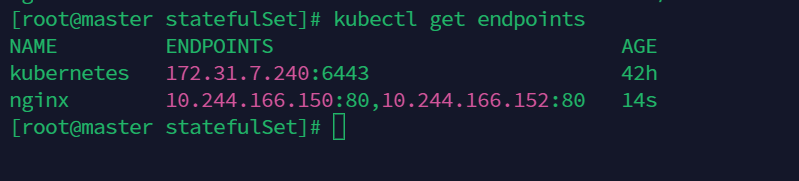
正是启动的这两个ip
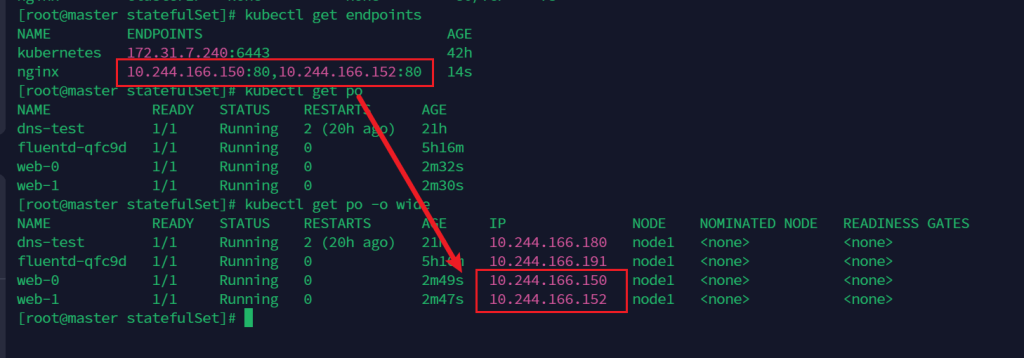
访问情况如图:
创建并进入nginx-svc.yaml
mkdir /opt/k8s/services/
cd /opt/k8s/services/
vim nginx-svc.yaml
配置如下:
apiVersion: v1
# Service类型
kind: Service
metadata:
# Service自己的标签
labels:
app: nginx
#Service名称
name: nginx-svc
namespace: default
spec:
# 通过标签匹配Pod
selector:
# 标签
app: nginx-deploy
# 端口映射
ports:
# service自己的端口,内网访问被使用
- port: 80
# 目标Pod端口
targetPort: 80
name: web
# 随机使用一个node节点的端口,每个node都会绑定,可以通过此端口访问,但效率不高,一般不用
type: NodePort创建 service
kubectl create -f nginx-svc.yaml
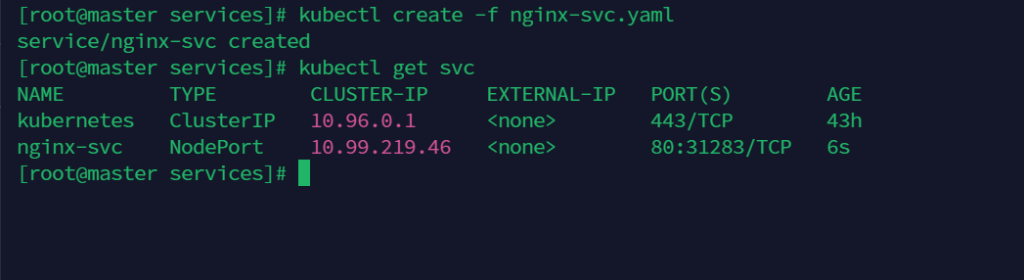
查看 service 信息,通过 service 的 cluster ip 进行访问
kubectl get svc
查看svc描述信息
kubectl describe svc nginx-svc
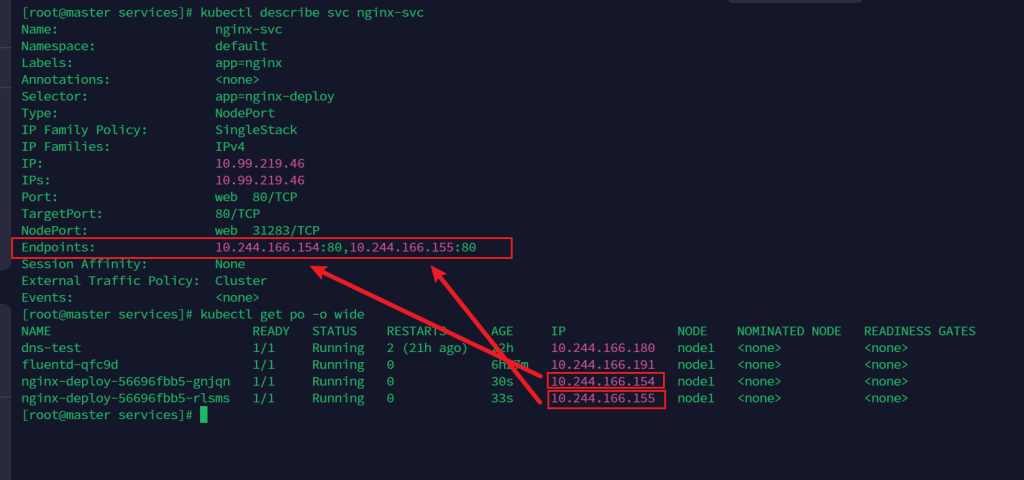
# 查看 pod 信息,通过 pod 的 ip 进行访问
kubectl get po -o wide
测试创建其他 pod 通过 service name 进行访问
运行一个 pod,基础镜像为 busybox 工具包,
kubectl run -i --tty --image busybox:1.28.4 dns-test --restart=Never --rm /bin/sh
如果之前创建过使用,dns-test是名字
kubectl exec -it dns-test -- sh
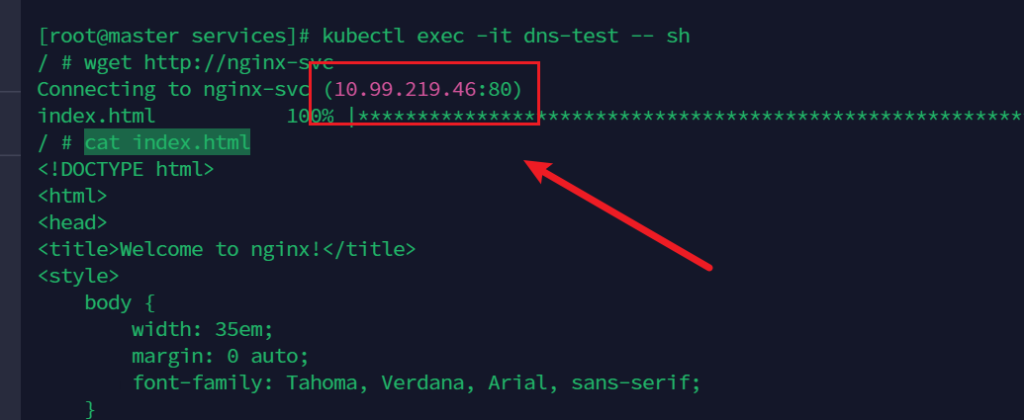
wget http://nginx-svc
cat index.html
可以看到都能正常访问
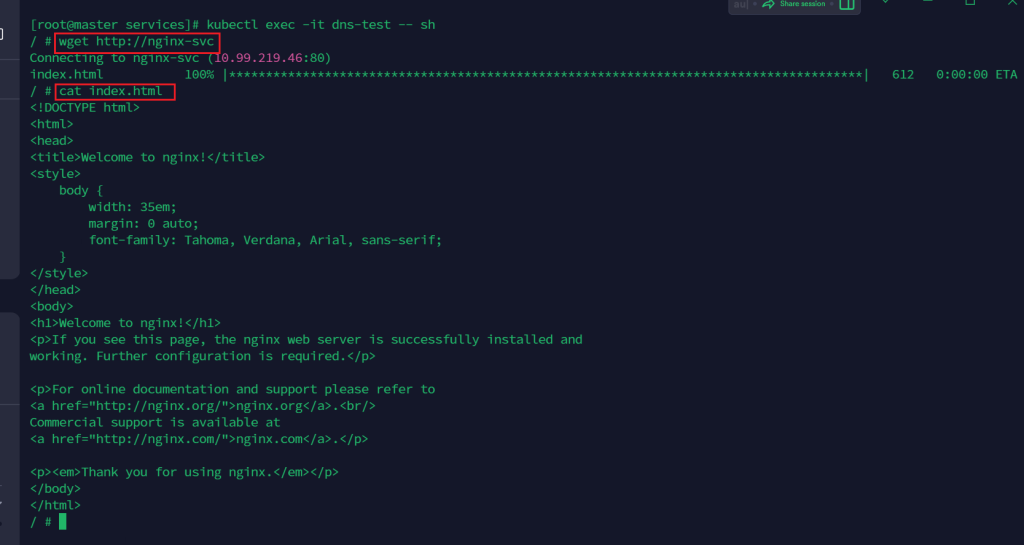
仔细看这个端口,正是service的ip
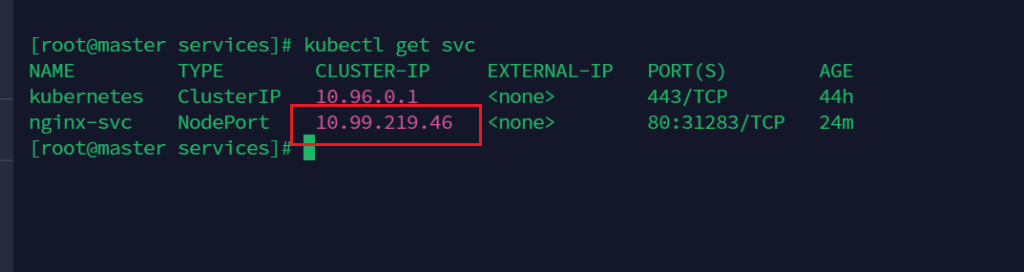
恰好证明无论是外部访问,还是从Pod中访问,都经过service
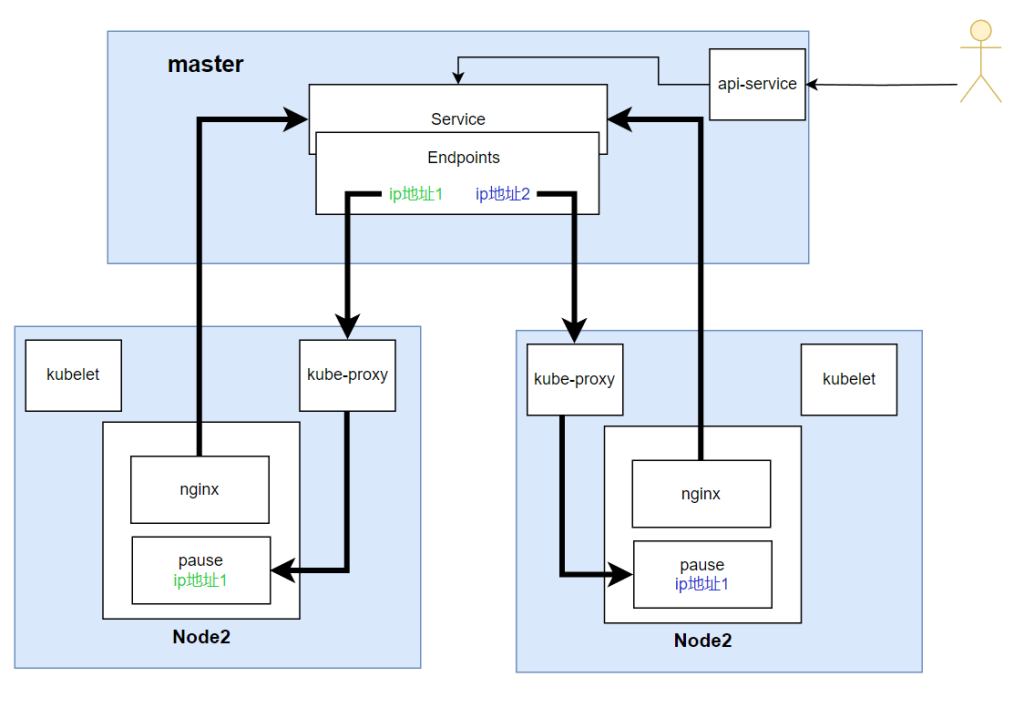
默认在当前 namespace 中访问,如果需要跨 namespace 访问 pod,则在 service name 后面加上 .<namespace> 即可
wget http://nginx-svc.default

代理 k8s 外部服务
编写 service 配置文件时,不指定 selector 属性,不会自动创建endpoint,我们自己创建 endpoint
创建并编辑文件
cd /opt/k8s/services/
vim nginx-svc-external.yaml
配置如下
apiVersion: v1
# Service类型
kind: Service
metadata:
# Service自己的标签
labels:
app: nginx
#Service名称
name: nginx-svc-external
namespace: default
spec:
# 端口映射
ports:
# service自己的端口,内网访问被使用
- port: 80
# 目标Pod端口
targetPort: 80
name: web
#
type: ClusterIP创建
kubectl create -f nginx-svc-external.yaml
并没有与service对应的enpoint
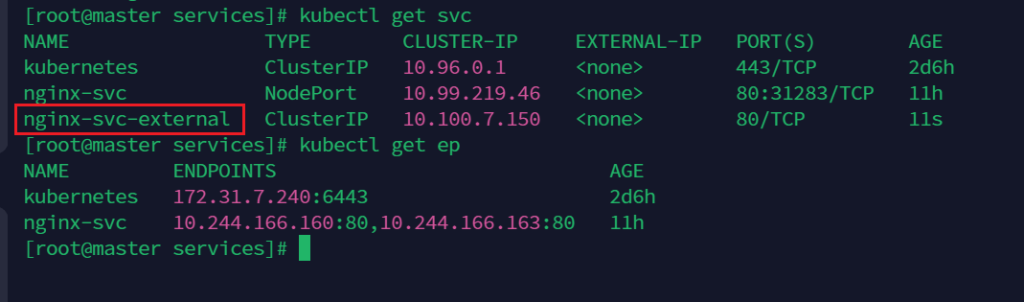
创建一个enpoint
vim nginx-enpoint-external.yaml
再开个云服务器,不要加入k8s集群,简单部署个nginx
访问8.134.131.33
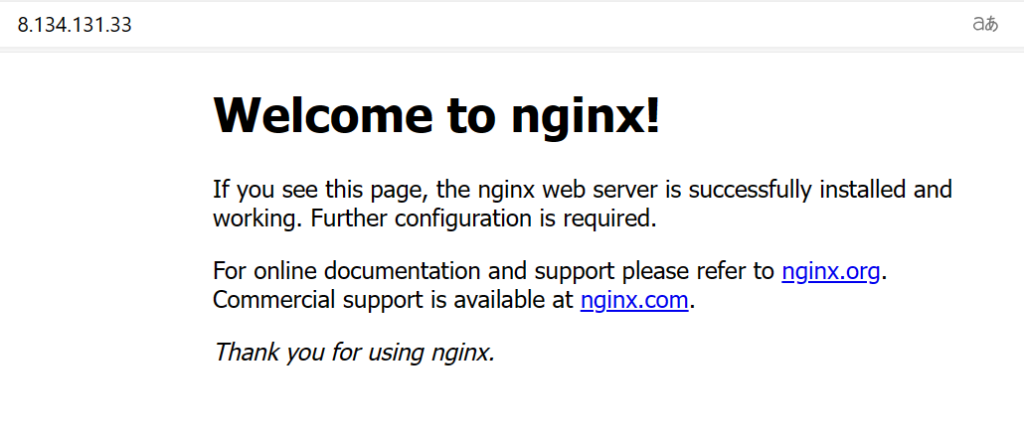
外部访问这个IP测试
配置如下
apiVersion: v1
# enpoint资源
kind: Endpoints
metadata:
labels:
# 与 service 一致的标签
app: nginx
# 与 service 一致
name: nginx-svc-external
## 与 service 一致
namespace: default
subsets:
- addresses:
# 目标 ip 地址
- ip: 8.134.131.33
ports:
# 与 service对应端口名字一样
- name: web
port: 80
protocol: TCP
创建
kubectl create -f nginx-enpoint-external.yaml
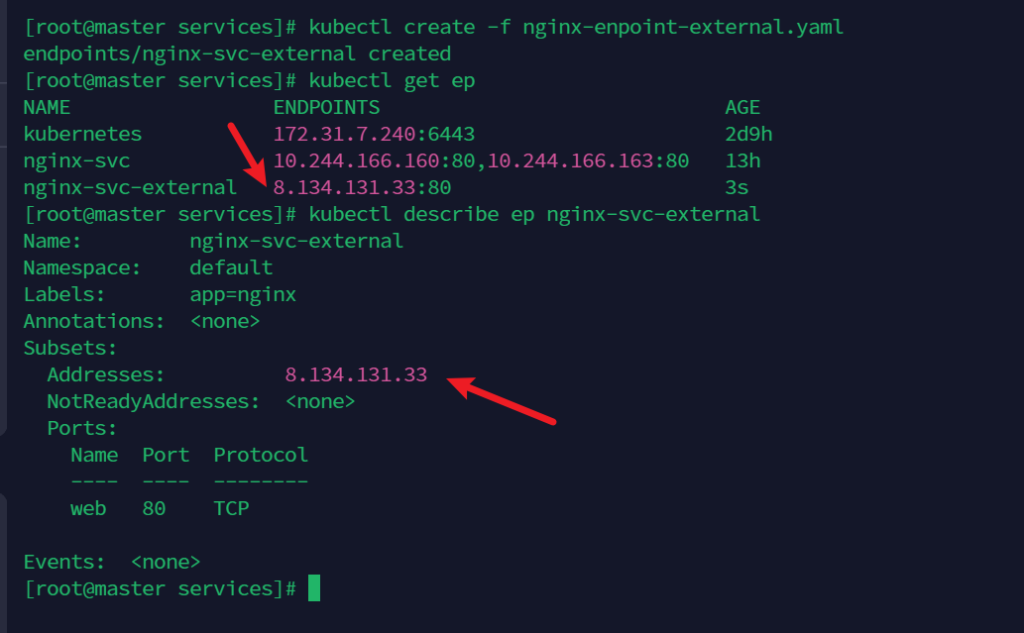
运行一个 pod,基础镜像为 busybox 工具包,
kubectl exec -it dns-test -- sh
wget http://nginx-svc-external
可以看到成功访问到index.html的资源
大致流程如下
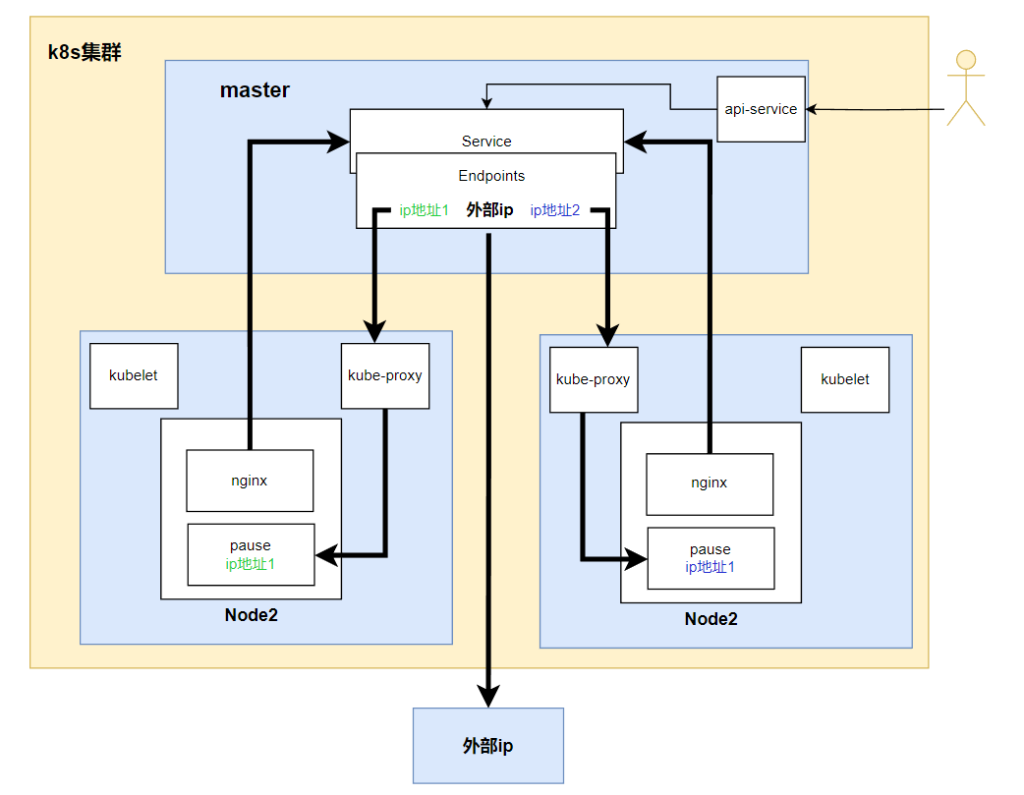
反向代理外部域名
就是直接访问域名
新建文件
vim nginx-enpoint-externalName.yaml
配置如下
apiVersion: v1
kind: Service
metadata:
labels:
app: name
name: name
spec:
type: ExternalName
# 域名
externalName: 域名常用类型:
- ClusterIP :只能在集群内部使用,不配置类型的话默认就是 ClusterIP
- ExternalName :返回定义的 CNAME 别名,可以配置为域名
- NodePort :会在所有安装了 kube-proxy 的节点都绑定一个端口,此端口可以代理至对应的 Pod。
- LoadBalancer :使用云服务商(阿里云、腾讯云等)提供的负载均衡器服务
对于NodePort:
集群外部可以使用任意节点 ip + NodePort 的端口号访问到集群中对应 Pod 中的服务。
nodePort 配置指定端口,
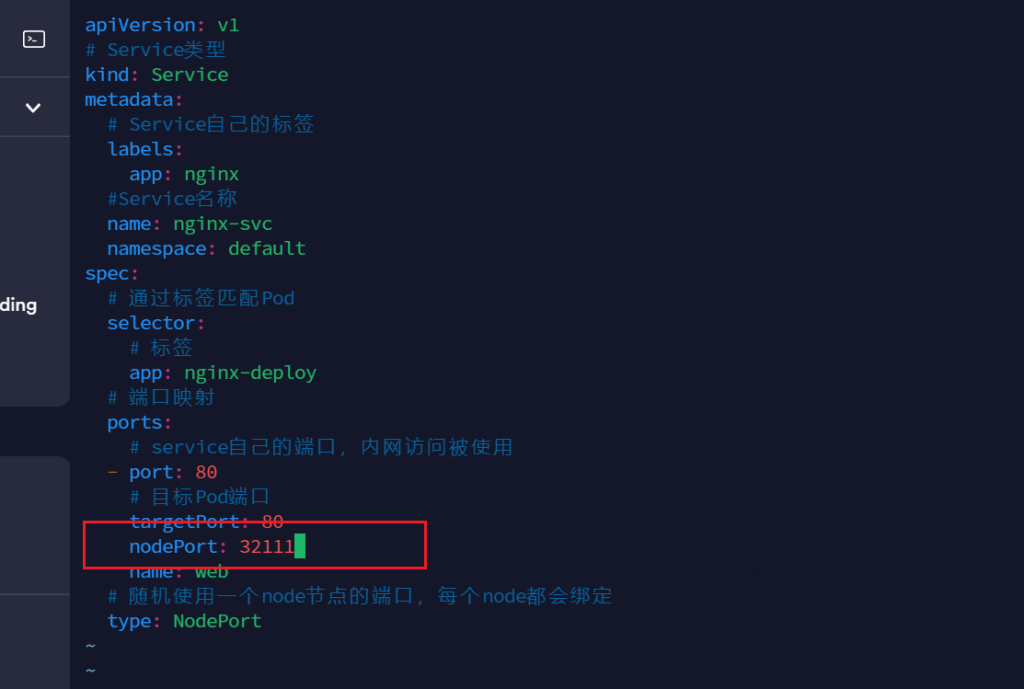
如果不指定会随机指定端口,端口范围:30000~32767
Ingress
Ingress 是对集群中服务的外部访问进行管理的 API 对象,典型的访问方式是 HTTP。
Ingress 可以提供负载均衡、SSL 终结和基于名称的虚拟托管。
可以看看官网的图:
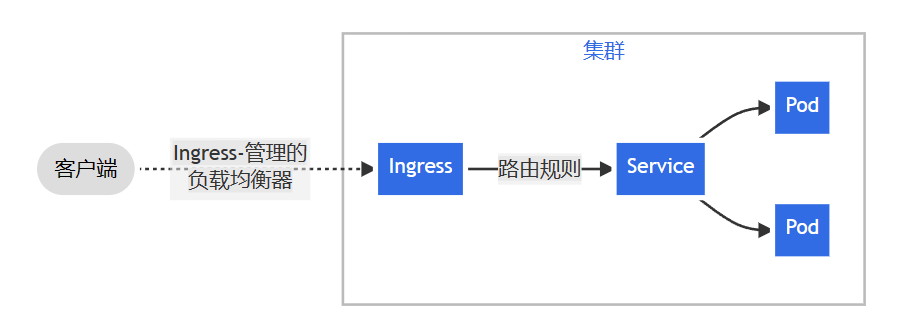
所以我们需要部署一个 Ingress 控制器,官网如下,可以选择
我们这里使用ingress-nginx
Installation Guide – Ingress-Nginx Controller (kubernetes.github.io)
下载配置
创建工作目录
mkdir /opt/k8s/helm
cd /opt/k8s/helm
下载Helm
wget https://get.helm.sh/helm-v3.2.3-linux-amd64.tar.gz
不过使用wget直接下载很慢,所以可以下载再上传到主机
再上传
ls
解压
tar -zxvf helm-v3.13.1-linux-amd64.tar.gz

然后将其移至所需的目标位置
cp linux-amd64/helm /usr/local/bin/

验证是否成功
helm version

添加仓库
helm repo add ingress-nginx https://kubernetes.github.io/ingress-nginx

查看仓库列表
helm repo list
搜索 ingress-nginx
helm search repo ingress-nginx

下载安装包
helm pull ingress-nginx/ingress-nginx

将下载好的安装包解压
tar -xf ingress-nginx-4.8.3.tgz

接下来是改配置文件,超级麻烦

修改 values.yaml镜像地址为国内镜像
cd ingress-nginx
vim values.yaml
首先改为国内镜像
registry: registry.cn-hangzhou.aliyuncs.com image: google_containers/nginx-ingress-controller
同时tag改为1.5.1,注释掉两个验证
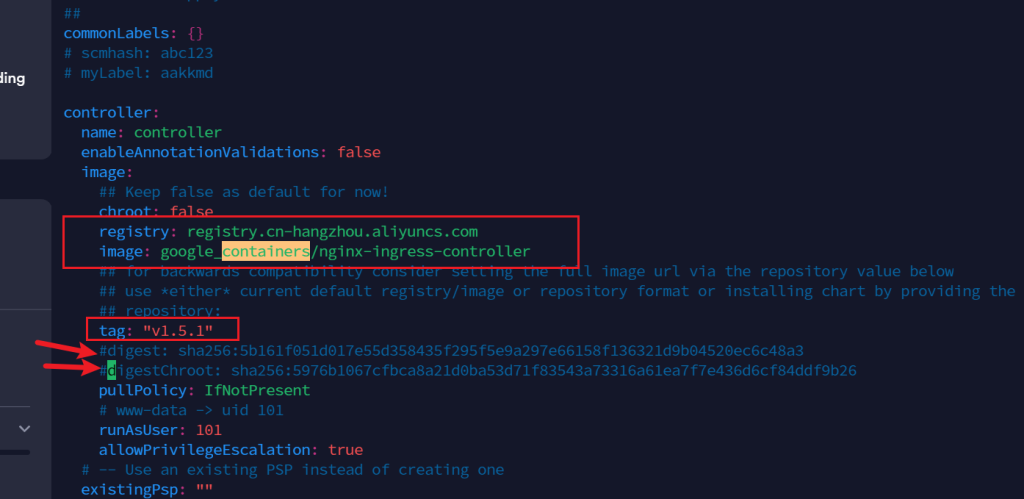
以下同样,如果不好找可以搜索关键词
registry: registry.cn-hangzhou.aliyuncs.com image: google_containers/kube-webhook-certgen
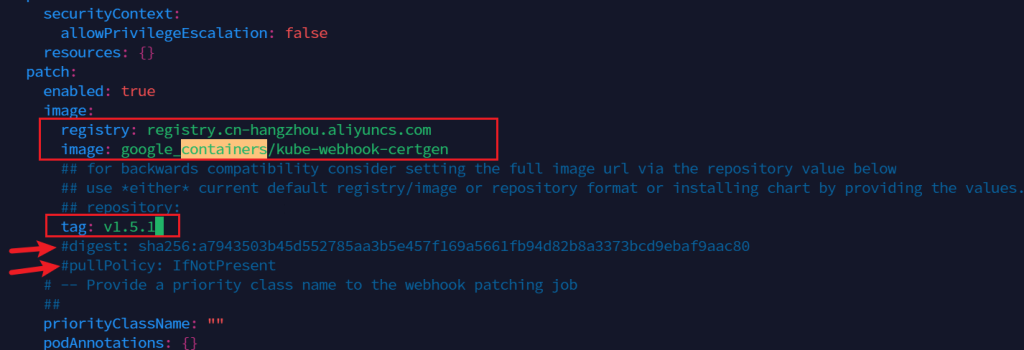
在187行,将Deployment改为DaemonSet
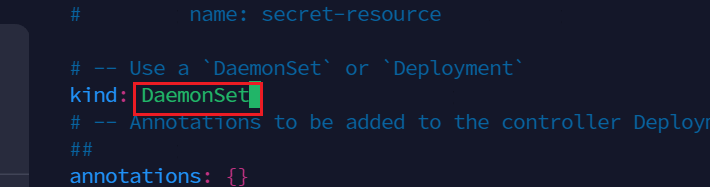
在292行,将false改为true
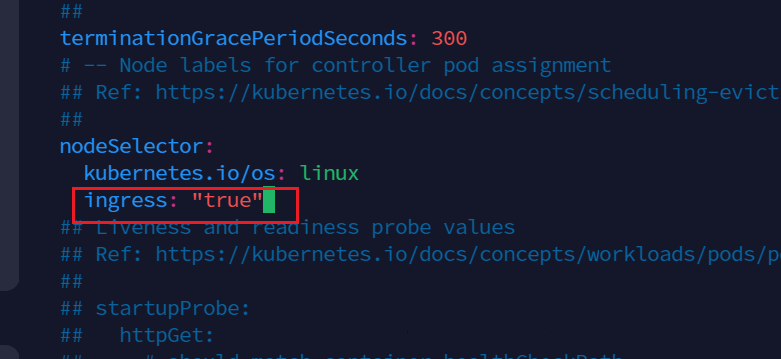
在91行,将false改为true
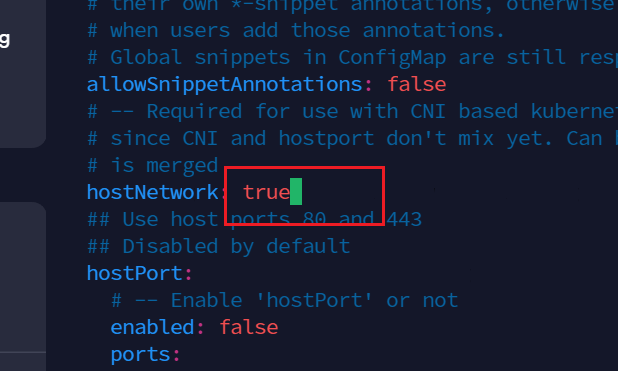
71行,改为dnsPolicy: ClusterFirstWithHostNet
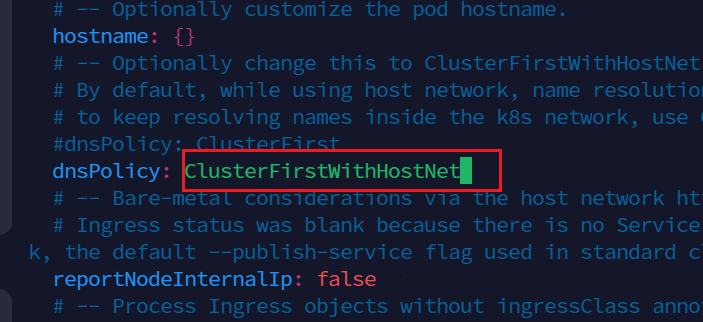
在493行,改为ClusterIP
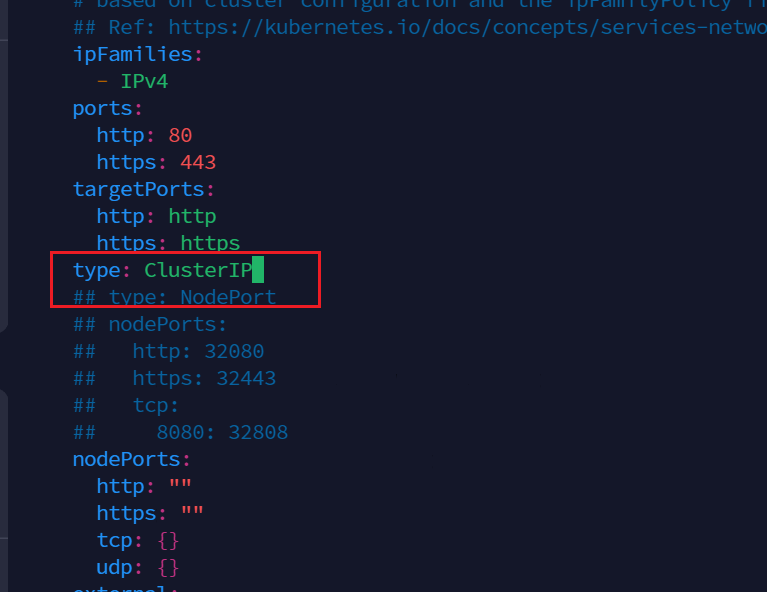
在608行,改为false
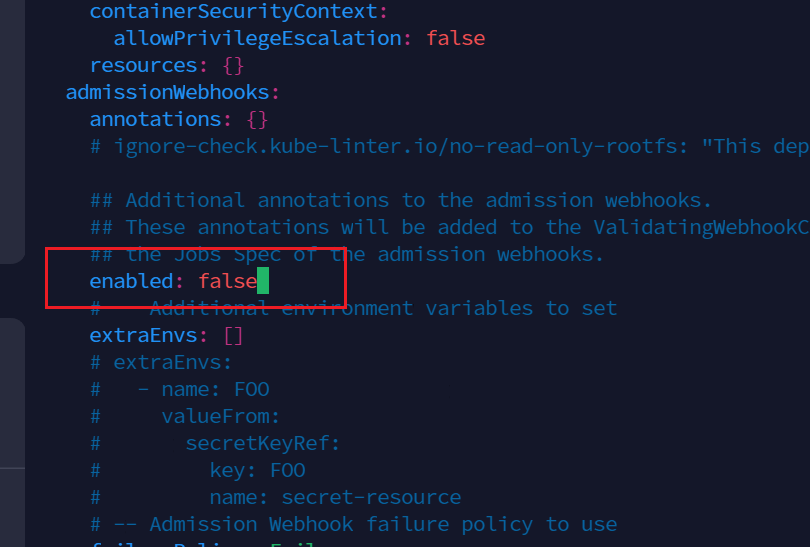
为 ingress 专门创建一个 namespace
kubectl create ns ingress-nginx

为需要部署 ingress 的节点上加标签
kubectl label node node1 ingress=true

在ingress-nginx目录执行安装 ingress-nginx命令,后面这个.会自动找values.yaml
helm install ingress-nginx -n ingress-nginx .
出现以下即成功
可以看到运行成功
kubectl get po -n ingress-nginx

配置文件
创建并进入
mkdir /opt/k8s/ingress
cd /opt/k8s/ingress
vim dreams-ingress.yaml
配置如下
apiVersion: networking.k8s.io/v1
kind: Ingress # 资源类型为 Ingress
metadata:
name: dreams-nginx-ingress
annotations:
kubernetes.io/ingress.class: "nginx"
nginx.ingress.kubernetes.io/rewrite-target: /
spec:
rules: # ingress 规则配置,可以配置多个
- host: www.benghuaishatianxiadiyi.site # 域名配置,可以使用通配符 *
http:
paths: # 相当于 nginx 的 location 配置,可以配置多个
- pathType: Prefix # 路径类型,按照路径类型进行匹配 ImplementationSpecific 需要指定 IngressClass,具体匹配规则以 IngressClass 中>的规则为准。Exact:精确匹配,URL需要与path完全匹配上,且区分大小写的。Prefix:以 / 作为分隔符来进行前缀匹配
backend:
service:
name: nginx-svc # 代理到哪个 service
port:
number: 80 # service 的端口
path: /api # 等价于 nginx 中的 location 的路径前缀匹配
上面的参数pathType
Ingress 中的每个路径都需要有对应的路径类型(Path Type)。未明确设置 pathType 的路径无法通过合法性检查。当前支持的路径类型有三种:
- ImplementationSpecific:对于这种路径类型,匹配方法取决于 IngressClass。 具体实现可以将其作为单独的 pathType 处理或者作与 Prefix或 Exact 类型相同的处理。
- Exact :精确匹配 URL 路径,且区分大小写。
- Prefix:基于以 / 分隔的 URL 路径前缀匹配。匹配区分大小写, 并且对路径中各个元素逐个执行匹配操作。 路径元素指的是由 /分隔符分隔的路径中的标签列表。 如果每个 p 都是请求路径 p 的元素前缀,则请求与路径 p 匹配。
可以看看官网的例子Ingress | Kubernetes
www.benghuaishatianxiadiyi.site当然这个域名是假的,这里就不演示了
6.配置管理
ConfigMap
创建
ConfigMap 是一种 API 对象,用来将非机密性的数据保存到键值对中。使用时, Pod 可以将其用作环境变量、命令行参数或者存储卷中的配置文件。
ConfigMap 将你的环境配置信息和容器镜像解耦,便于应用配置的修改。
查看示例,configmap也可以写成cm
kubectl create configmap -h
创建工作目录
mkdir /opt/k8s/config
cd /opt/k8s/config
举例:
mkdir test
cd test/
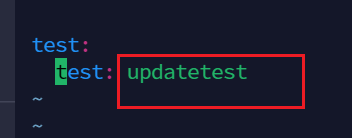
vim test.yaml
乱填点东西,如
test: test: test
再来一个
vim pei.yaml
乱填点东西,如
pei: pei: pei
构建 configmap 对象
方法一
指定整个文件夹
kubectl create configmap my-config --from-file=path/to/bar

例如
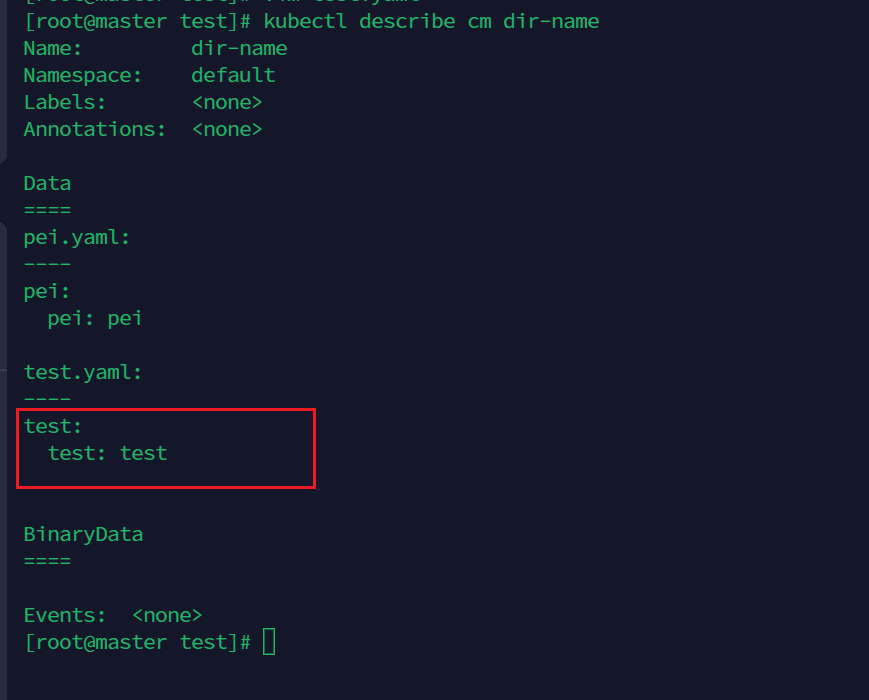
kubectl create configmap dir-name --from-file=test/
查看configmap 对象
kubectl get cm

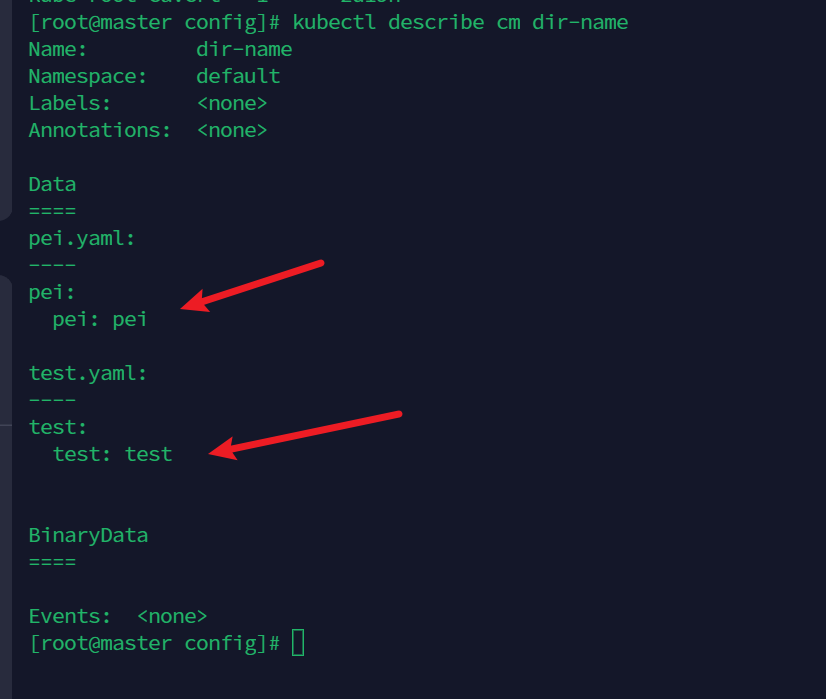
查看configmap 对象描述信息,dir-name就是名字
kubectl describe cm dir-name
正是我们的配置
方法二(常用)
指定单个文件
kubectl create configmap my-config --from-file=key1=/path/to/bar/file1.txt --from-file=key2=/path/to/bar/file2.txt
vim spring.yaml
乱填点东西,如
spring: test: test
指定单个文件
kubectl create configmap spring-test --from-file=/opt/k8s/config/spring.yaml
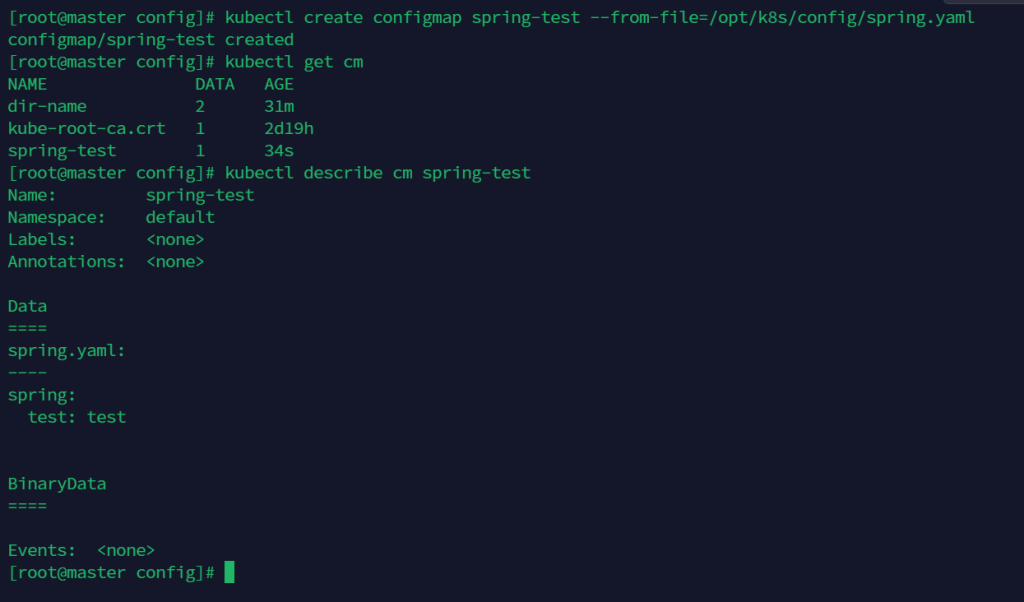
指定单个文件并指定名字
create configmap spring-test-name --from-file=app.yaml=/opt/k8s/config/spring.yaml
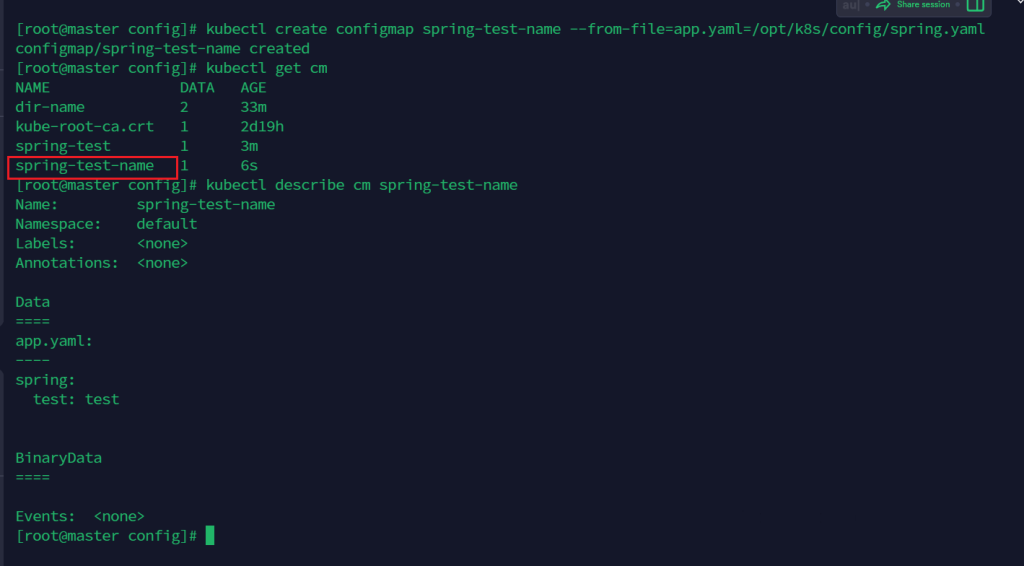
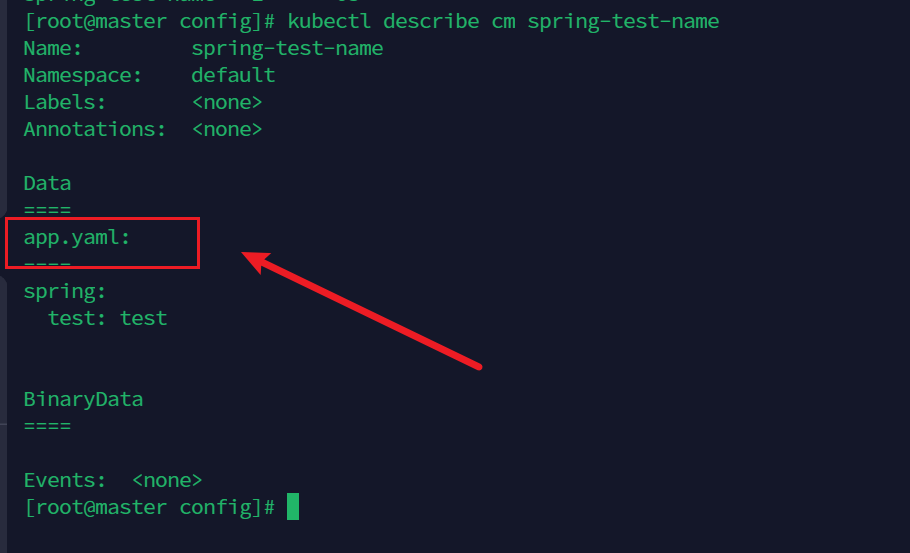
查看configmap 对象描述信息
kubectl describe cm spring-test-name
app.yaml正是我们取得名字
方式三
直接指定键值对
kubectl create configmap key-value-test --from-literal=testkey1=value1 --from-literal=testkey2=value2
不过没有文件名了
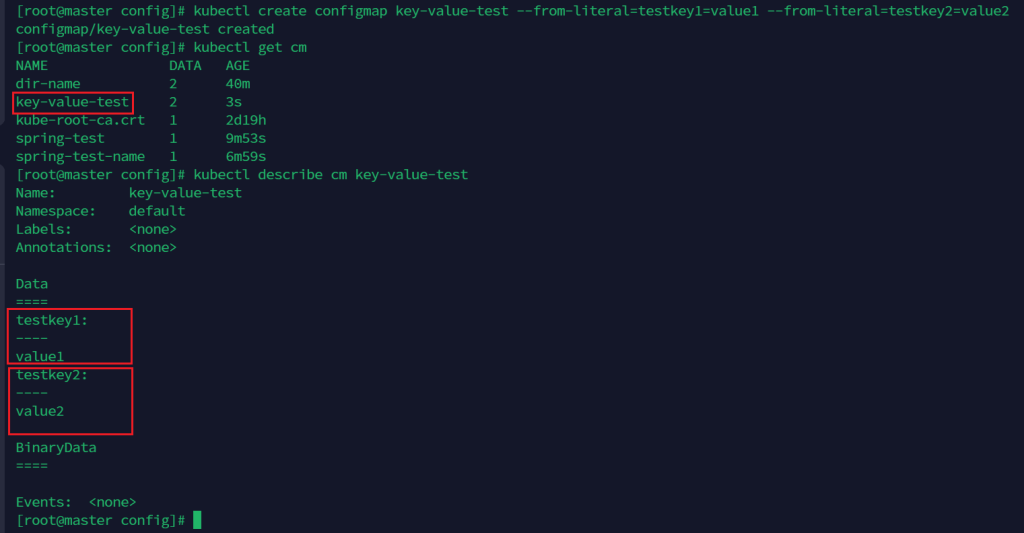
方式四、五
不再演示

使用
新建一个文件
vim env-test.yaml
配置如下
apiVersion: v1
kind: Pod
metadata:
name: env-test
spec:
containers:
- name: env-test
# 轻量级nginx
image: alpine
command: ["/bin/sh","-c","env;sleep 3600"]
imagePullPolicy: IfNotPresent
env:
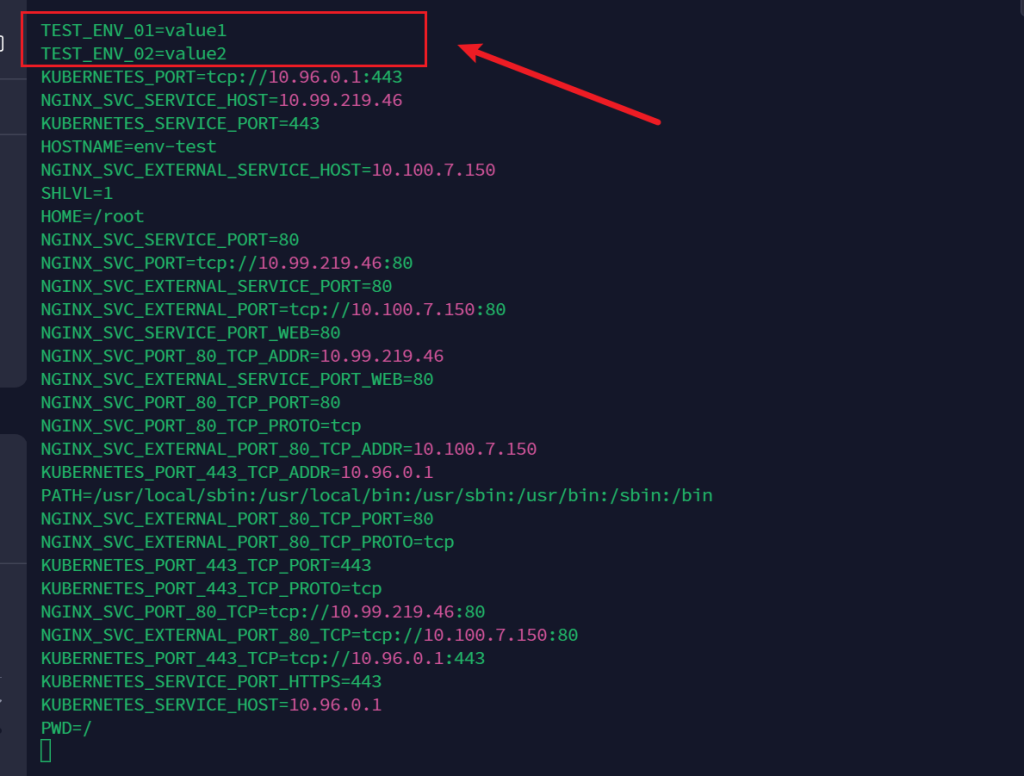
# 表示将key-value-test中的testkey01的值赋给TEST_ENV_01
- name: TEST_ENV_01
valueFrom:
configMapKeyRef:
# configMap的名字
name: key-value-test
# configMap的key值
key: testkey1
- name: TEST_ENV_02
valueFrom:
configMapKeyRef:
# configMap的名字
name: key-value-test
key: testkey2
restartPolicy: Never
创建此pod
这个是上面我们创建的键值对形式。
kubectl create -f env-test.yaml
输出日志
kubectl logs -f env-test
可以看到,确实
下面来试试加载配置文件到容器
vim file-test.yaml
配置如下
apiVersion: v1
kind: Pod
metadata:
name: file-test
spec:
containers:
- name: file-test
# 轻量级nginx
image: alpine
command: ["/bin/sh","-c","env;sleep 3600"]
imagePullPolicy: IfNotPresent
env:
# 表示将key-value-test中的testkey01的值赋给TEST_ENV_01
- name: TEST_ENV_01
valueFrom:
configMapKeyRef:
# configMap的名字
name: key-value-test
# configMap的key值
key: testkey1
- name: TEST_ENV_02
valueFrom:
configMapKeyRef:
# configMap的名字
name: key-value-test
key: testkey2
# 加载数据卷,加载下面配置的
volumeMounts:
# 下面配置的数据卷名字
- name: file-config
# 加载到容器中哪个目录
mountPath: "/usr/local/cc/"
# 是否可读
readOnly: true
# 数据卷挂载configmap 、secret
volumes:
# 数据卷名字,随便起
- name: file-config
configMap:
# configMap名字
name: dir-name
# 默认将configMap的key全部变为同名文件
# 配置了items,则只会将设置的变为文件
items:
- key: "pei.yaml"
# 将configMap的key变为同名文件
path: "pei.yaml"
restartPolicy: Never
创建
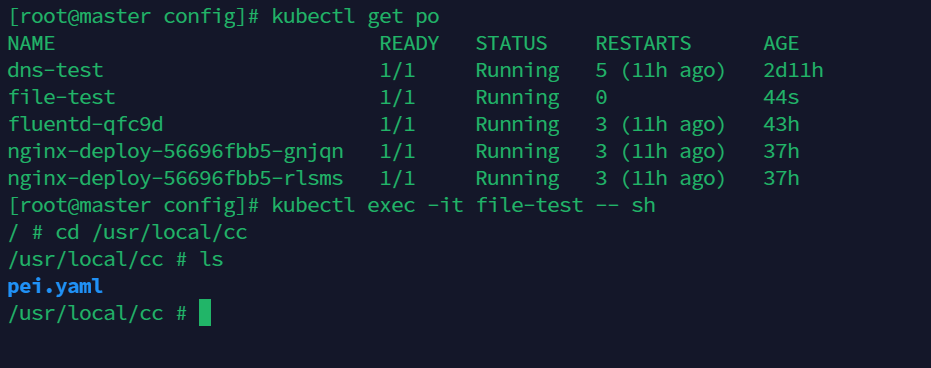
kubectl create -f file-test.yaml
进入其中查看是否存在目录
kubectl get po
kubectl exec -it file-test -- sh
cd /usr/local/cc
ls
如图
输入exit退出
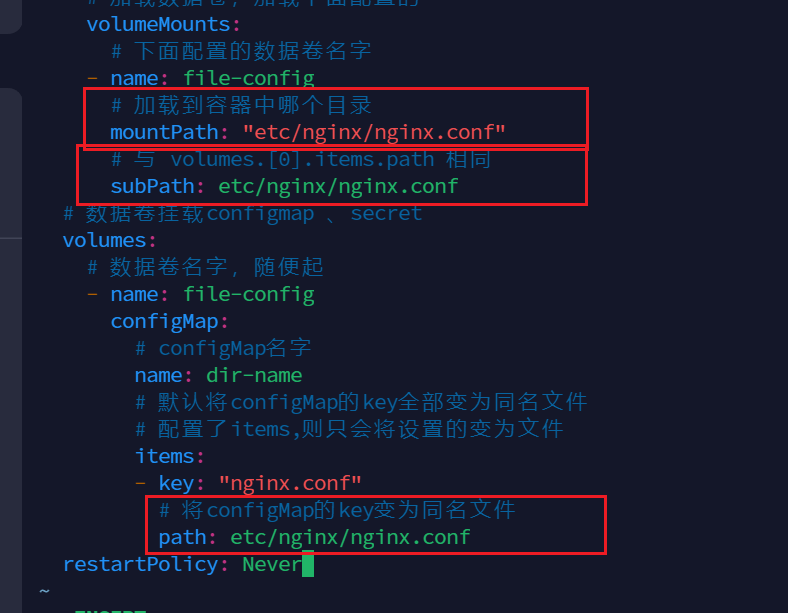
解决方法就是加入增加 subPath 属性
- 定义 volumes 时需要增加 items 属性,配置 key 和 path,且 path 使用绝对路径
- 在容器内的 volumeMounts 中增加 subPath 属性,该值与 volumes 中 items.path 的值相同
比如配置nginx内部配置文件
subPath: etc/nginx/nginx.conf
Secret
Secret 是一种包含少量敏感信息例如密码、令牌或密钥的对象。 这样的信息可能会被放在 Pod 规约中或者镜像中。 使用 Secret 意味着你不需要在应用程序代码中包含机密数据。
由于创建 Secret 可以独立于使用它们的 Pod, 因此在创建、查看和编辑 Pod 的工作流程中暴露 Secret(及其数据)的风险较小。 Kubernetes 和在集群中运行的应用程序也可以对 Secret 采取额外的预防措施, 例如避免将敏感数据写入非易失性存储。
Secret 类似于 ConfigMap 但专门用于保存机密数据。
用法
kubectl create secret -h
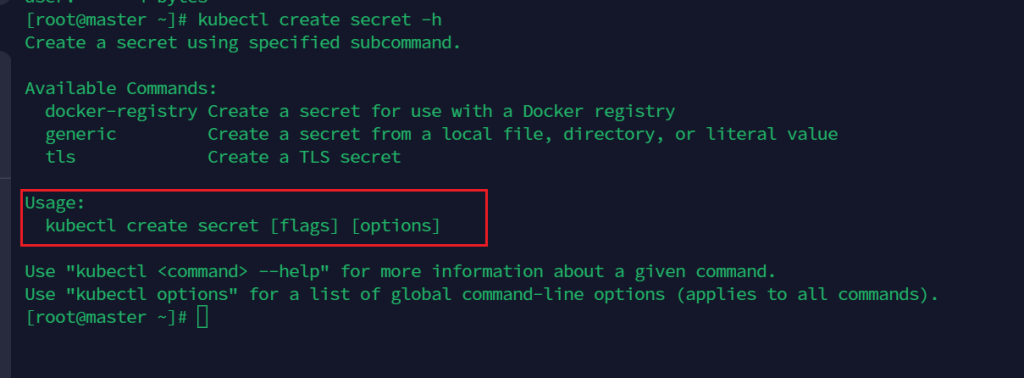
Available Commands:
- docker-registry 创建一个用于Docker注册表的secret
- generic 从本地文件、目录或文字值创建
- tls 创建TLS密钥
用法一:
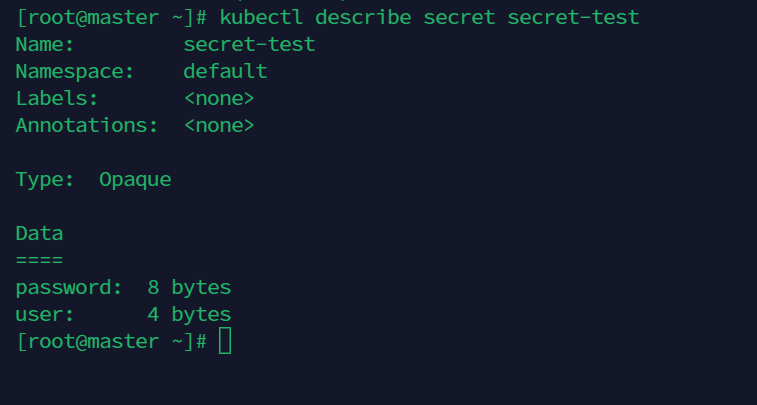
generic 参数
kubectl create secret generic secret-test --from-literal=user=Mike --from-literal=password='gs@!--55'
kubectl describe secret secret-teat
如图看不到加密信息
用法二:
docker-registry 创建一个用于Docker注册表的secret
testname是名字, –docker-username后接账户名 –docker-password后接密码 –docker-email后接邮箱 –docker-server后接地址
kubectl create secret docker-registry testname --docker-username=admin --docker-password=123456 --docker-email=testtest@qq.com --docker-server=8.134.121.241:8858
使用编辑查看内容
kubectl edit secret testname
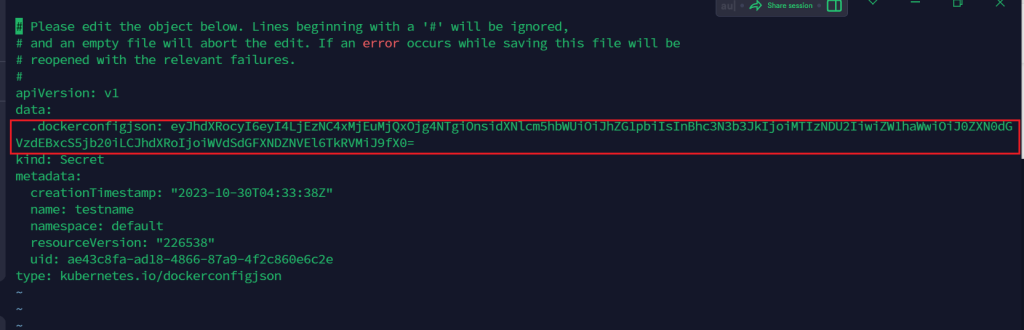
对其解密
echo 'eyJhdXRocyI6eyI4LjEzNC4xMjEuMjQxOjg4NTgiOnsidXNlcm5hbWUiOiJhZG1pbiIsInBhc3N3b3JkIjoiMTIzNDU2IiwiZW1haWwiOiJ0ZXN0dGVzdEBxcS5jb20iLCJhdXRoIjoiWVdSdGFXNDZNVEl6TkRVMiJ9fX0=' | base64 --decode

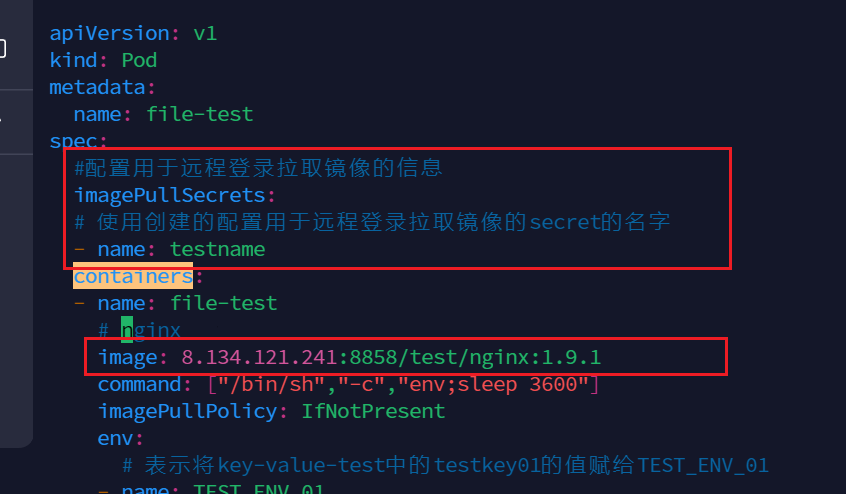
如果我们需要远程拉取私有镜像,可以如图加入此配置,层级关系如图
#配置用于远程登录拉取镜像的信息 imagePullSecrets: # 使用创建的配置用于远程登录拉取镜像的secret的名字 - name: testname
配置相关
更新操作
问题又来了
作为 configmap 然后挂载到 pod,如果更新 configmap 中的配置
- 默认会更新,更新周期是更新时间 + 缓存时间
- 使用subPath不会更新
- 变量形式:如果 pod 中的一个变量是从 configmap 或 secret 中得到则不会更新
由于 configmap 我们创建通常都是基于文件创建,因此无法实现基于源配置文件的替换,
此时我们可以利用下方的命令实现
- –dry-run 参数可以打印 yaml 文件,
- -oyaml 输出 yaml 文件
- 再结合 replace 监听控制台输出得到 yaml 数据即可实现替换
如:
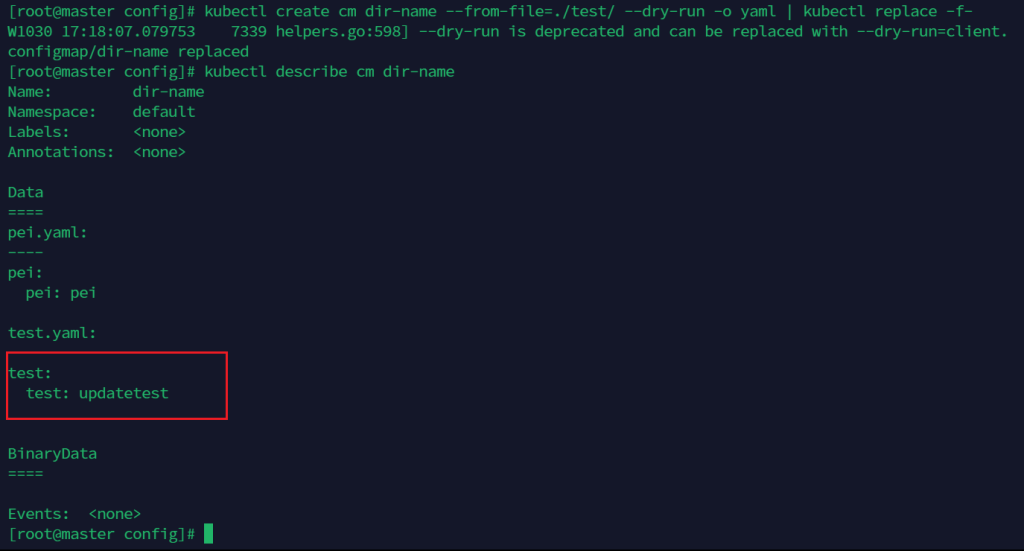
vim test.yaml
随便改下
kubectl describe cm dir-name
可以看到还没改
使用如下命令
kubectl create cm dir-name --from-file=./test/ --dry-run -o yaml | kubectl replace -f-
可以看到更新了
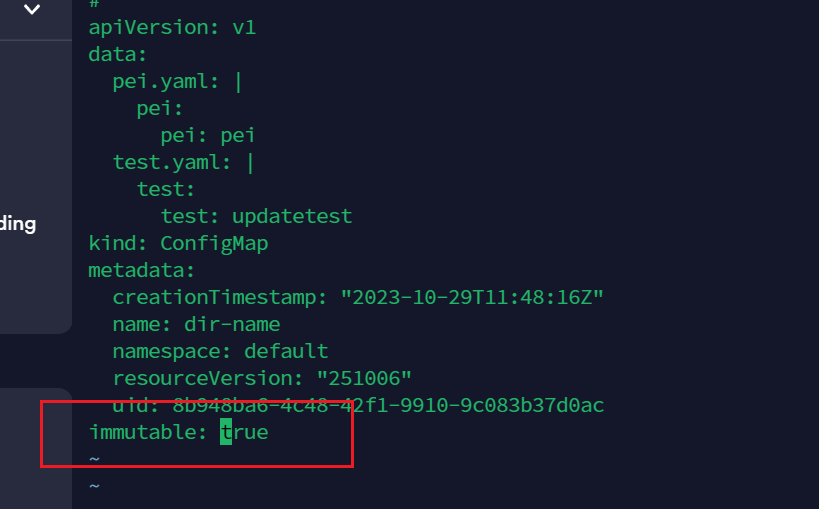
不可变
编辑
kubectl edit cm dir-name
只要加入一个参数即可
immutable:true
7.存储管理
Volumes
HostPath
将节点上的文件或目录挂载到 Pod 上,即使 Pod 被删除后重启,也不会丢失.
创建
mkdir /opt/k8s/volumes
cd /opt/k8s/volumes
vim hostPath.yaml
配置如下
apiVersion: v1
kind: Pod
metadata:
name: hostpath-test
spec:
containers:
- image: nginx
name: nginx-volume
volumeMounts:
# 挂载到容器的哪个目录
- mountPath: /test-pd
# 挂载哪个 volume
name: test-volume
volumes:
- name: test-volume
hostPath:
# 与主机共享目录,加载到容器
path: /data
# 检查类型,在挂载前对挂载目录做什么检查操作,有多种选项,默认为空字符串,不做任何检查
type: DirectoryOrCreate
如上配置,/test-pd就是容器里的目录,/data就是主机目录。
type: 类型:
- 空字符串:默认类型,不做任何检查
- DirectoryOrCreate:如果给定的 path 不存在,就创建一个权限设置为 0755的空目录
- Directory:在给定路径上必须存在的目录
- FileOrCreate:如果给定的文件不存在,则创建一个空文件,权限为 644
- File:这个文件必须存在
- Socket:在给定路径上必须存在的 UNIX 套接字。
- CharDevice:在给定路径上必须存在的字符设备。
- BlockDevice:在给定路径上必须存在的块设备。
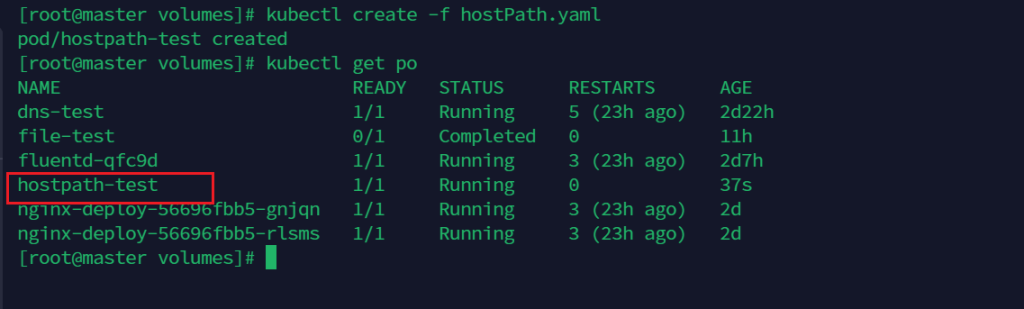
开始创建
kubectl create -f hostPath.yaml
注意:
无论对容器里/test-pd下的修改,还是主机上的/data下的修改,都会使对方同样更改。
主机上的/data是指部署了这个pod的主机
EmptyDir
EmptyDir 主要用于一个 Pod 中不同的容器共享数据使用的,只是在 Pod 内部使用。
编辑配置文件
vim empty-dir.yaml
配置如下
apiVersion: v1
kind: Pod
metadata:
name: empty-dir
spec:
containers:
- image: alpine
name: nginx-emptydir-1
command: ["/bin/sh","-c","sleep 3000;"]
volumeMounts:
# 映射到容器中哪个目录
- mountPath: /cache
name: cache-volume
- image: alpine
name: nginx-emptydir-2
command: ["/bin/sh","-c","sleep 3000;"]
volumeMounts:
- mountPath: /opt
name: cache-volume
volumes:
- name: cache-volume
emptyDir: {}如上配置那么容器nginx-emptydir-1的/cache目录就与容器nginx-emptydir-2的/opt目录共享
NFS 挂载
nfs 卷能将 NFS (网络文件系统) 挂载到Pod 中。 在删除 Pod 时会被保存,数据可以在 Pod 之间共享。
在需要使用nfs 卷的主机安装
安装 nfs
yum install nfs-utils -y
我这里安装master和node1
启动 nfs
systemctl start nfs-server

查看 nfs 版本
cat /proc/fs/nfsd/versions

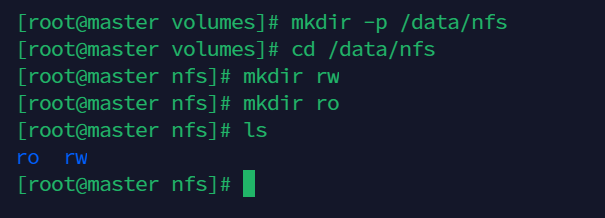
创建共享目录,在master节点
mkdir -p /data/nfs
cd /data/nfs
mkdir rw
mkdir ro
设置共享目录 export,
vim /etc/exports
配置如下,172.31.7.0是网段,rw是可读写权限,ro是可读权限
/data/nfs/rw 172.31.7.0/24(rw,sync,no_subtree_check,no_root_squash)
/data/nfs/ro 172.31.7.0/24(ro,sync,no_subtree_check,no_root_squash)
在master节点重新加载nfs配置
exportfs -f
systemctl reload nfs-server
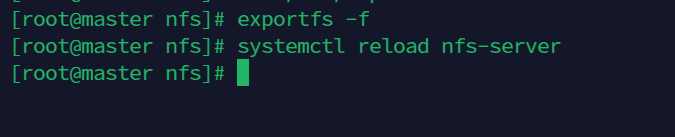
同时在ro目录下随便创建一个文件供测试
cd ro
touch test.txt
echo "Hello k8s" > test.txt
到其他比如node1,测试
mkdir -p /mnt/nfs/ro
mkdir -p /mnt/nfs/rw
mount -t nfs 172.31.7.240:/data/nfs/rw /mnt/nfs/rw
mount -t nfs 172.31.7.240:/data/nfs/ro /mnt/nfs/ro

可以看到成功挂载了
cd /mnt/nfs/ro
ls
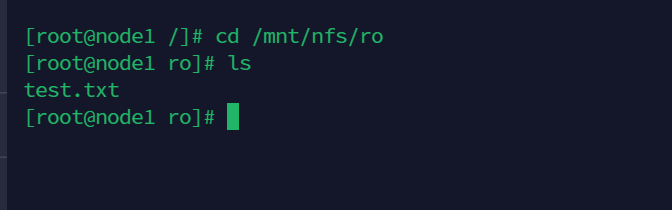
同时这里只可读
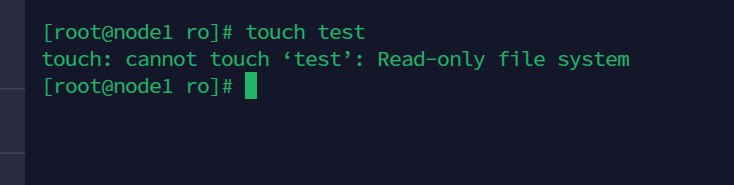
现在再来挂载到容器
cd /opt/k8s/volumes/
vim nfs-test.yaml
配置如下
apiVersion: v1
kind: Pod
metadata:
name: nfs-test
spec:
containers:
- image: nginx
name: test-container
volumeMounts:
- mountPath: /usr/share/nginx/html
name: test-volume
volumes:
- name: test-volume
nfs:
server: 172.31.7.240 # 网络存储服务地址
path: /data/nfs/rw # 网络存储路径
readOnly: false # 是否只读
启动
kubectl create -f nfs-test.yaml
进入容器
kubectl exec -it nfs-test -- sh
可以看到确实共享了
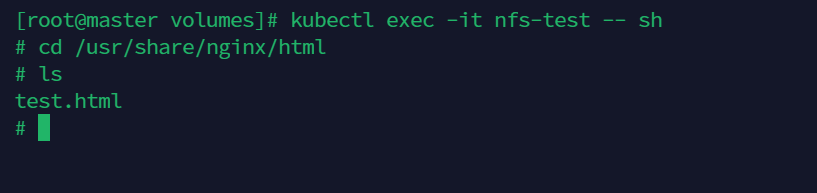
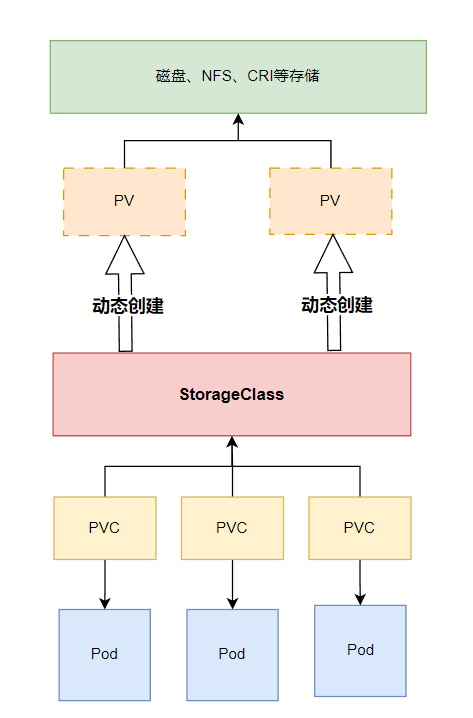
PV 与PVC
官网对其的描述
持久卷(PersistentVolume,PV) 是集群中的一块存储,可以由管理员事先制备, 或者使用存储类(Storage Class)来动态制备。 持久卷是集群资源,就像节点也是集群资源一样。PV 持久卷和普通的 Volume 一样, 也是使用卷插件来实现的,只是它们拥有独立于任何使用 PV 的 Pod 的生命周期。 此 API 对象中记述了存储的实现细节,无论其背后是 NFS、iSCSI 还是特定于云平台的存储系统。
持久卷申领(PersistentVolumeClaim,PVC) 表达的是用户对存储的请求。概念上与 Pod 类似。 Pod 会耗用节点资源,而 PVC 申领会耗用 PV 资源。Pod 可以请求特定数量的资源(CPU 和内存);同样 PVC 申领也可以请求特定的大小和访问模式。
大致如图:
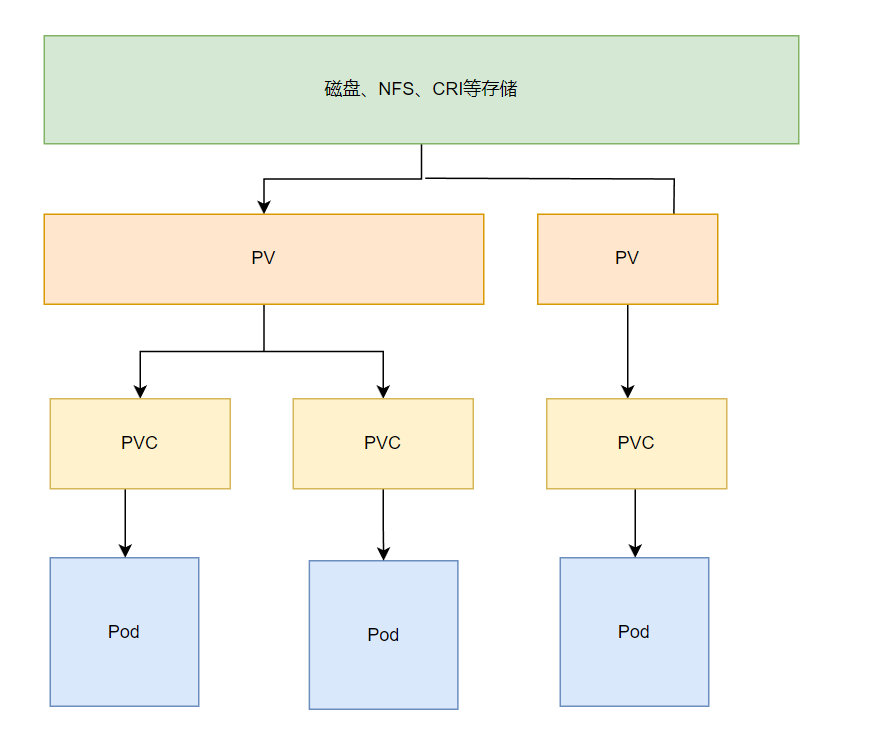
每个持久卷会处于以下阶段(Phase)之一:
- Available:卷是一个空闲资源,尚未绑定到任何申领pvc
- Bound:该卷已经绑定到某申领pvc
- Released:所绑定的申领pvc已被删除,但是关联存储资源尚未被集群回收
- Failed:卷的自动回收操作失败
通过创建看看它的状态
静态制备
集群管理员创建若干 PV 卷。这些卷对象带有真实存储的细节信息, 并且对集群用户可用(可见)。PV 卷对象存在于 Kubernetes API 中,可供用户消费(使用)
配置文件
创建pv
cd /opt/k8s/volumes/
vim pv-nfs.yaml
配置如下
apiVersion: v1
kind: PersistentVolume
metadata:
name: pv0001
spec:
capacity:
storage: 5Gi # pv 的容量
volumeMode: Filesystem # 存储类型为文件系统
accessModes: # 访问模式:ReadWriteOnce、ReadWriteMany、ReadOnlyMany
- ReadWriteMany # 可被单节点独写
persistentVolumeReclaimPolicy: Retain # 回收策略
storageClassName: slow # 创建 PV 的存储类名,需要与 pvc 的相同
mountOptions: # 加载配置
- hard
- nfsvers=4.1
nfs: # 连接到 nfs
path: /data/nfs/rw/test-pv # 存储路径
server: 172.31.7.240 # nfs 服务地址
如上配置:PersistentVolume 卷可以用资源提供者所支持的任何方式挂载到宿主系统上。
访问模式有:
- ReadWriteOnce:卷可以被一个节点以读写方式挂载。 ReadWriteOnce 访问模式也允许运行在同一节点上的多个 Pod 访问卷。
- ReadOnlyMany:卷可以被多个节点以只读方式挂载。
- ReadWriteMany:卷可以被多个节点以读写方式挂载。
- ReadWriteOncePod:卷可以被单个 Pod 以读写方式挂载。 如果你想确保整个集群中只有一个 Pod 可以读取或写入该 PVC, 请使用 ReadWriteOncePod 访问模式。这只支持 CSI 卷以及需要 Kubernetes 1.22 以上版本。
回收策略
当用户不再使用其存储卷时,他们可以从 API 中将 PVC 对象删除, 从而允许该资源被回收再利用。PersistentVolume 对象的回收策略告诉集群, 当其被从申领中释放时如何处理该数据卷。 目前,数据卷可以被 Retained(保留)、Recycled(回收)或 Deleted(删除)。
目前的回收策略有:
- Retain — 手动回收
- Recycle — 基本擦除 (rm -rf /thevolume/*)
- Delete — 诸如 AWS EBS 或 GCE PD 卷这类关联存储资产也被删除
目前,仅 NFS 和 HostPath 支持回收(Recycle)。 AWS EBS 和 GCE PD 卷支持删除(Delete)。
存储路径在/data/nfs/rw/test-pv
在master创建
mkdir -p /data/nfs/rw/test-pv
创建pv
kubectl create -f pv-nfs.yaml
获取pv
kubectl get pv

创建pvc
vim pvc-test.yaml
配置如下
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: nfs-pvc
spec:
accessModes:
# 权限需要与对应的 pv 相同
- ReadWriteMany
volumeMode: Filesystem
resources:
requests:
# 资源可以小于 pv 的,但是不能大于,如果大于就会匹配不到 pv
storage: 5Gi
# 名字需要与对应的 pv 相同
storageClassName: slow
# selector: # 使用选择器选择对应的 pv
# # matchLabels:
# # release: "stable"
# # matchExpressions:
# # - {key: environment, operator: In, values: [dev]}创建
kubectl create -f pvc-test.yaml
查看
kubectl get pvc
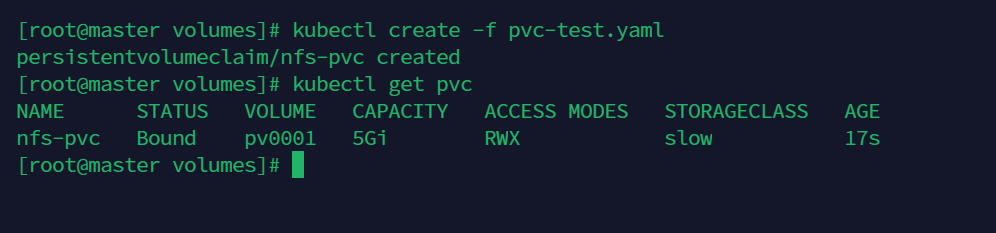
注意看,匹配上,就变成了Bound

而真正的用法就是绑定在Pod上
vim pod-pvc-pv.yaml
配置如下
apiVersion: v1
kind: Pod
metadata:
name: pod-pvc-pv
spec:
containers:
- image: nginx
name: nginx-volume
volumeMounts:
# 挂载到容器的哪个目录
- mountPath: /usr/share/nginx/html
# 挂载哪个 volume
name: test-volume
volumes:
- name: test-volume
# 关联pvc
persistentVolumeClaim:
claimName: nfs-pvc # pvc 的名称创建
kubectl create -f pod-pvc-pv.yaml
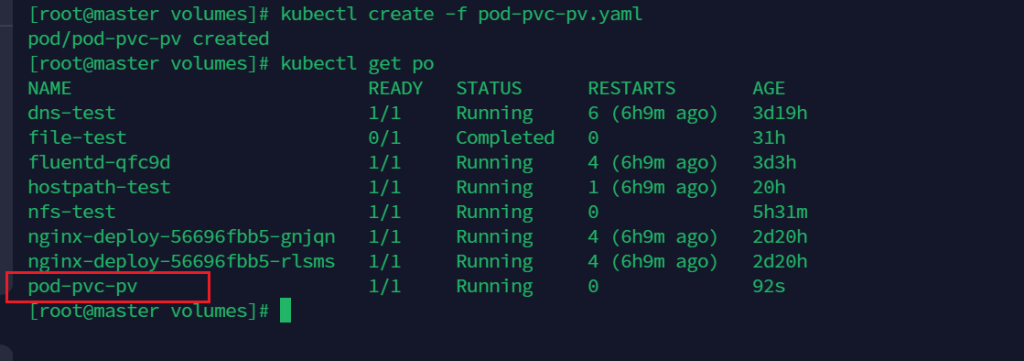
这样就可以共享了
在node1创建

在master可以看到
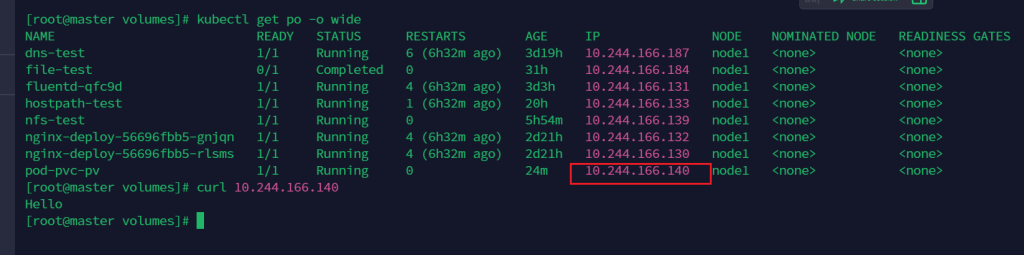
动态制备
使用StorageClass ,如果管理员所创建的所有静态 PV 卷都无法与用户的 PersistentVolumeClaim 匹配, 集群就会为该 PVC 申领动态制备一个存储卷。
8.高级调度
CronJob
CronJob 创建基于时隔重复调度的 Job。
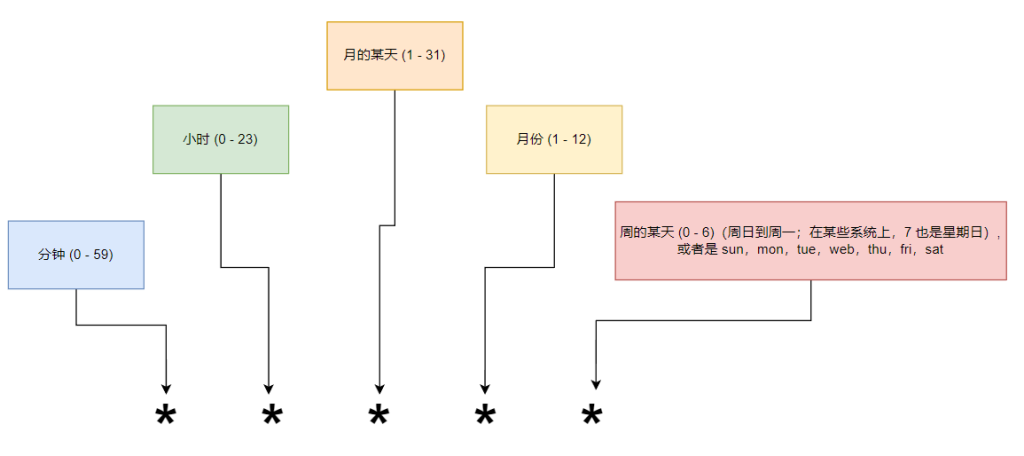
在 k8s 中周期性运行计划任务,类似 linux 中的 crontab 相同
.spec.schedule 字段是必需的。该字段的值遵循 Cron 语法:
创建配置文件
mkdir /opt/k8s/jobs
cd /opt/k8s/jobs
vim cronjob-test.yaml
配置如下
apiVersion: batch/v1
kind: CronJob
metadata:
name: hello
spec:
# 并发调度策略:Allow 允许并发调度,Forbid:不允许并发执行,Replace:如果之前的任务还没执行完,就直接执行新>的,放弃上一个任务
concurrencyPolicy: Allow
# 保留多少个失败的任务
failedJobsHistoryLimit: 1
# 保留多少个成功的任务
successfulJobHistoryLimit: 3
# 是否挂起任务,若为 true 则该任务不会执行
suspend: false
# 间隔多长时间检测失败的任务并重新执行,时间不能小于 10
# startingDeadlineSeconds: 30
# 调度策略
schedule: "* * * * *"
# 任务模板,具体执行什么
jobTemplate:
spec:
template:
spec:
containers:
- name: hello
image: busybox:1.28
imagePullPolicy: IfNotPresent
command:
- /bin/sh
- -c
- date; echo Hello from the Kubernetes cluster
restartPolicy: OnFailure运行
kubectl create -f cronjob-test.yaml

查看cronjob
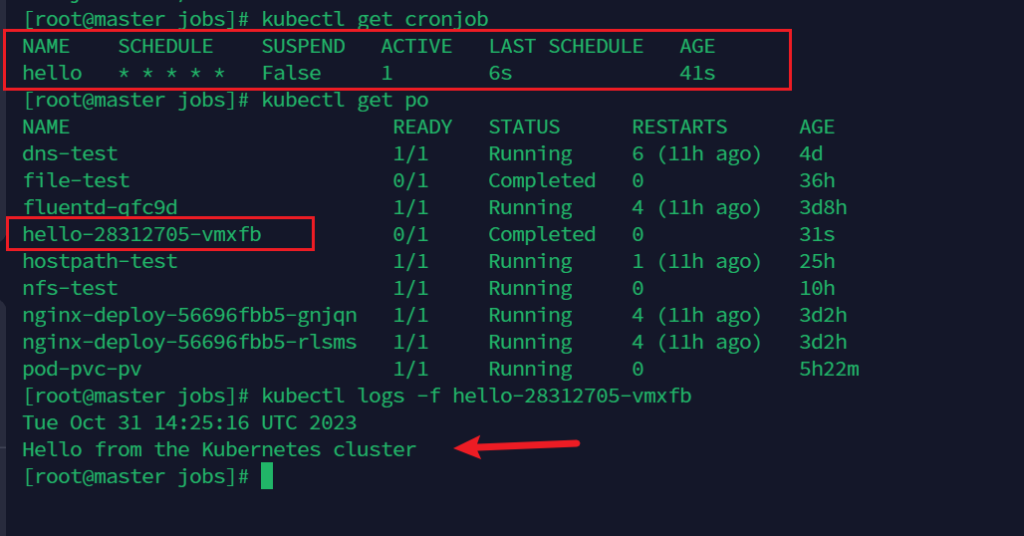
kubectl get cronjob
查看指定pod日志
kubectl logs -f hello-28312705-vmxfb
如果不使用记得删除,否则会不断执行
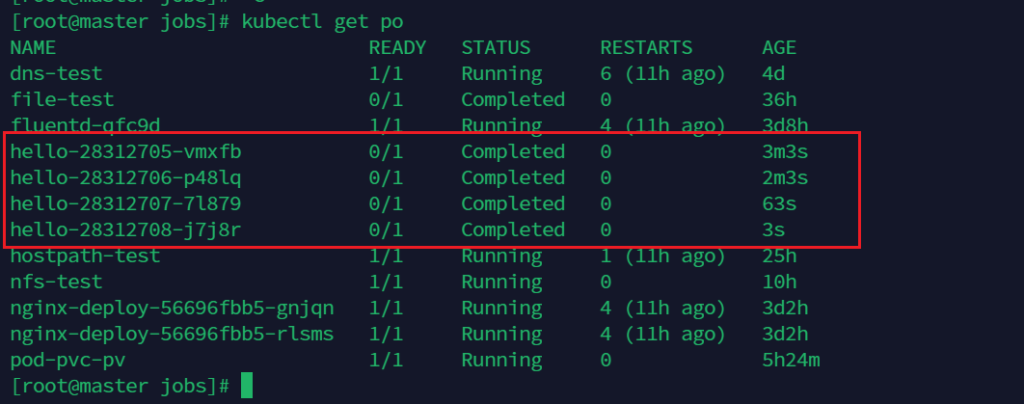
删除
kubectl delete cronjob hello

污点容忍
污点(Taint)使节点能够排斥一类特定的 Pod。
容忍度(Toleration) 是应用于 Pod 上的。容忍度允许调度器调度带有对应污点的 Pod。
污点和容忍度(Toleration)相互配合,可以用来避免 Pod 被分配到不合适的节点上。 每个节点上都可以应用一个或多个污点,这表示对于那些不能容忍这些污点的 Pod, 是不会被该节点接受的。
污点
当满足一些条件时,节点控制器会自动给节点添加一个污点。
内置的污点包括:
- node.kubernetes.io/not-ready:节点未准备好。这相当于节点状况 Ready 的值为 “False”。
- node.kubernetes.io/unreachable:节点控制器访问不到节点. 这相当于节点状况 Ready 的值为 “Unknown”。
- node.kubernetes.io/memory-pressure:节点存在内存压力。
- node.kubernetes.io/disk-pressure:节点存在磁盘压力。
- node.kubernetes.io/pid-pressure:节点的 PID 压力。
- node.kubernetes.io/network-unavailable:节点网络不可用。
- node.kubernetes.io/unschedulable:节点不可调度。
- node.cloudprovider.kubernetes.io/uninitialized:如果 kubelet 启动时指定了一个“外部”云平台驱动, 它将给当前节点添加一个污点将其标志为不可用。在 cloud-controller-manager 的一个控制器初始化这个节点后,kubelet 将删除这个污点。
在节点被排空时,节点控制器或者 kubelet 会添加带有 NoExecute 效果的相关污点。 此效果被默认添加到 node.kubernetes.io/not-ready 和 node.kubernetes.io/unreachable 污点中。 如果异常状态恢复正常,kubelet 或节点控制器能够移除相关的污点。
还有比如master节点默认无法部署Pod
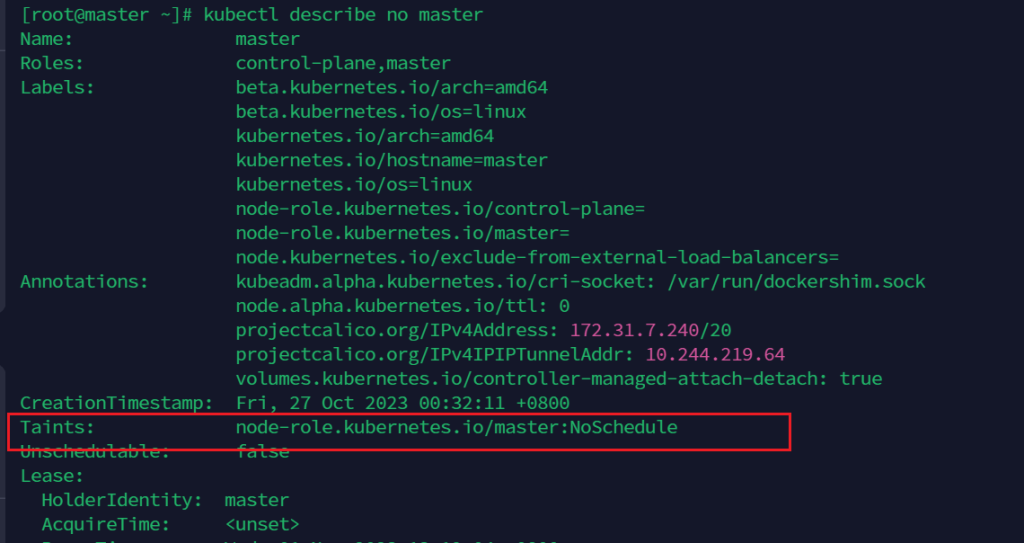
查看master描述
kubectl describe no master
NoExecute:
- 如果 Pod 不能容忍这类污点,会马上被驱逐。
- 如果 Pod 能够容忍这类污点,但是在容忍度定义中没有指定tolerationSeconds, 则 Pod 还会一直在这个节点上运行。
- 如果 Pod 能够容忍这类污点,而且指定了 tolerationSeconds, 则 Pod 还能在这个节点上继续运行这个指定的时间长度。 这段时间过去后,节点生命周期控制器从节点驱除这些 Pod。比如设置了tolerationSeconds: 3600 属性,则该 pod 还能继续在该节点运行 3600 秒
- 这会影响已在节点上运行的 Pod
- NoSchedule:除非具有匹配的容忍度规约,否则新的 Pod 不会被调度到带有污点的节点上。 当前正在节点上运行的 Pod 不会被驱逐。
以上参数可以在打上污点指定
为节点打上污点
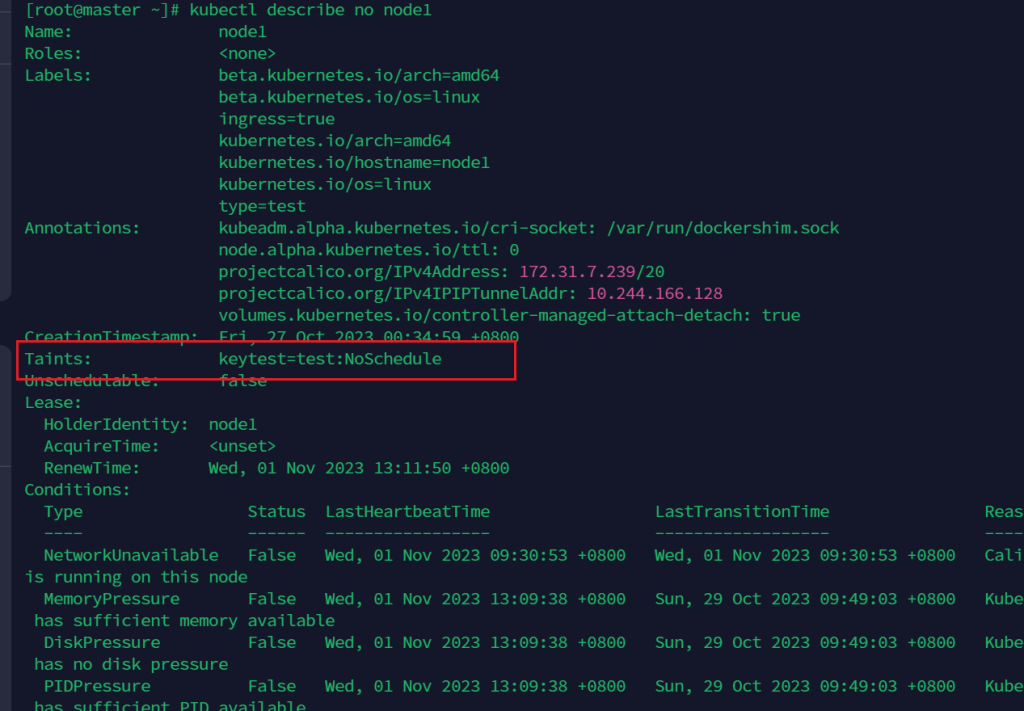
kubectl taint node node1 key=value:NoSchedule

查看污点
kubectl describe no node1
移除污点
kubectl taint node node1 key=value:NoSchedule-

如果想要master节点部署Pod,同样把master默认的污点删除即可
kubectl taint node master node-role.kubernetes.io/master:NoSchedule-

这样之后就可能有Pod会部署到master
容忍
创建并编辑
vim nginx-deploy.yaml
查看上面的写
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app: nginx-deploy
name: nginx-deploy
namespace: default
spec:
# 期望副本数
replicas: 1
# 进行滚动更新后,保留的历史版本数
revisionHistoryLimit: 10
# Selector关联labels
selector:
matchLabels:
app: nginx-deploy
# 更新策略
strategy:
# 滚动更新配置
rollingUpdate:
# 进行滚动更新时,更新的个数最多可以超过期望副本数的个数/比例
maxSurge: 25%
# 进行滚动更新时,最大不可用比例更新比例,表示在所有副本数中,最多可以有多少个不更新成功
maxUnavailable: 25%
# 更新类型,采用滚动更新
type: RollingUpdate
# 创建Pod模板
template:
metadata:
labels:
app: nginx-deploy
spec:
containers:
- image: nginx:1.7.9
imagePullPolicy: IfNotPresent
name: nginx
restartPolicy: Always
terminationGracePeriodSeconds: 30
创建
kubectl create -f nginx-deploy.yaml
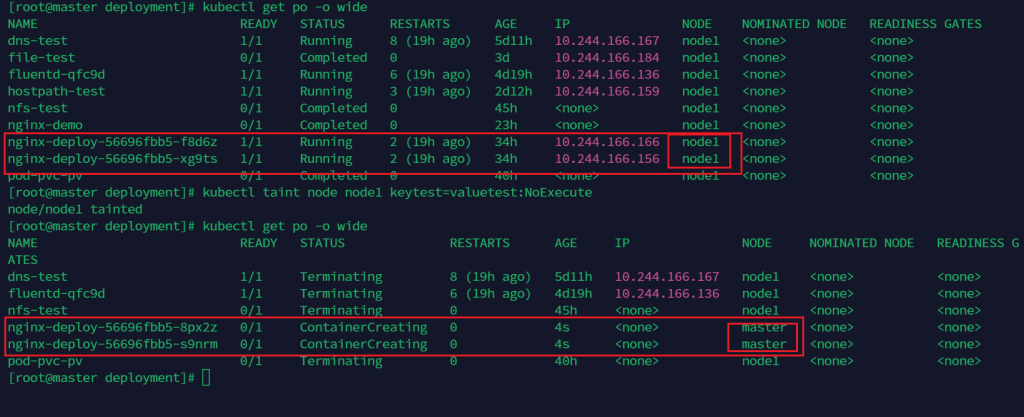
对其打上污点
kubectl taint node node1 keytest=valuetest:NoExecute
可以看到被驱逐到了master,master前面已经删除了污点
添加容忍,注意层级关系,配置Pod,因在tempiate.spec
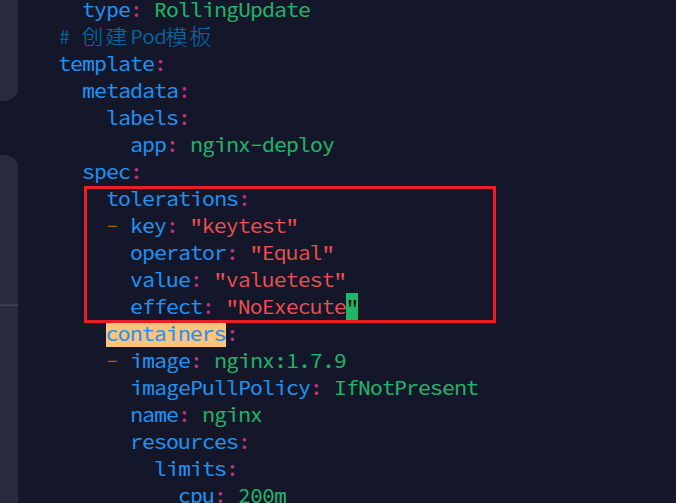
tolerations: - key: "keytest" operator: "Equal" value: "valuetest" effect: "NoExecute"
operator 的默认值是 Equal。
一个容忍度和一个污点相“匹配”是指它们有一样的键名和效果,并且:
- 如果 operator 是 Exists(此时容忍度不能指定 value)
- 如果 operator 是 Equal,则它们的 value 应该相等。
注意:
如果一个容忍度的 key 为空且 operator 为 Exists, 表示这个容忍度与任意的 key、value 和 effect 都匹配,即这个容忍度能容忍任何污点。
如果 effect为空,则可以与所有键名 key的效果相匹配。
删除deploy并重新创建
kubectl delete deploy nginx-deploy
kubectl create -f nginx-deploy.yaml
可以看到可以,可以部署在node1了

如果 Pod 能够容忍这类污点,但是没有指定tolerationSeconds, 则 Pod 会一直在这个节点上运行。
如果 Pod 能够容忍这类污点,但是设置了tolerationSeconds: 3600 属性,则该 pod 还能继续在该节点运行 3600 秒
tolerations: - key: "keytest" operator: "Equal" value: "valuetest" effect: "NoExecute" tolerationSeconds: 3600
亲和力
节点亲和性
节点亲和性可以根据节点上的标签来约束 Pod 可以调度到哪些节点上。 节点亲和性有两种:
- requiredDuringSchedulingIgnoredDuringExecution: 调度器只有在规则被满足的时候才能执行调度。此功能类似于 nodeSelector, 但其语法表达能力更强。
- preferredDuringSchedulingIgnoredDuringExecution: 调度器会尝试寻找满足对应规则的节点。如果找不到匹配的节点,调度器仍然会调度该 Pod。
apiVersion: v1
kind: Pod
metadata:
name: with-node-affinity
spec:
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: topology.kubernetes.io/zone
operator: In
values:
- antarctica-east1
- antarctica-west1
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 1
preference:
matchExpressions:
- key: another-node-label-key
operator: In
values:
- another-node-label-value
- weight:50
preference:
matchExpressions:
- key: another-node-labe2-key
operator: In
values:
- another-node-labe2-value
containers:
- name: with-node-affinity
image: registry.k8s.io/pause:2.0
- requiredDuringSchedulingIgnoredDuringExecution就是必须满足,就是必须存在topology.kubernetes.io/zone的key,operator: In表示value只要在列出的values范围就好
- preferredDuringSchedulingIgnoredDuringExecution:就是满足的优先,
- weight: 1就是权重,含有此标签,权重越高,调度概率就越大。
还有operator的类型:
- In:部署在满足条件的节点上
- NotIn:匹配不在条件中的节点,实现节点反亲和性
- Exists:只要存在 key 名字就可以,不关心值是什么
- DoesNotExist:匹配指定 key 名不存在的节点,实现节点反亲和性
- Gt:value 为数值,且节点上的值小于指定的条件
- Lt :value 为数值,且节点上的值大于指定条件
注意:
nodeSelector 和 nodeAffinity都存在,就必须都要满足, 才能将 Pod 调度到候选节点上。
key和value通过打标签赋值
想要哪个符合要求就给哪个节点打标签
设置标签
kubectl label no node1 another-node-label-key=another-node-label-value
Pod亲和性
apiVersion: v1
kind: Pod
metadata:
name: with-pod-affinity
spec:
affinity:
podAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: security
operator: In
values:
- S1
topologyKey: topology.kubernetes.io/zone
podAntiAffinity:
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 100
podAffinityTerm:
labelSelector:
matchExpressions:
- key: security
operator: In
values:
- S2
topologyKey: topology.kubernetes.io/zone
containers:
- name: with-pod-affinity
image: registry.k8s.io/pause:2.0podAffinity就是Pod 亲和性规则,podAntiAffinity就是 Pod 反亲和性规则
topologyKey: topology.kubernetes.io/zone就是节点必须由带有 topology.kubernetes.io/zone=values标签的节点组成
亲和性规则就是仅当节点和至少一个已运行且有 security-S1 的标签的 Pod 处于同一区域时,才可以将该 Pod 调度到节点上。 而且调度器必须将Pod调度到具有topology.kubernetas.io/zone-v标签的节点上,并且集群中至少有一个位于该可用区的节点上运行着带有security-s1标签的Pod
反亲和性规则表示,如果节点处于 Pod 所在的同一可用区且至少一个 Pod 具有 security-S2 标签,则该 Pod 不应被调度到该节点上。而且如果同一可用区中存在其他运行着带有 security=s2 标签的 Pod 节点,并且节点具有标签topology.kubernetes.io/zone=R,Pod 不能被调度到该节点上。
9.身份认证与权限
认证
- 由 Kubernetes 管理的Service Accounts (服务账户)
- (Users Accounts) 普通账户。
普通账户是假定被外部或独立服务管理的,由管理员分配 keys,用户像使用 Keystone 或 google 账号一样,被存储在包含 usernames 和 passwords 的 list 的文件里。
- 普通帐户是针对(人)用户的,服务账户针对 Pod 进程。
- 普通帐户是全局性。在集群所有namespaces中,名称具有惟一性。
- 通常,群集的普通帐户可以与企业数据库同步,新的普通帐户创建需要特殊权限。服务账户创建目的是更轻量化,允许集群用户为特定任务创建服务账户。
service控制器
Service Account Admission Controller
- 如果 pod 没有设置 ServiceAccount,则将 ServiceAccount 设置为 default。
- 确保 pod 引用的 ServiceAccount 存在,否则将会拒绝请求。
- 如果 pod 不包含任何 ImagePullSecrets,则将ServiceAccount 的 ImagePullSecrets 会添加到 pod 中。
- 为包含 API 访问的 Token 的 pod 添加了一个 volume。
- 把 volumeSource 添加到安装在 pod 的每个容器中,挂载在 /var/run/secrets/kubernetes.io/serviceaccount。
Token Controller
- 观察 serviceAccount 的创建,并创建一个相应的 Secret 来允许 API 访问。
- 观察 serviceAccount 的删除,并删除所有相应的ServiceAccountToken Secret
- 观察 secret 添加,并确保关联的 ServiceAccount 存在,并在需要时向 secret 中添加一个 Token。
- 观察 secret 删除,并在需要时对应 ServiceAccount 的关联
Service Account Controller
Service Account Controller 在 namespaces 里管理ServiceAccount,并确保每个有效的 namespaces 中都存在一个名为 “default” 的 ServiceAccount。
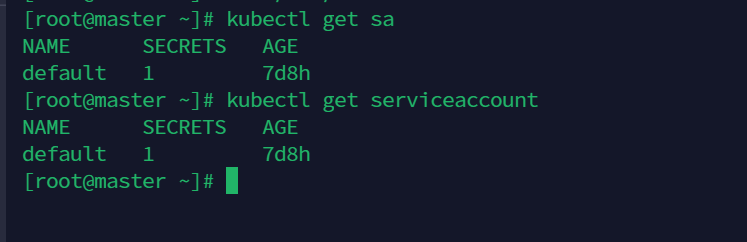
获取Service Account
kubectl get sa
kubectl get serviceaccount
授权(RBAC)
Role
代表一个角色,会包含一组权限,没有拒绝规则,只是附加允许。它是 Namespace 级别的资源,只能作用与 Namespace 之内。
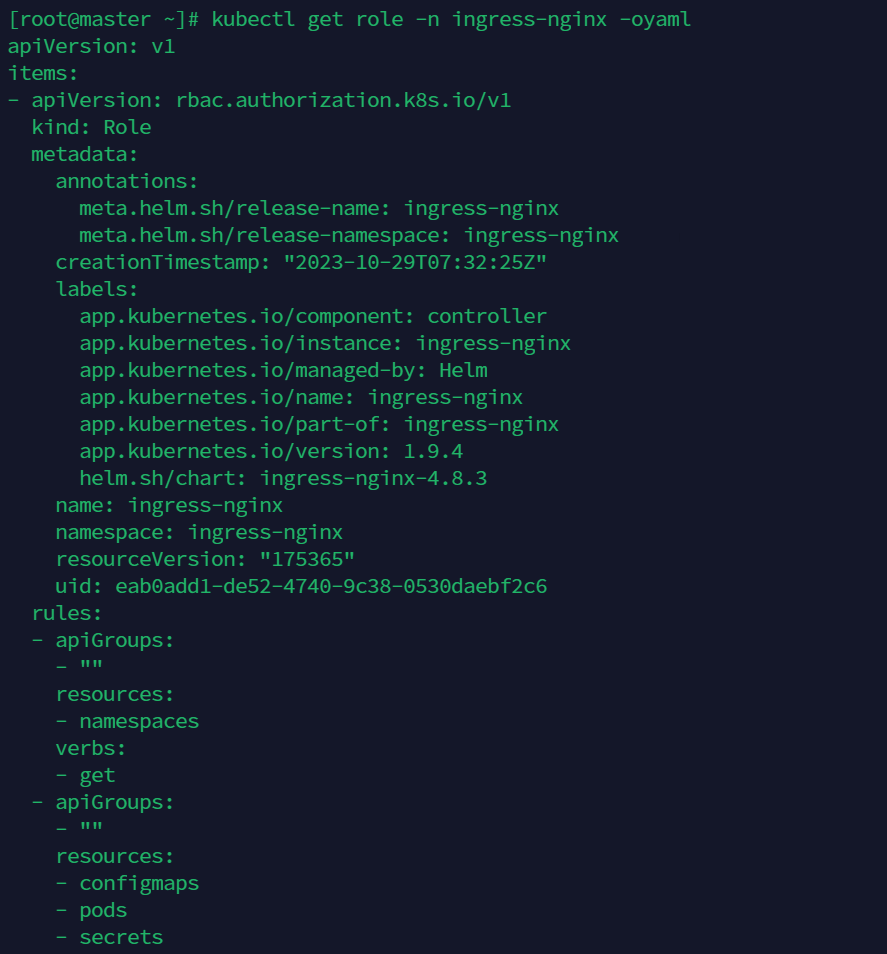
查看已有的角色信息
kubectl get role -n ingress-nginx -oyaml
参考配置
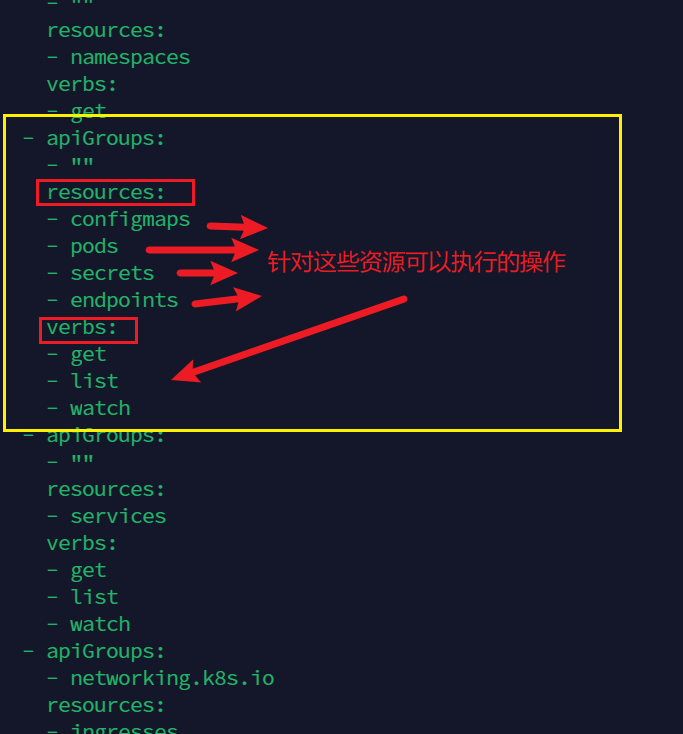
apiVersion: rbac.authorization.k8s.io/v1 kind: Role metadata: labels: app.kubernetes.io/name: ingress-nginx app.kubernetes.io/part-of: ingress-nginx name: nginx-ingress namespace: ingress-nginx roles: - apiGroups: - "" resources: - configmaps - pods - secrets - namespaces verbs: - get - apiGroups: - "" resourceNames: - ingress-controller-label-nginx resources: - configmaps verbs: - get - update - apiGroups: - "" resources: - configmaps verbs: - create
ClusterRole
功能与 Role 一样,区别是资源类型为集群类型,而 Role 只在 Namespace
查看集群角色
kubectl get clusterrole
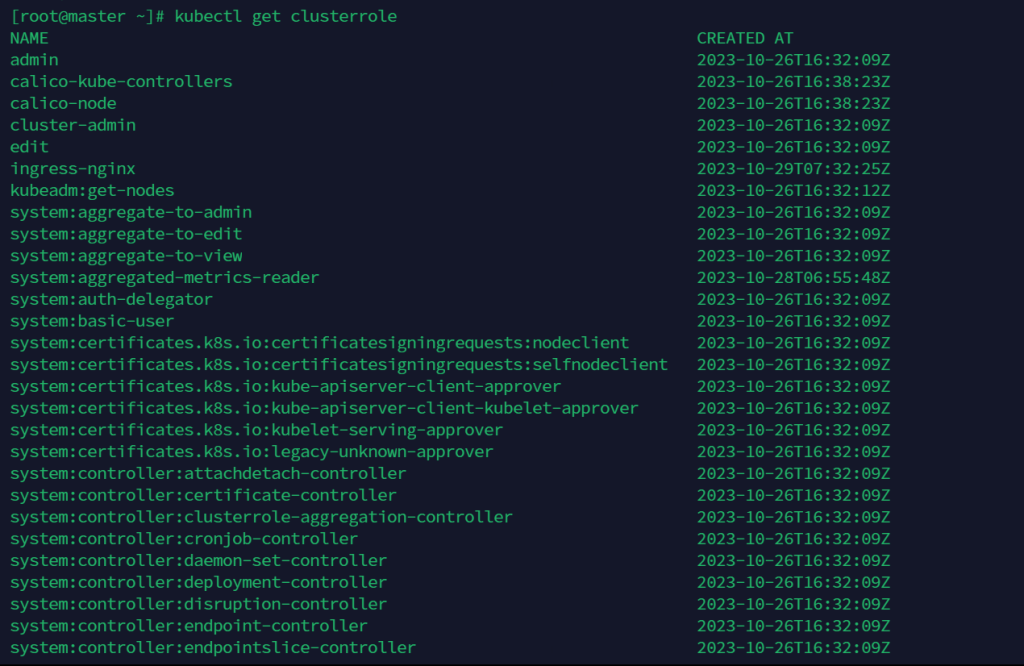
查看某个集群角色的信息
kubectl get clusterrole view -oyaml
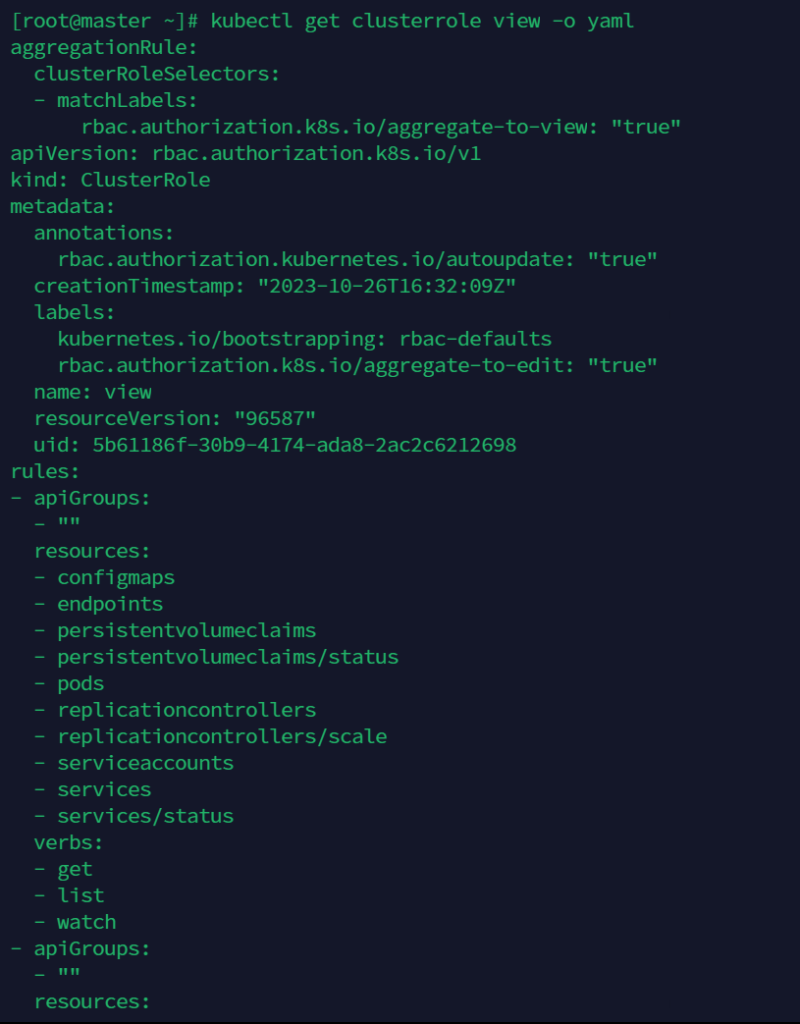
RoleBinding
Role 或 ClusterRole 只是用于制定权限集合,具体作用与什么对象上,需要使用 RoleBinding 来进行绑定。
作用于 Namespace 内,可以将 Role 或 ClusterRole 绑定到 User、Group、Service Account 上。
查看 rolebinding 信息
kubectl get rolebinding --all-namespaces
kubectl get rolebinding -A
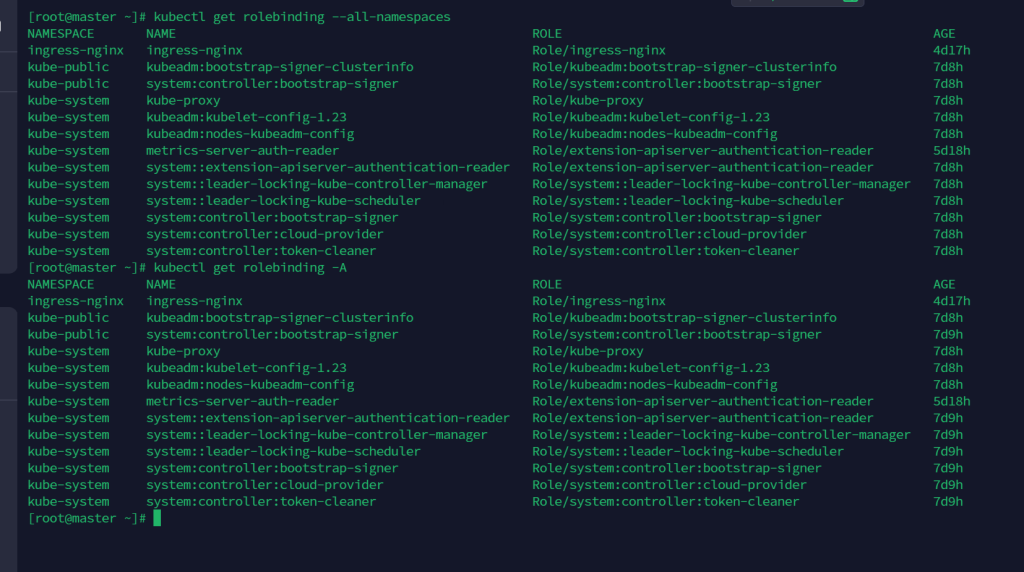
查看指定 rolebinding 的配置信息
kubectl get rolebinding <role_binding_name> --all-namespaces -oyaml
参考配置
apiVersion: rbac.authorization.k8s.io/v1 kind: RoleBinding metadata: ...... roleRef: apiGroup: rbac.authorization.k8s.io kind: Role name nginx-ingress-role subjects: - kind: ServiceAccount name: nginx-ingress-serviceaccount namespace: ingress-nginx
ClusterRoleBinding
与 RoleBinding 相同,但是作用于集群之上,可以绑定到该集群下的任意 User、Group 或 Service Account
10.Helm包管理
Helm 是查找、分享和使用软件构件 Kubernetes 的最优方式。
对于Helm,有三个重要的概念:
- chart 创建Kubernetes应用程序所必需的一组信息。
- config 包含了可以合并到打包的chart中的配置信息,用于创建一个可发布的对象。
- release 是一个与特定配置相结合的chart的运行实例。
安装
创建工作目录
mkdir /opt/k8s/helm
cd /opt/k8s/helm
下载Helm
wget https://get.helm.sh/helm-v3.2.3-linux-amd64.tar.gz
不过使用wget直接下载很慢,所以可以下载再上传到主机
再上传
ls
解压
tar -zxvf helm-v3.13.1-linux-amd64.tar.gz
然后将其移至所需的目标位置
cp linux-amd64/helm /usr/local/bin/
验证是否成功
helm version
基本命令
列出、增加、更新、删除 chart 仓库
helm repo --help

Available Commands:
- add :添加图表存储库生成索引文件
- index :给定一个包含打包图表
- list :列表的目录,图表存储库
- remove :删除一个或多个图表存储库,从图表存储库本地
- update :更新可用图表的信息
添加仓库
helm repo add ingress-nginx https://kubernetes.github.io/ingress-nginx
helm repo add bitnami https://charts.bitnami.com/bitnami
helm repo add aliyun https://apphub.aliyuncs.com/stable
helm repo add azure http://mirror.azure.cn/kubernetes/charts
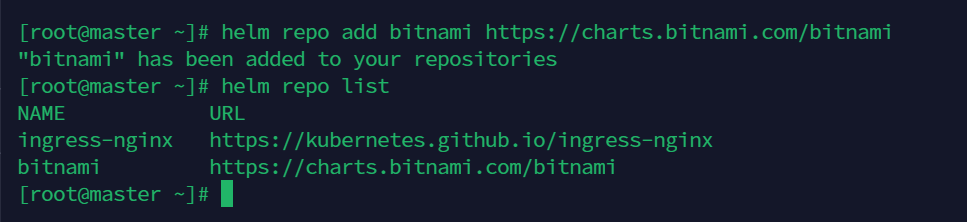
查看仓库列表
helm repo list

使用关键词搜索 chart
helm search --help

Available Commands:
- hub :在Artifact Hub中搜索图表,或者在您自己的Hub实例中
- repo :搜索存储库中图表中的关键字
helm search hub mysql
拉取远程仓库中的 chart 到本地
helm pull
在本地创建新的 chart
helm create
管理 chart 依赖
helm dependency
安装 chart
helm install
列出所有 release
helm list
检查 chart 配置是否有误
helm lint
打包本地 chart
helm package
回滚release到历史版本
helm rollback
卸载 release
helm uninstall
升级 release
helm upgrade
参考:
官网链接:Kubernetes
完整版Kubernetes(K8S)全套入门+微服务实战项目,带你一站式深入掌握K8S核心能力_哔哩哔哩_bilibili