1.无锁并发
看看一个例子:
package cn.yutian.test;
import java.util.ArrayList;
import java.util.List;
import java.util.concurrent.atomic.AtomicInteger;
public class TestAccount {
public static void main(String[] args) {
Account account = new AccountUnsafe(10000);
Account.demo(account);
}
}
class AccountUnsafe implements Account {
private Integer balance;
public AccountUnsafe(Integer balance) {
this.balance = balance;
}
@Override
public Integer getBalance() {
return this.balance;
}
@Override
public void withdraw(Integer amount) {
this.balance -= amount;
}
}
interface Account {
// 获取余额
Integer getBalance();
// 取款
void withdraw(Integer amount);
/**
* 方法内会启动 1000 个线程,每个线程做 -10 元 的操作
* 如果初始余额为 10000 那么正确的结果应当是 0
*/
static void demo(Account account) {
List<Thread> ts = new ArrayList<>();
for (int i = 0; i < 1000; i++) {
ts.add(new Thread(() -> {
account.withdraw(10);
}));
}
long start = System.nanoTime();
ts.forEach(Thread::start);
ts.forEach(t -> {
try {
t.join();
} catch (InterruptedException e) {
e.printStackTrace();
}
});
long end = System.nanoTime();
System.out.println(account.getBalance()
+ " cost: " + (end-start)/1000_000 + " ms");
}
}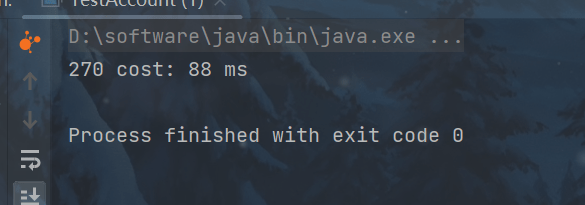
很明显线程不安全,解决方法也很简单,加锁就行
@Override
public Integer getBalance() {
synchronized (this) {
return this.balance;
}
}
@Override
public void withdraw(Integer amount) {
synchronized (this) {
this.balance -= amount;
}
}
无锁的解决方案:
class AccountCas implements Account {
private AtomicInteger balance;
public AccountCas(int balance) {
this.balance = new AtomicInteger(balance);
}
@Override
public Integer getBalance() {
return balance.get();
}
@Override
public void withdraw(Integer amount) {
while(true) {
// 获取余额的最新值
int prev = balance.get();
// 要修改的余额
int next = prev - amount;
// 真正修改
if(balance.compareAndSet(prev, next)) {
break;
}
}
}
}局部变量并没有同步到主存中
使用balance.compareAndSet(prev, next),才能使next同步到主存中,同时成功就中断循环,失败就继续循环
JUC包提供了一系列的原子性操作类,这些类都是使用非阻塞算法CAS实现的,相比使用锁实现原子性操作这在性能上有很大提高。
CAS 与 volatile
前面看到的 AtomicInteger 的解决方法,内部并没有用锁来保护共享变量的线程安全。那么它是如何实现的呢?
public void withdraw(Integer amount) {
while(true) {
// 需要不断尝试,直到成功为止
while (true) {
// 比如拿到了旧值 1000
int prev = balance.get();
// 在这个基础上 1000-10 = 990
int next = prev - amount;
if (balance.compareAndSet(prev, next)) {
break;
}
}
}
}其中的关键是 compareAndSet,它的简称就是 CAS (也有 Compare And Swap 的说法),它必须是原子操作。
compareAndSet 正是做这个检查,在 set 前,先比较 prev 与当前值不一致了,next 作废,返回 false 表示失败比如,别的线程已经做了减法,当前值已经被减成了 90,那么本线程的这次 90 就作废了,进入 while 下次循环重试一致,以 next 设置为新值,返回 true 表示成功。
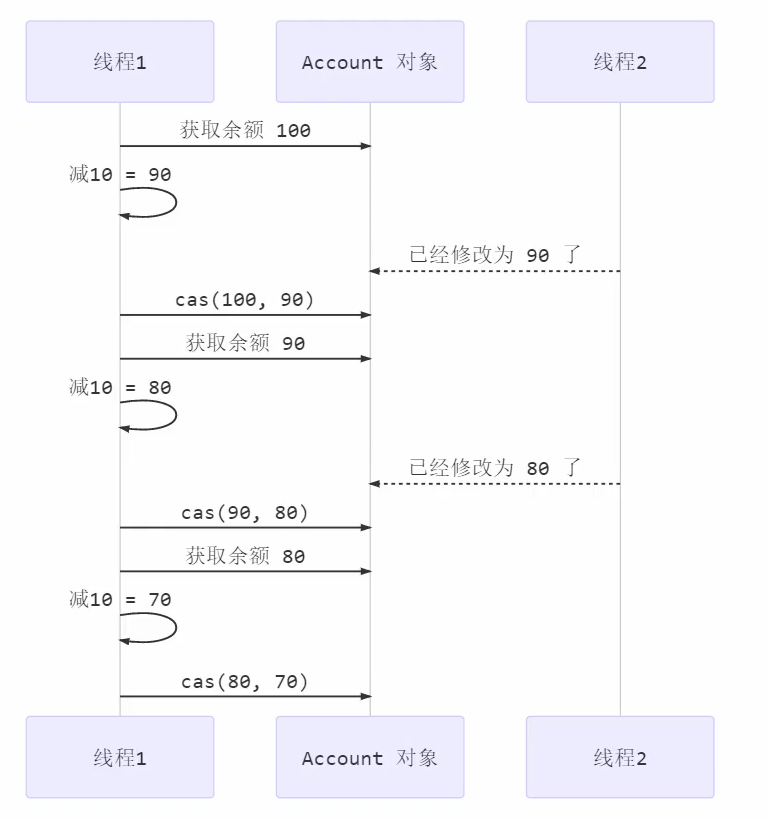
注意:
其实 CAS 的底层是 lock cmpxchg 指令(X86 架构),在单核 CPU 和多核 CPU 下都能够保证比较-交换的原子性。
在多核状态下,某个核执行到带 lock 的指令时,CPU 会让总线锁住,当这个核把此指令执行完毕,再开启总线。这个过程中不会被线程的调度机制所打断,保证了多个线程对内存操作的准确性,是原子的。
volatile
获取共享变量时,为了保证该变量的可见性,需要使用 volatile 修饰。
它可以用来修饰成员变量和静态成员变量,他可以避免线程从自己的工作缓存中查找变量的值,必须到主存中获取它的值,线程操作 volatile 变量都是直接操作主存。即一个线程对 volatile 变量的修改,对另一个线程可见。
注意
- volatile 仅仅保证了共享变量的可见性,让其它线程能够看到最新值,但不能解决指令交错问题(不能保证原子性)
- CAS 必须借助 volatile 才能读取到共享变量的最新值来实现比较并交换的效果
源码:
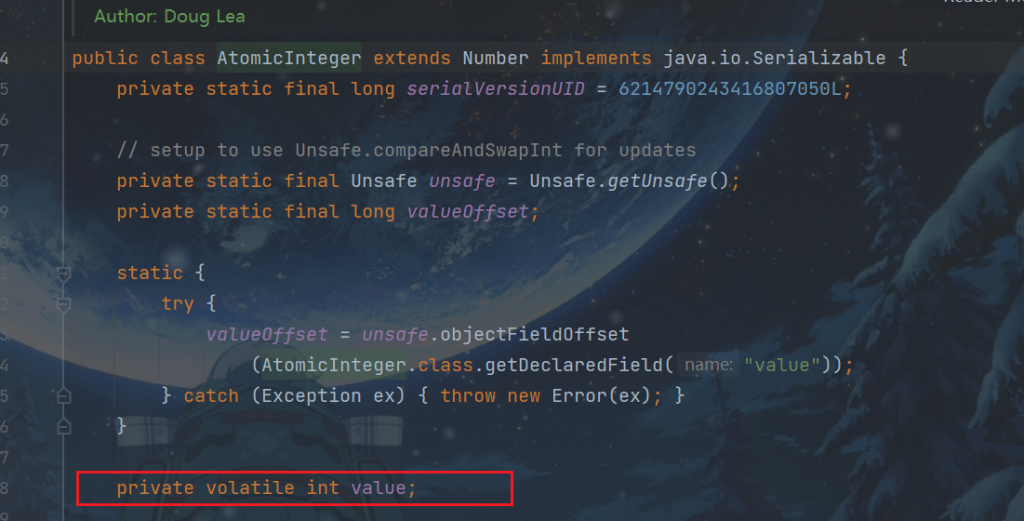
在没有原子类 的情况下, 实现计数器需要使用的一定的同步措施, 如使用synchronized 关键字等,但是这些都是阻塞算法,对性能有一定损耗。
为什么无锁效率高
- 无锁情况下,即使重试失败,线程始终在高速运行,没有停歇,而 synchronized 会让线程在没有获得锁的时候,发生上下文切换,进入阻塞。打个比喻。
- 但无锁情况下,因为线程要保持运行,需要额外 CPU 的支持,CPU 在这里就好比高速跑道,没有额外的跑道,线程想高速运行也无从谈起,虽然不会进入阻塞,但由于没有分到时间片,仍然会进入可运行状态,还是会导致上下文切换。
- 线程数少于CPU数时,无锁效率高。
CAS 的特点:
结合 CAS 和 volatile 可以实现无锁并发,适用于线程数少、多核 CPU 的场景下。
- CAS 是基于乐观锁的思想:最乐观的估计,不怕别的线程来修改共享变量,就算改了也没关系,再重试。
- synchronized 是基于悲观锁的思想:最悲观的估计,得防着其它线程来修改共享变量,上了锁都改不了,解开锁,才有机会。
CAS 体现的是无锁并发、无阻塞并发,因为没有使用 synchronized,所以线程不会陷入阻塞,这是效率提升的因素之一,但如果竞争激烈,重试必然频繁发生,反而效率会受影响。
原子变量操作类
概述:
Unsafe 对象提供了非常底层的,操作内存、线程的方法,Unsafe 对象不能直接调用,只能通过反射获得。
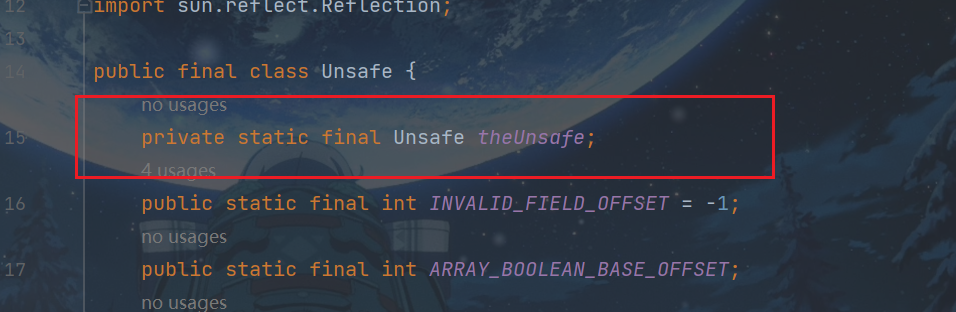
JUC并发包中包含有AtomicInteger, AtomicLong和AtomicBoolean等原子性操作类,它们的原理类似,以 AtomicInteger 为例 ,其内部使用 Unsafe 来实现,我们看下面的代码。
下面重点看下AtomicLong中的主要函数。
1. 递增和递减操作代码(原子性,保证了线程安全)
AtomicInteger i = new AtomicInteger(1);
调用unsafe方法,原子性设置value值为原始值+1,返回值为递增后的值
// 自增并获取(i = 1, 结果 i = 2, 返回 2),类似于 ++i System.out.println(i.incrementAndGet());

调用unsafe方法,原子性设置value值为原始值-1,返回值为递减之后的值
// 自减并获取(i = 2, 结果 i = 1, 返回 1),类似于 --i System.out.println(i.decrementAndGet());
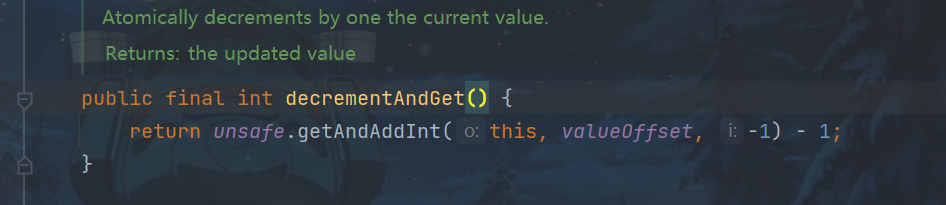
调用unsafe方法,原子性设置value值为原始值+1,返回值为原始值
// 获取并自增(i = 0, 结果 i = 1, 返回 0),类似于 i++ System.out.println(i.getAndIncrement());

还有:
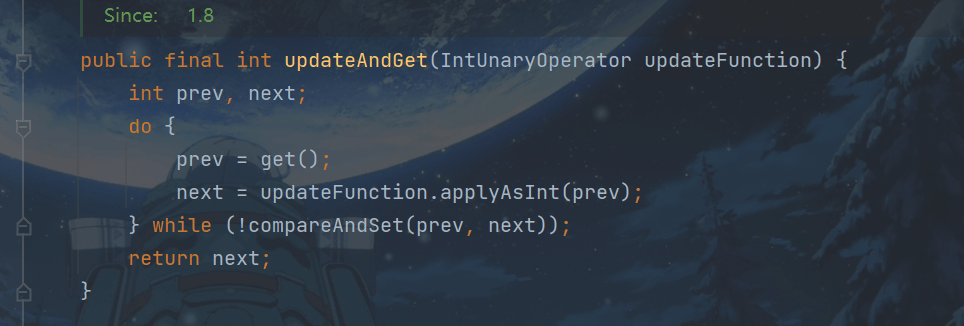
// 获取并自减(i = 1, 结果 i = 0, 返回 1),类似于 i-- System.out.println(i.getAndDecrement()); // 获取并加值(i = 0, 结果 i = 5, 返回 0) System.out.println(i.getAndAdd(5)); // 加值并获取(i = 5, 结果 i = 0, 返回 0) System.out.println(i.addAndGet(-5)); // 获取并更新(i = 0, p 为 i 的当前值, 结果 i = -2, 返回 0) // 其中函数中的操作能保证原子,但函数需要无副作用 //p为读取值,p-2为设置值 System.out.println(i.getAndUpdate(p -> p - 2)); // 更新并获取(i = -2, p 为 i 的当前值, 结果 i = 0, 返回 0) // 其中函数中的操作能保证原子,但函数需要无副作用 System.out.println(i.updateAndGet(p -> p + 2)); // 获取并计算(i = 0, p 为 i 的当前值, x 为参数1, 结果 i = 10, 返回 0) // 其中函数中的操作能保证原子,但函数需要无副作用 // getAndUpdate 如果在 lambda 中引用了外部的局部变量,要保证该局部变量是 final 的 // getAndAccumulate 可以通过 参数1 来引用外部的局部变量,但因为其不在 lambda 中因此不必是 final System.out.println(i.getAndAccumulate(10, (p, x) -> p + x)); // 计算并获取(i = 10, p 为 i 的当前值, x 为参数1, 结果 i = 0, 返回 0) // 其中函数中的操作能保证原子,但函数需要无副作用 System.out.println(i.accumulateAndGet(-10, (p, x) -> p + x));
之前的实现可以改为:
@Override
public void withdraw(Integer amount) {
/*while(true) {
// 获取余额的最新值
int prev = balance.get();
// 要修改的余额
int next = prev - amount;
// 真正修改
if(balance.compareAndSet(prev, next)) {
break;
}
}*/
balance.getAndAdd(-1 * amount);
}i.getAndUpdate(p -> p – 2)原理:
将计算传入
源码:
原子引用
为什么需要原子引用类型?
AtomicReference
AtomicMarkableReference
AtomicStampedReference
package cn.yutian.test;
import lombok.extern.slf4j.Slf4j;
import java.math.BigDecimal;
import java.math.BigInteger;
import java.util.ArrayList;
import java.util.List;
import java.util.concurrent.atomic.AtomicReference;
@Slf4j(topic = "c.Test35")
public class Test35 {
public static void main(String[] args) {
DecimalAccount.demo(new DecimalAccountCas(new BigDecimal("10000")));
}
}
class DecimalAccountCas implements DecimalAccount {
private AtomicReference<BigDecimal> balance;
public DecimalAccountCas(BigDecimal balance) {
// this.balance = balance;
this.balance = new AtomicReference<>(balance);
}
@Override
public BigDecimal getBalance() {
return balance.get();
}
@Override
public void withdraw(BigDecimal amount) {
while(true) {
BigDecimal prev = balance.get();
BigDecimal next = prev.subtract(amount);
if (balance.compareAndSet(prev, next)) {
break;
}
}
}
}
interface DecimalAccount {
// 获取余额
BigDecimal getBalance();
// 取款
void withdraw(BigDecimal amount);
/**
* 方法内会启动 1000 个线程,每个线程做 -10 元 的操作
* 如果初始余额为 10000 那么正确的结果应当是 0
*/
static void demo(DecimalAccount account) {
List<Thread> ts = new ArrayList<>();
for (int i = 0; i < 1000; i++) {
ts.add(new Thread(() -> {
account.withdraw(BigDecimal.TEN);
}));
}
ts.forEach(Thread::start);
ts.forEach(t -> {
try {
t.join();
} catch (InterruptedException e) {
e.printStackTrace();
}
});
System.out.println(account.getBalance());
}
}
ABA 问题及解决
ABA 问题
package cn.yutian.test;
import lombok.extern.slf4j.Slf4j;
import java.util.concurrent.atomic.AtomicReference;
import static cn.yutian.n2.util.Sleeper.sleep;
@Slf4j(topic = "c.Test36")
public class Test36 {
static AtomicReference<String> ref = new AtomicReference<>("A");
public static void main(String[] args) throws InterruptedException {
log.debug("main start...");
// 获取值 A
String prev = ref.get();
// 如果中间有其它线程干扰,发生了 ABA 现象
other();
sleep(1);
// 尝试改为 C
log.debug("change A->C {}", ref.compareAndSet(prev, "C"));
}
private static void other() {
new Thread(() -> {
log.debug("change A->B {}", ref.compareAndSet(ref.get(), "B"));
}, "t1").start();
sleep(0.5);
new Thread(() -> {
log.debug("change B->A {}", ref.compareAndSet(ref.get(), "A"));
}, "t2").start();
}
}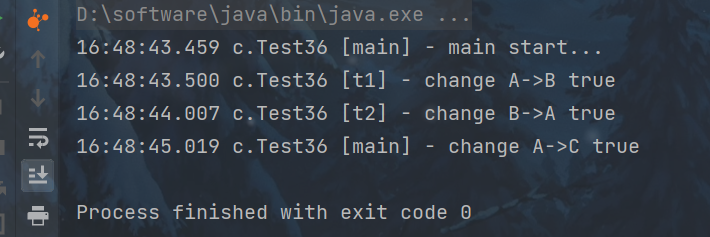
主线程仅能判断出共享变量的值与最初值 A 是否相同,不能感知到这种从 A 改为 B 又 改回 A 的情况,
如果主线程希望:只要有其它线程动过了共享变量,那么自己的 cas 就算失败,这时,仅比较值是不够的,需要再加一个版本号。
package cn.yutian.test;
import lombok.extern.slf4j.Slf4j;
import java.util.concurrent.atomic.AtomicStampedReference;
import static cn.yutian.n2.util.Sleeper.sleep;
@Slf4j(topic = "c.Test36")
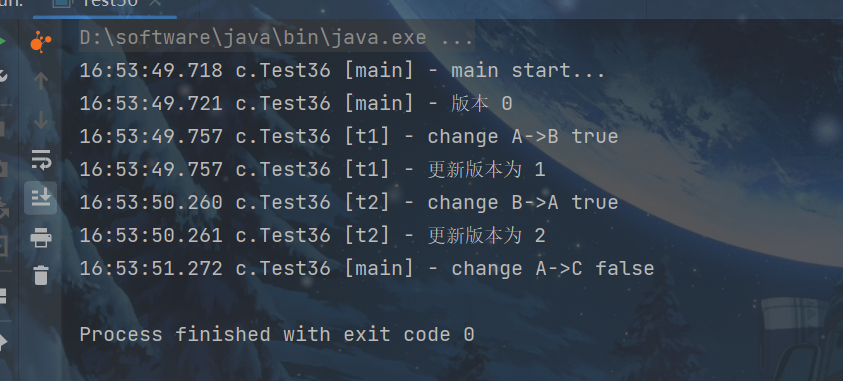
public class Test36 {
static AtomicStampedReference<String> ref = new AtomicStampedReference<>("A", 0);
public static void main(String[] args) throws InterruptedException {
log.debug("main start...");
// 获取值 A
String prev = ref.getReference();
// 获取版本号
int stamp = ref.getStamp();
log.debug("版本 {}", stamp);
// 如果中间有其它线程干扰,发生了 ABA 现象
other();
sleep(1);
// 尝试改为 C
log.debug("change A->C {}", ref.compareAndSet(prev, "C", stamp, stamp + 1));
}
private static void other() {
new Thread(() -> {
log.debug("change A->B {}", ref.compareAndSet(ref.getReference(), "B", ref.getStamp(), ref.getStamp() + 1));
log.debug("更新版本为 {}", ref.getStamp());
}, "t1").start();
sleep(0.5);
new Thread(() -> {
log.debug("change B->A {}", ref.compareAndSet(ref.getReference(), "A", ref.getStamp(), ref.getStamp() + 1));
log.debug("更新版本为 {}", ref.getStamp());
}, "t2").start();
}
}
AtomicMarkableReference
AtomicStampedReference 可以给原子引用加上版本号,追踪原子引用整个的变化过程,如: A -> B -> A ->C ,通过AtomicStampedReference,我们可以知道,引用变量中途被更改了几次。
但是有时候,并不关心引用变量更改了几次,只是单纯的关心是否更改过,所以就有了
AtomicMarkableReference
package cn.yutian.test;
import lombok.extern.slf4j.Slf4j;
import java.util.concurrent.atomic.AtomicMarkableReference;
import static cn.yutian.n2.util.Sleeper.sleep;
@Slf4j(topic = "c.Test38")
public class Test38 {
public static void main(String[] args) throws InterruptedException {
GarbageBag bag = new GarbageBag("装满了垃圾");
// 参数2 mark 可以看作一个标记,表示垃圾袋满了
AtomicMarkableReference<GarbageBag> ref = new AtomicMarkableReference<>(bag, true);
log.debug("start...");
GarbageBag prev = ref.getReference();
log.debug(prev.toString());
new Thread(() -> {
log.debug("start...");
bag.setDesc("空垃圾袋");
ref.compareAndSet(bag, bag, true, false);
log.debug(bag.toString());
},"保洁阿姨").start();
sleep(1);
log.debug("想换一只新垃圾袋?");
boolean success = ref.compareAndSet(prev, new GarbageBag("空垃圾袋"), true, false);
log.debug("换了么?" + success);
log.debug(ref.getReference().toString());
}
}
class GarbageBag {
String desc;
public GarbageBag(String desc) {
this.desc = desc;
}
public void setDesc(String desc) {
this.desc = desc;
}
@Override
public String toString() {
return super.toString() + " " + desc;
}
}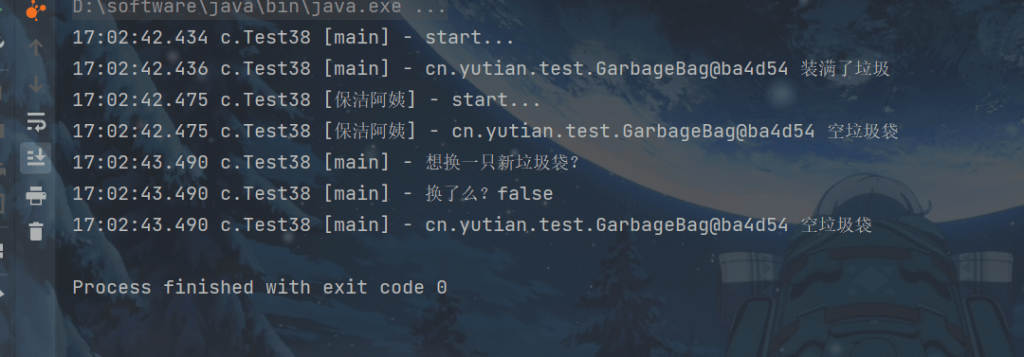
可以注释掉打扫卫生线程代码,再观察输出
原子数组
对数组安全保护
AtomicIntegerArray
AtomicLongArray
AtomicReferenceArray
证明:
package cn.yutian.test;
import java.util.ArrayList;
import java.util.Arrays;
import java.util.List;
import java.util.concurrent.atomic.AtomicIntegerArray;
import java.util.function.BiConsumer;
import java.util.function.Consumer;
import java.util.function.Function;
import java.util.function.Supplier;
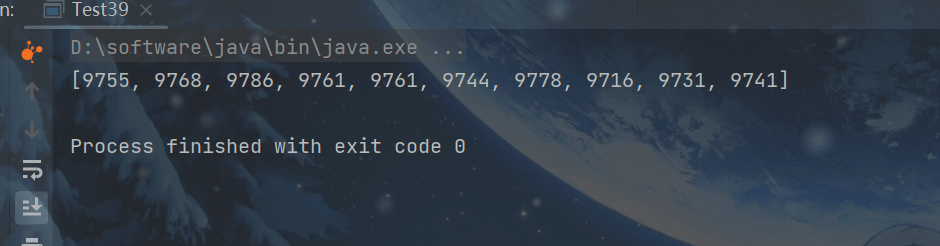
public class Test39 {
public static void main(String[] args) {
demo(
()->new int[10],
(array)->array.length,
(array, index) -> array[index]++,
array-> System.out.println(Arrays.toString(array))
);
}
/**
参数1,提供数组、可以是线程不安全数组或线程安全数组
参数2,获取数组长度的方法
参数3,自增方法,回传 array, index
参数4,打印数组的方法
*/
// supplier 提供者 无中生有 ()->结果
// function 函数 一个参数一个结果 (参数)->结果 , BiFunction (参数1,参数2)->结果
// consumer 消费者 一个参数没结果 (参数)->void, BiConsumer (参数1,参数2)->
private static <T> void demo(
Supplier<T> arraySupplier,
Function<T, Integer> lengthFun,
BiConsumer<T, Integer> putConsumer,
Consumer<T> printConsumer ) {
List<Thread> ts = new ArrayList<>();
T array = arraySupplier.get();
int length = lengthFun.apply(array);
for (int i = 0; i < length; i++) {
// 每个线程对数组作 10000 次操作
ts.add(new Thread(() -> {
for (int j = 0; j < 10000; j++) {
putConsumer.accept(array, j%length);
}
}));
}
ts.forEach(t -> t.start()); // 启动所有线程
ts.forEach(t -> {
try {
t.join();
} catch (InterruptedException e) {
e.printStackTrace();
}
}); // 等所有线程结束
printConsumer.accept(array);
}
}
安全的数组
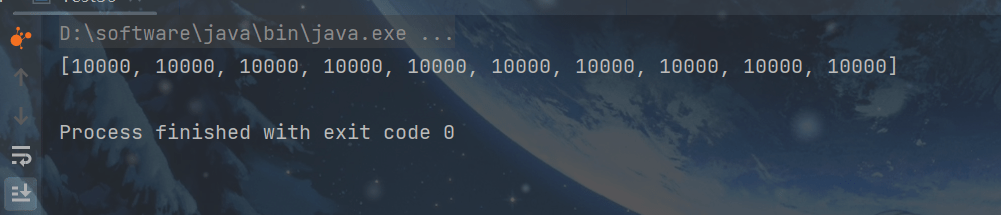
demo(
()-> new AtomicIntegerArray(10),
(array) -> array.length(),
(array, index) -> array.getAndIncrement(index),
array -> System.out.println(array)
);
字段更新器
如果对原子引用的里面元素改变,不能保证安全性。
AtomicReferenceFieldUpdater // 域 字段
AtomicIntegerFieldUpdater
AtomicLongFieldUpdater
package cn.yutian.test;
import lombok.extern.slf4j.Slf4j;
import java.util.concurrent.atomic.AtomicReferenceFieldUpdater;
@Slf4j(topic = "c.Test40")
public class Test40 {
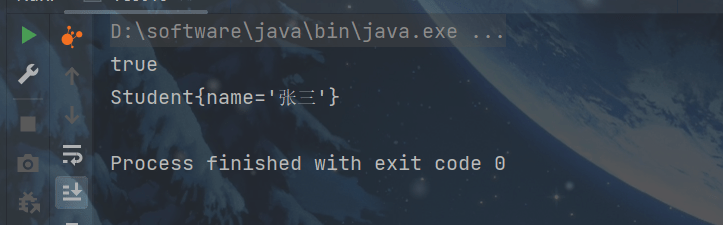
public static void main(String[] args) {
Student stu = new Student();
AtomicReferenceFieldUpdater updater =
//传入参数为类,字段属性,字段名
AtomicReferenceFieldUpdater.newUpdater(Student.class, String.class, "name");
//传入参数对象,原值,设置值
System.out.println(updater.compareAndSet(stu, null, "张三"));
System.out.println(stu);
}
}
class Student {
volatile String name;
@Override
public String toString() {
return "Student{" +
"name='" + name + '\'' +
'}';
}
}
LongAdder
JDK 新增了一个原子操作类 LongAdder。
如 AtomicLong通过CAS提供了非阻塞的原子性操作,相比使用阻塞算法的同步器来说它的性能已经很好了,但是JDK开发组并不满足于此。使用AtomicLong时,在高并发下大量线程会同时去竞争更新同一个原子变量,但是由于同时只有一个线程的CAS操作会成功,这就造成了大量线程竞争失败后,会通过无限循环不断进行自旋尝试CAS的操作,而这会白白浪费CPU资源。
因此JDK 8新增了一个原子性递增或者递减类LongAdder用来克服在高并发下使用AtomicLong的缺点。
既然AtomicLong的性能瓶颈是由于过多线程同时去竞争一个变量的更新而产生的,把一个变量分解为多个变量,让同样多的线程去竞争多个资源,就解决了性能问题。
性能提升的原因很简单,就是在有竞争时,设置多个累加单元,Therad-0 累加 Cell[0],而Thread-1 累加Cell[1]… 最后将结果汇总。这样它们在累加时操作的不同的 Cell 变量,因此减少了 CAS 重试失败,从而提高性能。
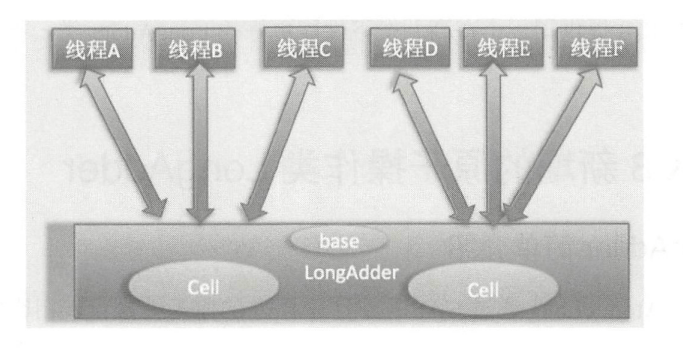
使用LongAdder 时,则是在内部维护多个 Cell变量,每个Cell 里面有一个初始值为0的long型变量,这样,在同等并发量的情况下,争夺单个变量更新操作的线程量会减少,这变相地减少了争夺共享资源的并发量。另外,多个线程在争夺同一个 Cell 原子变量时如果失败了,它并不是在当前 Cell变量上一直自旋 CAS 重试,而是尝试在其他Cell的变量上进行CAS尝试,这个改变增加了当前线程重试CAS成功的可能性。最后,在获取LongAdder当前值时,是把所有Cell变量的value值累加后再加上base返回的。
LongAdder 类有几个关键域
// 累加单元数组, 懒惰初始化 transient volatile Cell[] cells; // 基础值, 如果没有竞争, 则用 cas 累加这个域 transient volatile long base; // 在 cells 创建或扩容时, 置为 1, 表示加锁 transient volatile int cellsBusy;
cas 锁原理;
用0和1表示加没加锁
// 0 没加锁 // 1 加锁 private AtomicInteger state = new AtomicInteger(0);
package cn.yutian.test;
import lombok.extern.slf4j.Slf4j;
import java.util.concurrent.atomic.AtomicInteger;
import static cn.yutian.n2.util.Sleeper.sleep;
@Slf4j(topic = "c.Test42")
public class LockCas {
// 0 没加锁
// 1 加锁
private AtomicInteger state = new AtomicInteger(0);
public void lock() {
while (true) {
if (state.compareAndSet(0, 1)) {
break;
}
}
}
public void unlock() {
log.debug("unlock...");
state.set(0);
}
public static void main(String[] args) {
LockCas lock = new LockCas();
new Thread(() -> {
log.debug("begin...");
lock.lock();
try {
log.debug("lock...");
sleep(1);
} finally {
lock.unlock();
}
}).start();
new Thread(() -> {
log.debug("begin...");
lock.lock();
try {
log.debug("lock...");
} finally {
lock.unlock();
}
}).start();
}
}其中 Cell 即为累加单元:
源码:
cas方法表示改没改。
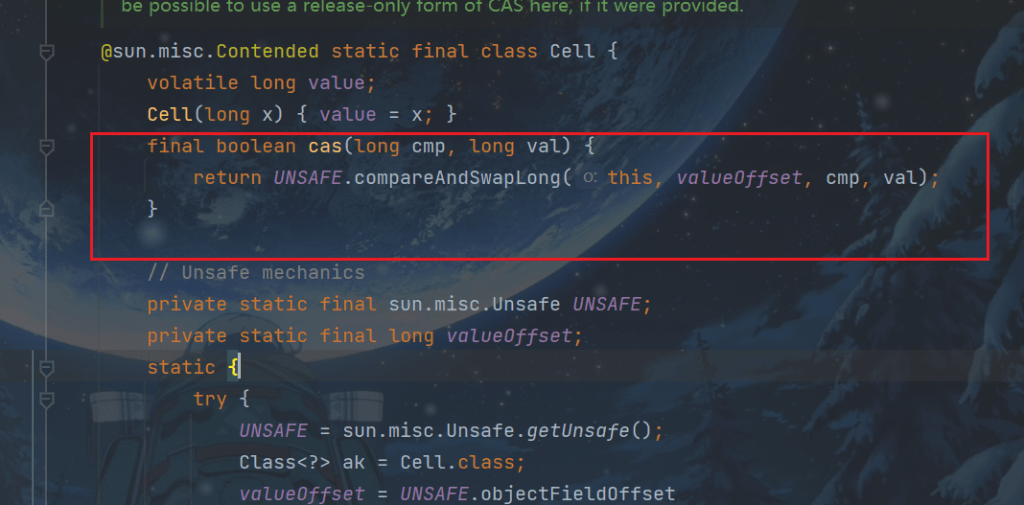
@sun.misc.Contended
static final class Cell {
volatile long value;
Cell(long x) { value = x; }
// 最重要的方法, 用来 cas 方式进行累加, prev 表示旧值, next 表示新值
final boolean cas(long prev, long next) {
return UNSAFE.compareAndSwapLong(this, valueOffset, prev, next);
}
// 省略不重要代码
}此注解解释:
// 防止缓存行伪共享 @sun.misc.Contended
得从缓存说起
缓存与内存的速度比较
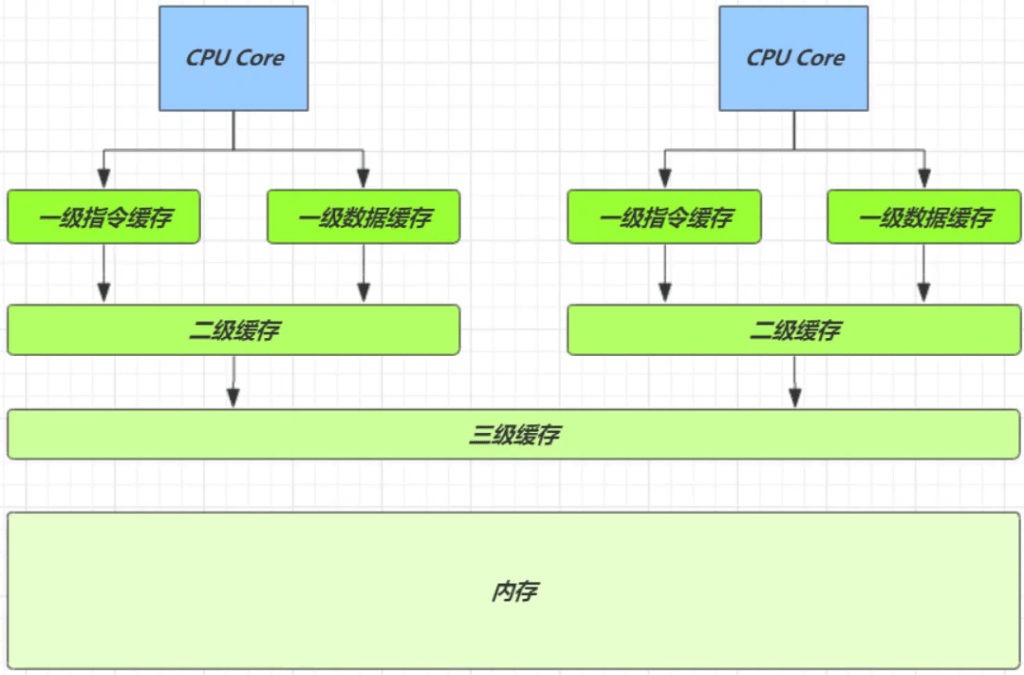

- 因为 CPU 与 内存的速度差异很大,需要靠预读数据至缓存来提升效率。
- 而缓存以缓存行为单位,每个缓存行对应着一块内存,一般是 64 byte(8 个 long)
- 缓存的加入会造成数据副本的产生,即同一份数据会缓存在不同核心的缓存行中
- CPU 要保证数据的一致性,如果某个 CPU 核心更改了数据,其它 CPU 核心对应的整个缓存行必须失效
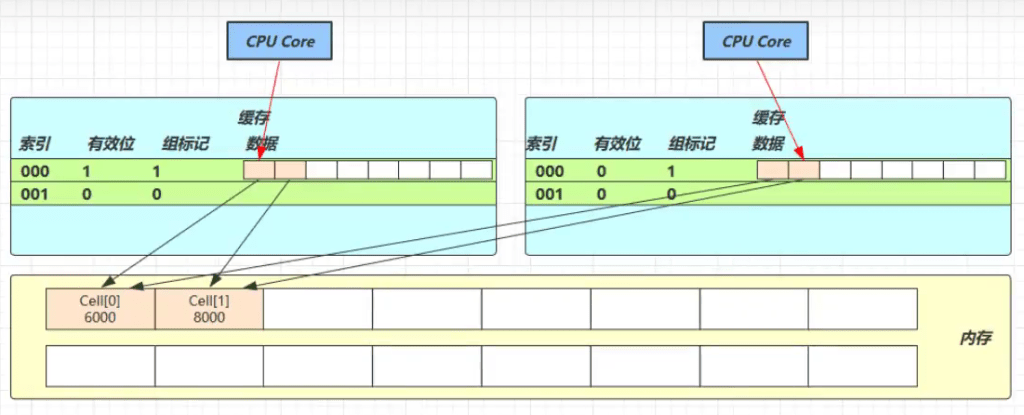
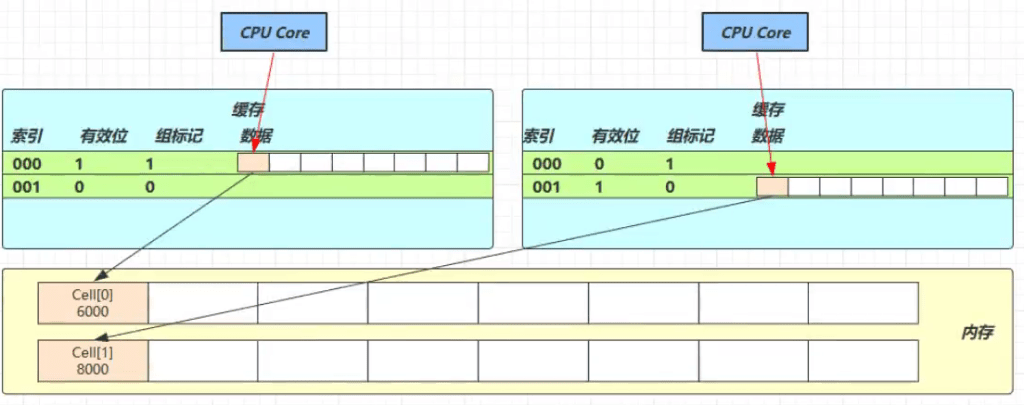
因为 Cell 是数组形式,在内存中是连续存储的,一个 Cell 为 24 字节(16 字节的对象头和 8 字节的 value),因此缓存行可以存下 2 个的 Cell 对象。这样问题来了:
Core-0 要修改 Cell[0]
Core-1 要修改 Cell[1]
无论谁修改成功,都会导致对方 Core 的缓存行失效,比如 Core-0 中 Cell[0]=6000, Cell[1]=8000 要累加Cell[0]=6001, Cell[1]=8000 ,这时会让 Core-1 的缓存行失效.
@sun.misc.Contended 用来解决这个问题,它的原理是在使用此注解的对象或字段的前后各增加 128 字节大小的padding,因为每个缓存行对应着一块内存,一般是 64 byte(8 个 long),从而让 CPU 将对象预读至缓存时占用不同的缓存行,这样,不会造成对方缓存行的失效
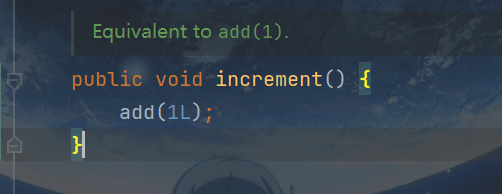
查看源码:
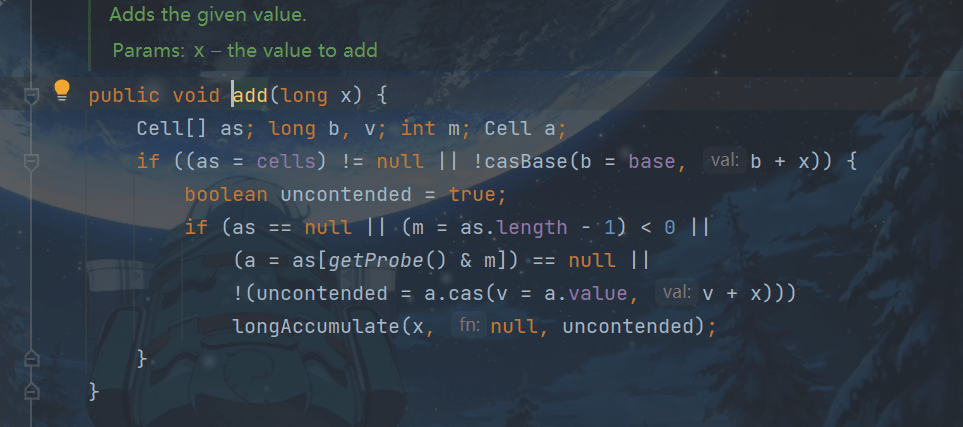
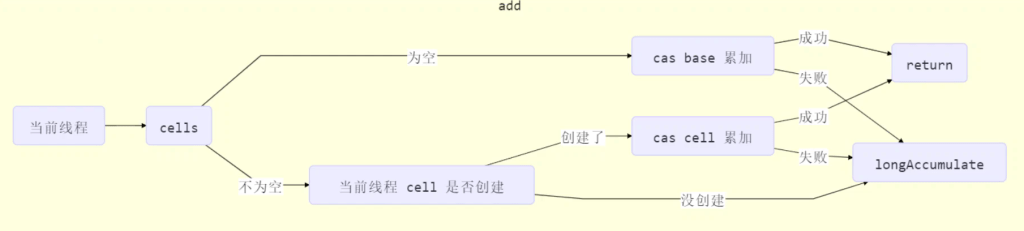
代码解释:
public void add(long x) {
// as 为累加单元数组
// b 为基础值
// x 为累加值
Cell[] as; long b, v; int m; Cell a;
// 进入 if 的两个条件(cells懒惰创建,竞争才创建)
// 1. as 有值, 表示已经发生过竞争, 进入 if
// 2. cas 给 base 累加时失败了, 表示 base 发生了竞争, 进入 if
if ((as = cells) != null || !casBase(b = base, b + x)) {
// uncontended 表示 cell 没有竞争
boolean uncontended = true;
if (
// as 还没有创建
as == null || (m = as.length - 1) < 0 ||
// 当前线程对应的 cell 还没有
(a = as[getProbe() & m]) == null ||
// cas 给当前线程的 cell 累加失败 uncontended=false ( a 为当前线程的 cell )
!(uncontended = a.cas(v = a.value, v + x))
) {
// 进入 cell 数组创建、cell 创建的流程
longAccumulate(x, null, uncontended);
}
}
}
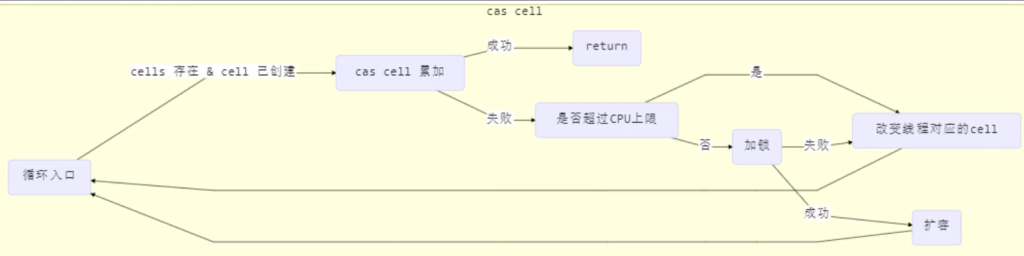
longAccumulate源码:
final void longAccumulate(long x, LongBinaryOperator fn,
boolean wasUncontended) {
int h;
// 当前线程还没有对应的 cell, 需要随机生成一个 h 值用来将当前线程绑定到 cell
if ((h = getProbe()) == 0) {
// 初始化 probe
ThreadLocalRandom.current();
// h 对应新的 probe 值, 用来对应 cell
h = getProbe();
wasUncontended = true;
}
// collide 为 true 表示需要扩容
boolean collide = false;
for (;;) {
Cell[] as; Cell a; int n; long v;
// 已经有了 cells
if ((as = cells) != null && (n = as.length) > 0) {
// 还没有 cell
if ((a = as[(n - 1) & h]) == null) {
// 为 cellsBusy 加锁, 创建 cell, cell 的初始累加值为 x
// 成功则 break, 否则继续 continue 循环
}
// 有竞争, 改变线程对应的 cell 来重试 cas
else if (!wasUncontended)
wasUncontended = true;
// cas 尝试累加, fn 配合 LongAccumulator 不为 null, 配合 LongAdder 为 null
else if (a.cas(v = a.value, ((fn == null) ? v + x : fn.applyAsLong(v, x))))
break;
// 如果 cells 长度已经超过了最大长度, 或者已经扩容, 改变线程对应的 cell 来重试 cas
else if (n >= NCPU || cells != as)
collide = false;
// 确保 collide 为 false 进入此分支, 就不会进入下面的 else if 进行扩容了
else if (!collide)
collide = true;
// 加锁
else if (cellsBusy == 0 && casCellsBusy()) {
// 加锁成功, 扩容
continue;
}
// 改变线程对应的 cell
h = advanceProbe(h);
}
// 还没有 cells, 尝试给 cellsBusy 加锁
else if (cellsBusy == 0 && cells == as && casCellsBusy()) {
// 加锁成功, 初始化 cells, 最开始长度为 2, 并填充一个 cell
// 成功则 break;
}
// 上两种情况失败, 尝试给 base 累加
else if (casBase(v = base, ((fn == null) ? v + x : fn.applyAsLong(v, x))))
break;
}
}

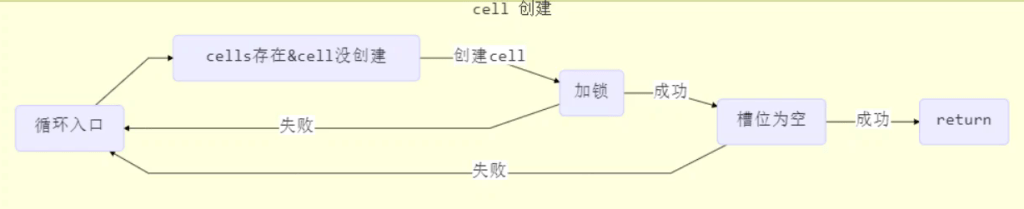
long sum()返回 当前的值,内部操作是所有 Cell 内部的 value 值后再累加base
public long sum() {
Cell[] as = cells; Cell a;
long sum = base;
if (as != null) {
for (int i = 0; i < as.length; ++i) {
if ((a = as[i]) != null)
sum += a.value;
}
}
return sum;
}
Unsafe CAS 操作
@Data
class Student {
volatile int id;
volatile String name;
}Unsafe unsafe = UnsafeAccessor.getUnsafe();
Field id = Student.class.getDeclaredField("id");
Field name = Student.class.getDeclaredField("name");
// 获得成员变量的偏移量
long idOffset = UnsafeAccessor.unsafe.objectFieldOffset(id);
long nameOffset = UnsafeAccessor.unsafe.objectFieldOffset(name);
Student student = new Student();
// 使用 cas 方法替换成员变量的值
UnsafeAccessor.unsafe.compareAndSwapInt(student, idOffset, 0, 20); // 返回 true
UnsafeAccessor.unsafe.compareAndSwapObject(student, nameOffset, null, "张三"); // 返回 true
System.out.println(student);
使用自定义的 AtomicData 实现之前线程安全的原子整数 Account 实现
class AtomicData {
private volatile int data;
static final Unsafe unsafe;
static final long DATA_OFFSET;
static {
unsafe = UnsafeAccessor.getUnsafe();
try {
// data 属性在 DataContainer 对象中的偏移量,用于 Unsafe 直接访问该属性
DATA_OFFSET = unsafe.objectFieldOffset(AtomicData.class.getDeclaredField("data"));
} catch (NoSuchFieldException e) {
throw new Error(e);
}
}
public AtomicData(int data) {
this.data = data;
}
public void decrease(int amount) {
int oldValue;
while(true) {
// 获取共享变量旧值,可以在这一行加入断点,修改 data 调试来加深理解
oldValue = data;
// cas 尝试修改 data 为 旧值 + amount,如果期间旧值被别的线程改了,返回 false
if (unsafe.compareAndSwapInt(this, DATA_OFFSET, oldValue, oldValue - amount)) {
return;
}
}
}
public int getData() {
return data;
}
}
2.不可变
无论是synchronized关键字还是显式锁Lock,都会牺牲系统的性能,不可变对象的设计理念基于此。
日期转换的问题
问题提出
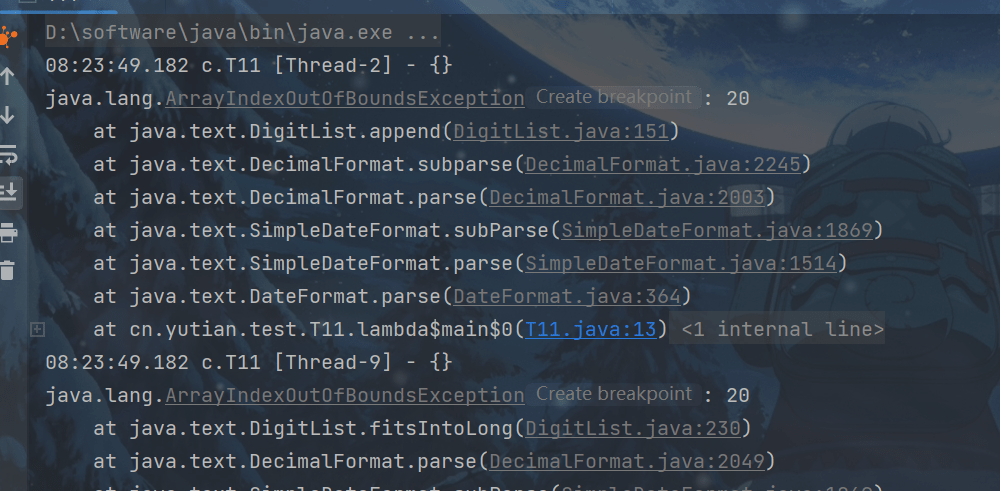
下面的代码在运行时,由于 SimpleDateFormat 不是线程安全的,会报异常:
package cn.yutian.test;
import lombok.extern.slf4j.Slf4j;
import java.text.SimpleDateFormat;
@Slf4j(topic = "c.T11")
public class T11 {
public static void main(String[] args) {
SimpleDateFormat sdf = new SimpleDateFormat("yyyy-MM-dd");
for (int i = 0; i < 10; i++) {
new Thread(() -> {
try {
log.debug("{}", sdf.parse("1951-04-21"));
} catch (Exception e) {
log.error("{}", e);
}
}).start();
}
}
}
思路 – 同步锁
这样虽能解决问题,但带来的是性能上的损失,并不算很好:
SimpleDateFormat sdf = new SimpleDateFormat("yyyy-MM-dd");
for (int i = 0; i < 50; i++) {
new Thread(() -> {
synchronized (sdf) {
try {
log.debug("{}", sdf.parse("1951-04-21"));
} catch (Exception e) {
log.error("{}", e);
}
}
}).start();
}
思路 – 不可变
如果一个对象在不能够修改其内部状态(属性),那么它就是线程安全的,因为不存在并发修改。
例如在 Java 8 后,提供了一个新的日期格式化类:
DateTimeFormatter dtf = DateTimeFormatter.ofPattern("yyyy-MM-dd");
for (int i = 0; i < 10; i++) {
new Thread(() -> {
//TemporalAccessor parse = dtf.parse("2018-10-01");
LocalDate date = dtf.parse("2018-10-01", LocalDate::from);
log.debug("{}", date);
}).start();
}
另一个大家更为熟悉的 String 类也是不可变的,以它为例,说明一下不可变设计的要素
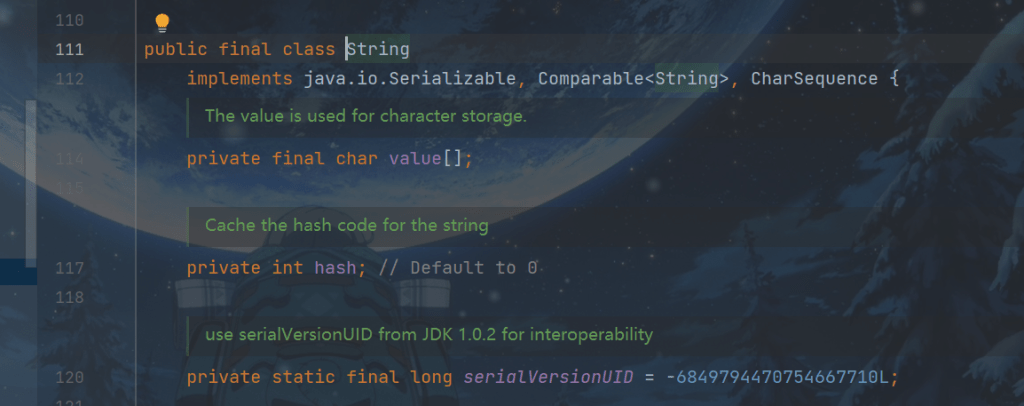
final 的使用
发现该类、类中所有属性都是 final 的:
- 属性用 final 修饰保证了该属性是只读的,不能修改
- 类用 final 修饰保证了该类中的方法不能被覆盖,防止子类无意间破坏不可变性
使用final不能保证数组里的元素被更改
private final char value[];
所以使用保护性拷贝
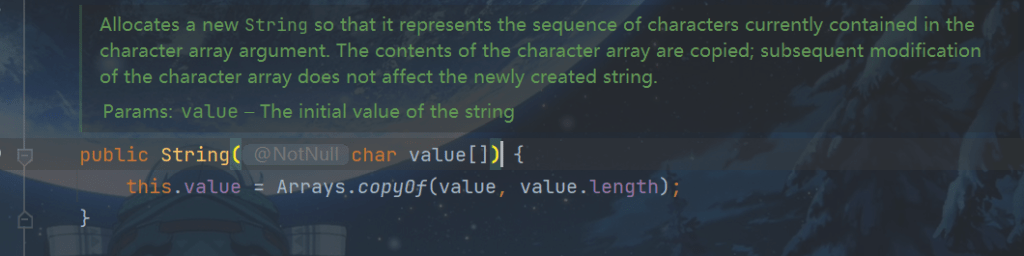
保护性拷贝
使用字符串时,也有一些跟修改相关的方法啊,比如 String 的 replace,substring 等方法改变值。
举例:
String的substring方法
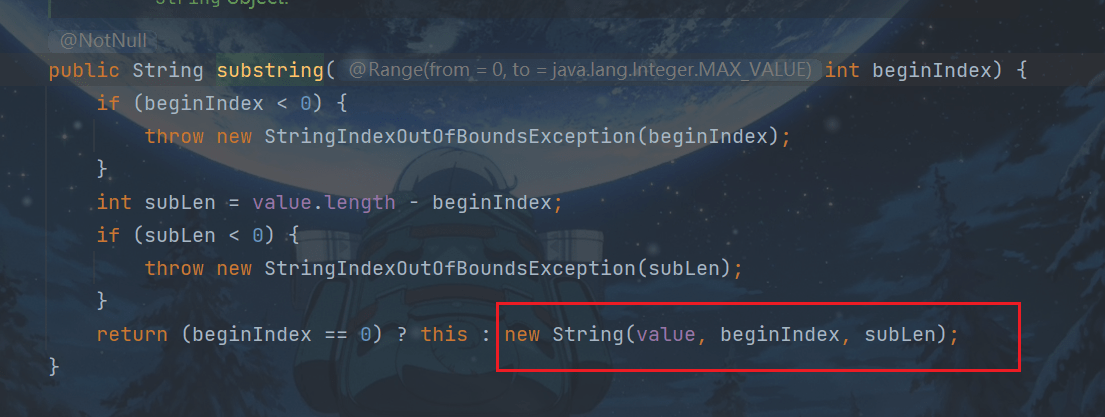
新建一个字符串,对原有值复制,
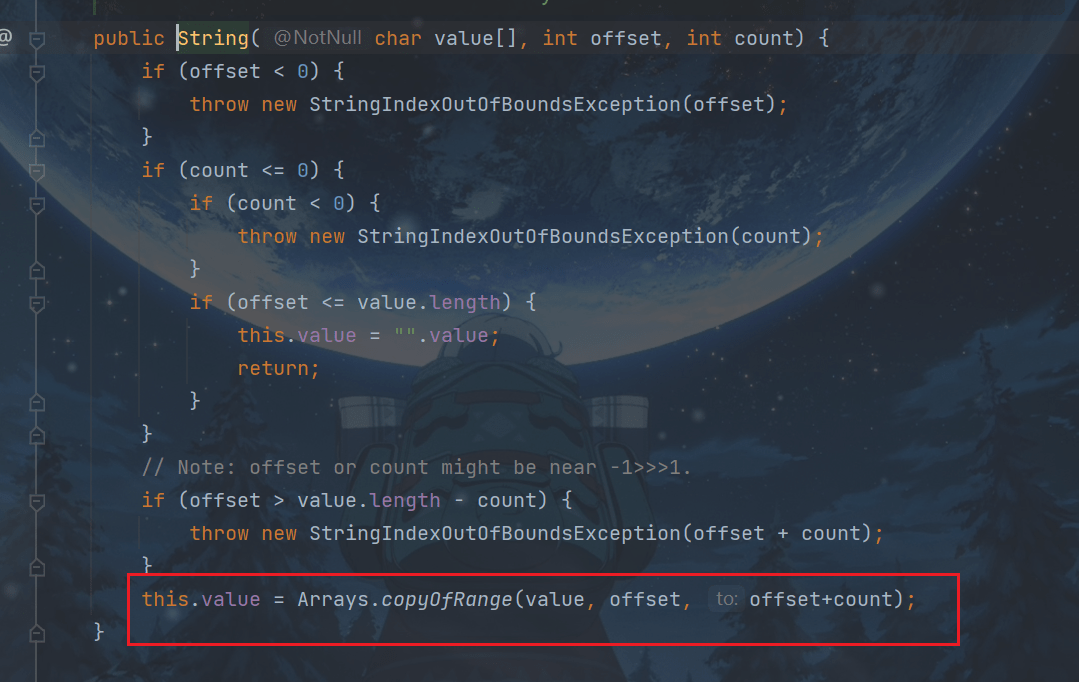
也就是说其内部的值根本没改变
这种通过创建副本对象来避免共享的手段称之为保护性拷贝(defensive copy)
final 原理
1. 设置 final 变量的原理
理解了 volatile 原理,再对比 final 的实现就比较简单了
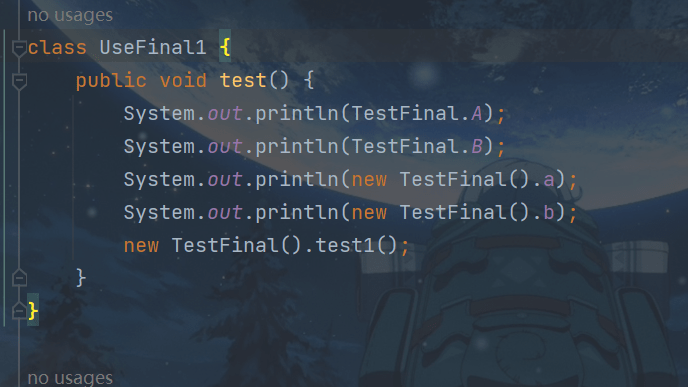
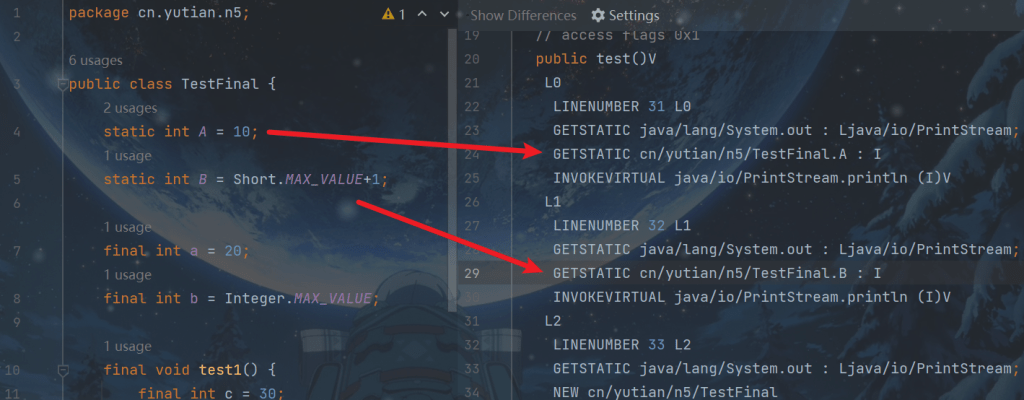
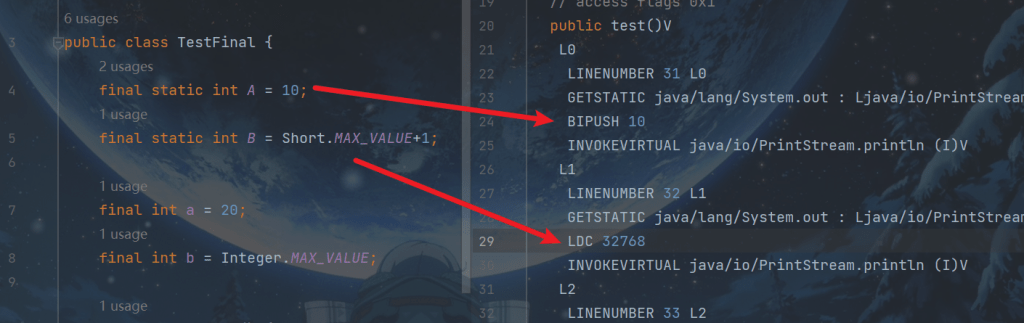
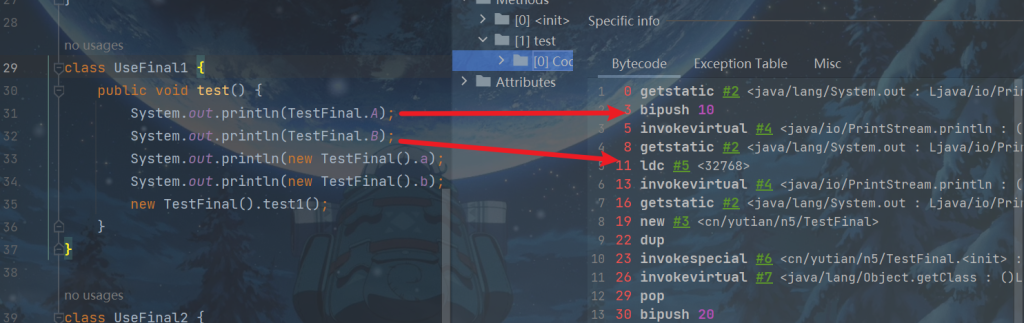
public class TestFinal {
final int a = 20;
}字节码
0: aload_0 1: invokespecial #1 // Method java/lang/Object."":()V 4: aload_0 5: bipush 20 7: putfield #2 // Field a:I <-- 写屏障 10: return
发现 final 变量的赋值也会通过 putfield 指令来完成,同样在这条指令之后也会加入写屏障,保证在其它线程读到它的值时不会出现为 0 的情况
2. 获取 final 变量的原理
会得到优化,在其他方法访问final
无状态
在 web 阶段学习时,设计 Servlet 时为了保证其线程安全,都会有这样的建议,不要为 Servlet 设置成员变量,这种没有任何成员变量的类是线程安全的
因为成员变量保存的数据也可以称为状态信息,因此没有成员变量就称之为无状态
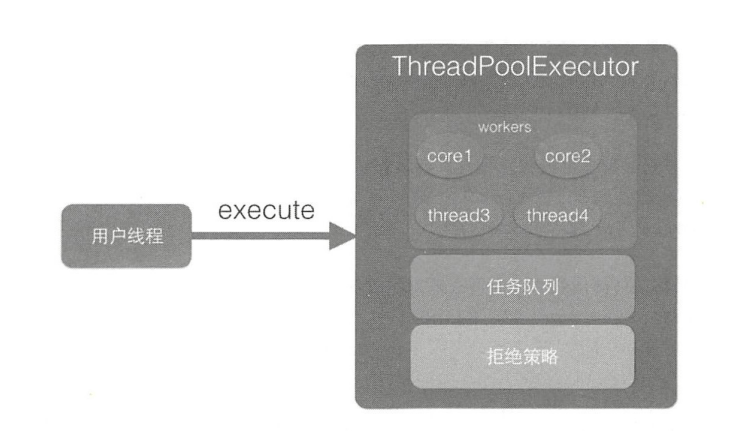
3.线程池
一个完整的线程池应该具备如下要素。
- 任务队列:用于缓存提交的任务。
- 线程数量管理功能:一个线程池必须能够很好地管理和控制线程数量,可通过如下三个参数来实现,比如创建线程池时初始的线程数量 init;线程池自动扩充时最大的线程数量max;在线程池空闲时需要释放线程但是也要维护一定数量的活跃数量或者核心数量core。有了这三个参数,就能够很好地控制线程池中的线程数量,将其维护在一个合理的范围之内,三者之间的关系是init<=core<=max。
- 任务拒绝策略:如果线程数量已达到上限且任务队列已满,则需要有相应的拒绝策略来通知任务提交者。
- 线程工厂:主要用于个性化定制线程,比如将线程设置为守护线程以及设置线程名称等。
- QueueSize:任务队列主要存放提交的 Runnable,但是为了防止内存溢出,需要有limit 数量对其进行控制。
- Keepedalive时间:该时间主要决定线程各个重要参数自动维护的时间间隔。
1. 自定义线程池
package cn.yutian.n8;
import lombok.extern.slf4j.Slf4j;
import org.springframework.core.log.LogDelegateFactory;
import java.util.ArrayDeque;
import java.util.Deque;
import java.util.HashSet;
import java.util.concurrent.TimeUnit;
import java.util.concurrent.locks.Condition;
import java.util.concurrent.locks.ReentrantLock;
@Slf4j(topic = "c.TestPool")
public class TestPool {
public static void main(String[] args) {
ThreadPool threadPool = new ThreadPool(1,
1000, TimeUnit.MILLISECONDS, 1, (queue, task)->{
// 1. 死等
// queue.put(task);
// 2) 带超时等待
// queue.offer(task, 1500, TimeUnit.MILLISECONDS);
// 3) 让调用者放弃任务执行
// log.debug("放弃{}", task);
// 4) 让调用者抛出异常
// throw new RuntimeException("任务执行失败 " + task);
// 5) 让调用者自己执行任务
task.run();
});
for (int i = 0; i < 4; i++) {
int j = i;
threadPool.execute(() -> {
try {
Thread.sleep(1000L);
} catch (InterruptedException e) {
e.printStackTrace();
}
log.debug("{}", j);
});
}
}
}
@FunctionalInterface // 拒绝策略
interface RejectPolicy<T> {
void reject(BlockingQueue<T> queue, T task);
}
@Slf4j(topic = "c.ThreadPool")
class ThreadPool {
// 任务队列
private BlockingQueue<Runnable> taskQueue;
// 线程集合
private HashSet<Worker> workers = new HashSet<>();
// 核心线程数
private int coreSize;
// 获取任务时的超时时间
private long timeout;
private TimeUnit timeUnit;
private RejectPolicy<Runnable> rejectPolicy;
// 执行任务
public void execute(Runnable task) {
// 当任务数没有超过 coreSize 时,直接交给 worker 对象执行
// 如果任务数超过 coreSize 时,加入任务队列暂存
synchronized (workers) {
if(workers.size() < coreSize) {
Worker worker = new Worker(task);
log.debug("新增 worker{}, {}", worker, task);
workers.add(worker);
worker.start();
} else {
// taskQueue.put(task);
// 1) 死等
// 2) 带超时等待
// 3) 让调用者放弃任务执行
// 4) 让调用者抛出异常
// 5) 让调用者自己执行任务
taskQueue.tryPut(rejectPolicy, task);
}
}
}
public ThreadPool(int coreSize, long timeout, TimeUnit timeUnit, int queueCapcity, RejectPolicy<Runnable> rejectPolicy) {
this.coreSize = coreSize;
this.timeout = timeout;
this.timeUnit = timeUnit;
this.taskQueue = new BlockingQueue<>(queueCapcity);
this.rejectPolicy = rejectPolicy;
}
class Worker extends Thread{
private Runnable task;
public Worker(Runnable task) {
this.task = task;
}
@Override
public void run() {
// 执行任务
// 1) 当 task 不为空,执行任务
// 2) 当 task 执行完毕,再接着从任务队列获取任务并执行
// while(task != null || (task = taskQueue.take()) != null) {
while(task != null || (task = taskQueue.poll(timeout, timeUnit)) != null) {
try {
log.debug("正在执行...{}", task);
task.run();
} catch (Exception e) {
e.printStackTrace();
} finally {
task = null;
}
}
synchronized (workers) {
log.debug("worker 被移除{}", this);
workers.remove(this);
}
}
}
}
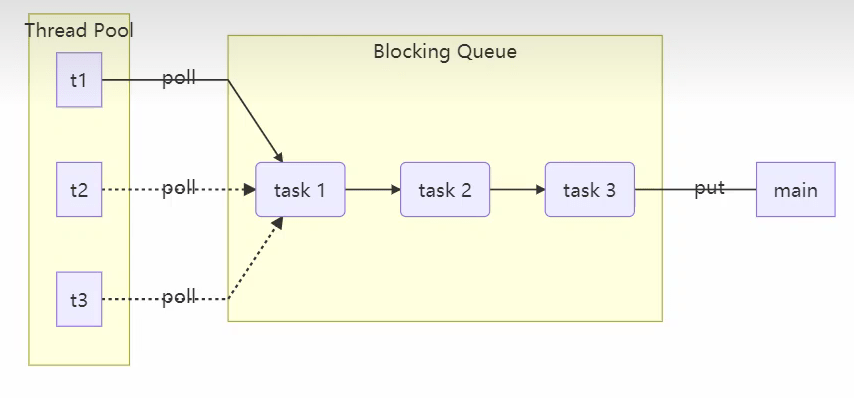
@Slf4j(topic = "c.BlockingQueue")
class BlockingQueue<T> {
// 1. 任务队列
private Deque<T> queue = new ArrayDeque<>();
// 2. 锁
private ReentrantLock lock = new ReentrantLock();
// 3. 生产者条件变量
private Condition fullWaitSet = lock.newCondition();
// 4. 消费者条件变量
private Condition emptyWaitSet = lock.newCondition();
// 5. 容量
private int capcity;
public BlockingQueue(int capcity) {
this.capcity = capcity;
}
// 带超时阻塞获取
public T poll(long timeout, TimeUnit unit) {
lock.lock();
try {
// 将 timeout 统一转换为 纳秒
long nanos = unit.toNanos(timeout);
while (queue.isEmpty()) {
try {
// 返回值是剩余时间
if (nanos <= 0) {
return null;
}
nanos = emptyWaitSet.awaitNanos(nanos);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
T t = queue.removeFirst();
fullWaitSet.signal();
return t;
} finally {
lock.unlock();
}
}
// 阻塞获取
public T take() {
lock.lock();
try {
while (queue.isEmpty()) {
try {
emptyWaitSet.await();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
T t = queue.removeFirst();
fullWaitSet.signal();
return t;
} finally {
lock.unlock();
}
}
// 阻塞添加
public void put(T task) {
lock.lock();
try {
while (queue.size() == capcity) {
try {
log.debug("等待加入任务队列 {} ...", task);
fullWaitSet.await();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
log.debug("加入任务队列 {}", task);
queue.addLast(task);
emptyWaitSet.signal();
} finally {
lock.unlock();
}
}
// 带超时时间阻塞添加
public boolean offer(T task, long timeout, TimeUnit timeUnit) {
lock.lock();
try {
long nanos = timeUnit.toNanos(timeout);
while (queue.size() == capcity) {
try {
if(nanos <= 0) {
return false;
}
log.debug("等待加入任务队列 {} ...", task);
nanos = fullWaitSet.awaitNanos(nanos);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
log.debug("加入任务队列 {}", task);
queue.addLast(task);
emptyWaitSet.signal();
return true;
} finally {
lock.unlock();
}
}
public int size() {
lock.lock();
try {
return queue.size();
} finally {
lock.unlock();
}
}
public void tryPut(RejectPolicy<T> rejectPolicy, T task) {
lock.lock();
try {
// 判断队列是否满
if(queue.size() == capcity) {
rejectPolicy.reject(this, task);
} else { // 有空闲
log.debug("加入任务队列 {}", task);
queue.addLast(task);
emptyWaitSet.signal();
}
} finally {
lock.unlock();
}
}
}
2. ThreadPoolExecutor
1.线程池状态
ThreadPoolExecutor 使用 int 的高 3 位来表示线程池状态,低 29 位表示线程数量

从数字上比较,TERMINATED > TIDYING > STOP > SHUTDOWN > RUNNING(111的第一位是符合位)
线程池状态转换列举如下。
- RUNNING -> SHUTDOWN :显式调用 shutdown() 方法,或者隐式调用了 finalize()方法里面的 shutdown()方法。
- RUNNING或SHUTDOWN)-> STOP :显式调用shutdownNow()方法时。
- SHUTDOWN-> TIDYING:当线程池和任务队列都为空时。
- STOP->TIDYING:当线程池为空时。
- TIDYING->TERMINATED :当terminated() hook方法执行完成时。
这些信息存储在一个原子变量 ctl 中,目的是将线程池状态与线程个数合二为一,这样就可以用一次 cas 原子操作进行赋值
// c 为旧值, ctlOf 返回结果为新值
ctl.compareAndSet(c, ctlOf(targetState, workerCountOf(c))));
// rs 为高 3 位代表线程池状态, wc 为低 29 位代表线程个数,ctl 是合并它们
private static int ctlOf(int rs, int wc) { return rs | wc; }
2.构造方法
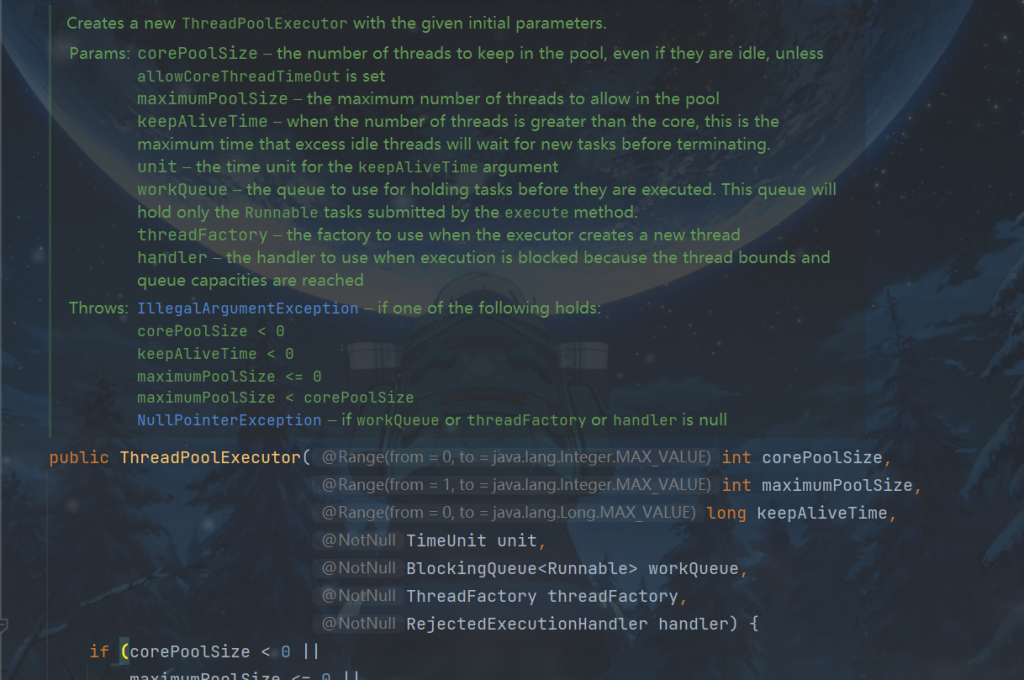
线程池参数如下。
- corePoolSize :线程池核心线程个数。
- workQueue:用于保存等待执行的任务的阻塞队列,比如基于数组的有界ArrayBlockingQueue、基于链表的无界LinkedBlockingQueue、最多只有一个元素的同步队列SynchronousQueue及优先级队列PriorityBlockingQueue等。
- maximunPoolSize:线程池最大线程数量。(核心线程加救急线程)
- ThreadFactory :创建线程的工厂。
- RejectedExecutionHandler:饱和策略,当队列满并且线程个数达到maximunPoolSize后采取的策略,比如AbortPolicy (抛出异常)、CallerRunsPolicy (使用调用者所在线程来运行任务)、DiscardOldestPolicy (调用poll丢弃一个任务,执行当前任务)及 DiscardPolicy (默默丢弃,不抛出异常)
- keeyAliveTime:存活时间。如果当前线程池中的线程数量比核心线程数量多,并且是闲置状态,则这些闲置的线程(救急线程)能存活的最大时间。 生存时间 – 针对救急线程
- TimeUnit:存活时间的时间单位。 时间单位 – 针对救急线程
救急线程 = maximunPoolSize – corePoolSize
步骤如下:
1.
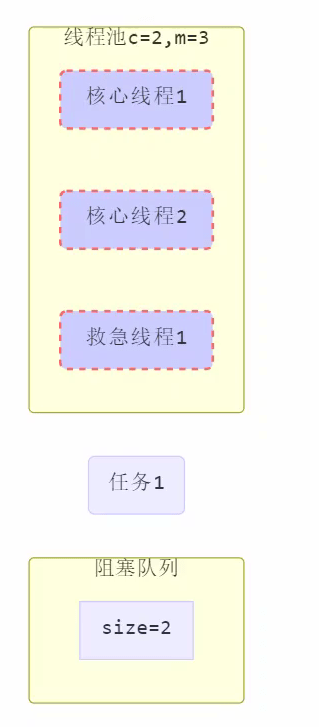
2.
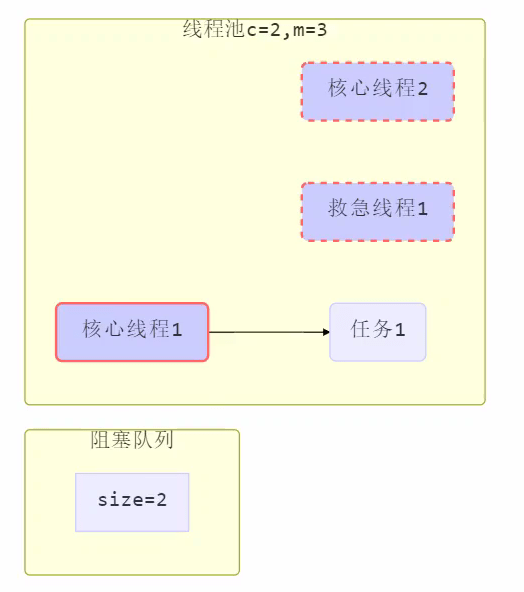
3.
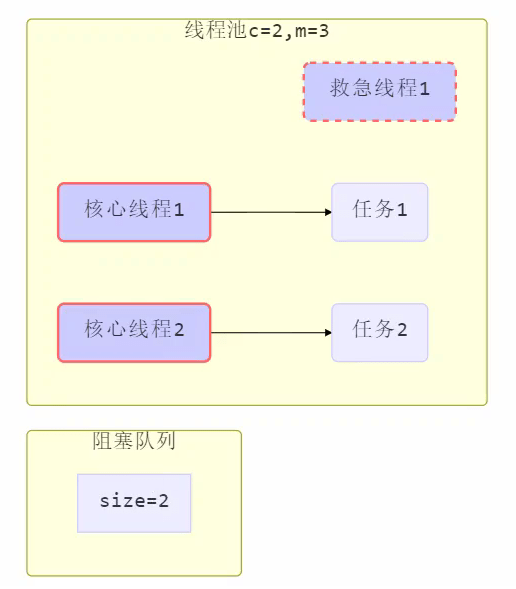
4.
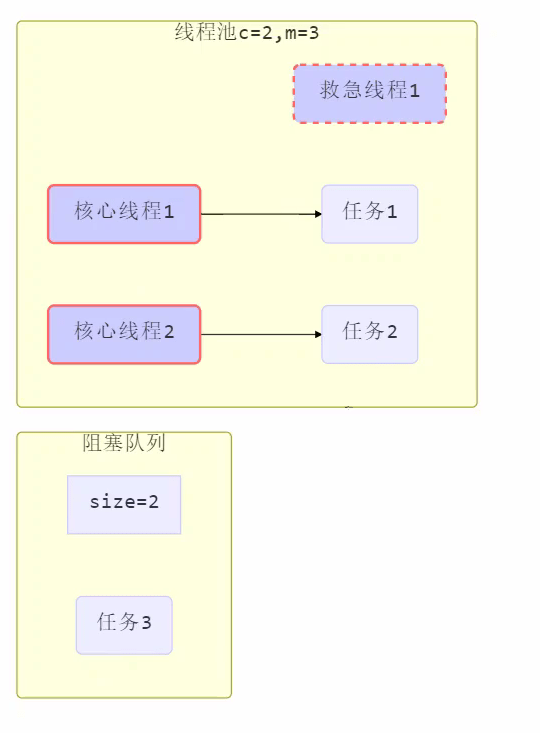
5.
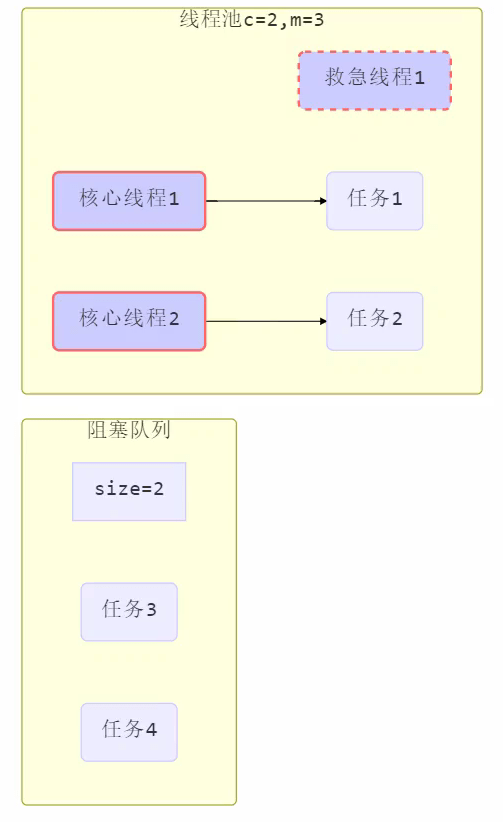
6.此时救急线程作用就来了
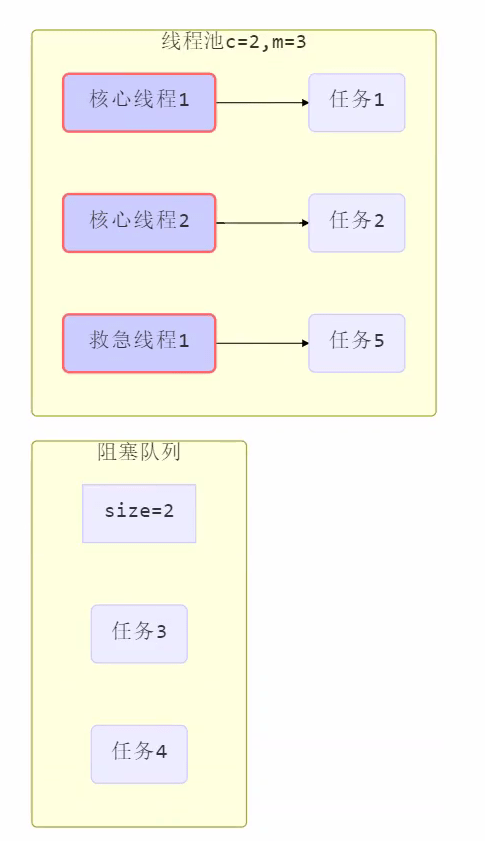
注意:
- 救急线程有存活时间,处理玩救急线程的任务后,存活时间过后,就销毁,等到下次需要再创建。
- 而核心线程没有存活时间,一直存活。
7.都满了,才会执行拒绝策略。
- 线程池中刚开始没有线程,当一个任务提交给线程池后,线程池会创建一个新线程来执行任务。
- 当线程数达到 corePoolSize 并没有线程空闲,这时再加入任务,新加的任务会被加入workQueue 队列排队,直到有空闲的线程。
- 如果队列选择了有界队列,那么任务超过了队列大小时,会创建 maximumPoolSize – corePoolSize 数目的线程来救急。
- 如果线程到达 maximumPoolSize 仍然有新任务这时会执行拒绝策略。拒绝策略 jdk 提供了 4 种实现,其它著名框架也提供了实现。如:AbortPolicy 让调用者抛出 RejectedExecutionException 异常,这是默认策略。CallerRunsPolicy 让调用者运行任务
DiscardPolicy 放弃本次任务。DiscardOldestPolicy 放弃队列中最早的任务,本任务取而代之。Dubbo 的实现,在抛出 RejectedExecutionException 异常之前会记录日志,并 dump 线程栈信息,方便定位问题。Netty 的实现,是创建一个新线程来执行任务。ActiveMQ 的实现,带超时等待(60s)尝试放入队列,类似我们之前自定义的拒绝策略。PinPoint 的实现,它使用了一个拒绝策略链,会逐一尝试策略链中每种拒绝策略 。 - 当高峰过去后,超过corePoolSize 的救急线程如果一段时间没有任务做,需要结束节省资源,这个时间由keepAliveTime 和 unit 来控制。

根据这个构造方法,JDK Executors 类中提供了众多工厂方法来创建各种用途的线程池
1. newFixedThreadPool
创建一个核心线程个数和最大线程个数都为 nThreads 的线程池,LinkedBlockingQueue<Runnable>())表示阻塞队列长度为Integer.MAX_VALUE。 keeyAliveTime=0说明只要线程个数比核心线程个数多并且当前空闲则回收。当然核心线程个数和最大线程个数都为 nThreads 表示没有救急线程。
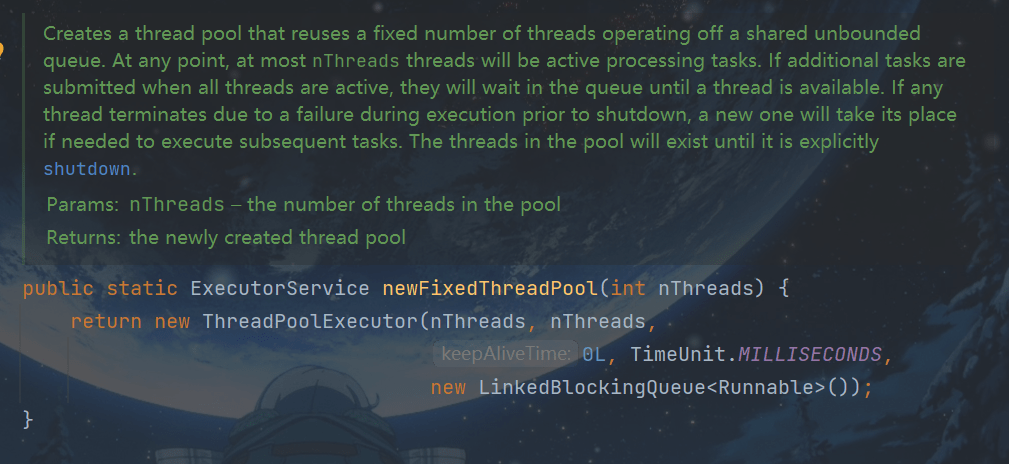
特点
- 核心线程数 == 最大线程数(没有救急线程被创建),因此也无需超时时间
- 阻塞队列是无界的,即阻塞队列长度为Integer.MAX_VALUE。表示可以放任意数量的任务
- 适用于任务量已知,相对耗时的任务
package cn.yutian.n8;
import lombok.extern.slf4j.Slf4j;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
@Slf4j(topic = "c.TestExecutors")
public class TestExecutors {
public static void main(String[] args) throws InterruptedException {
ExecutorService pool = Executors. newFixedThreadPool(2);
pool.execute(() -> {
log.debug("1");
});
pool.execute(() -> {
log.debug("2");
});
pool.execute(() -> {
log.debug("3");
});
}
}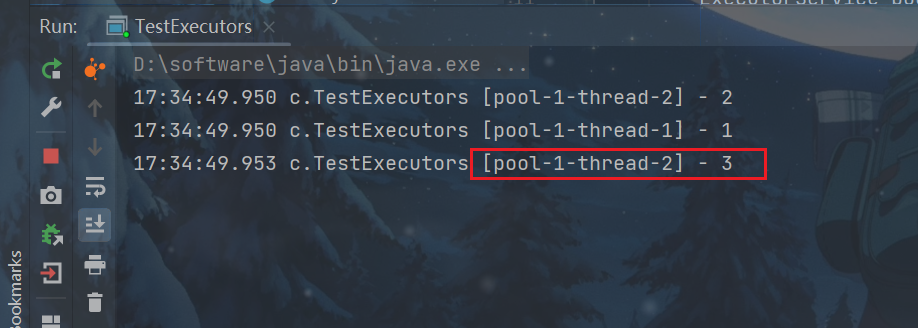
可以看到,线程2执行完了才去解决3
注意:因为都是核心线程,所以不会主动结束线程。
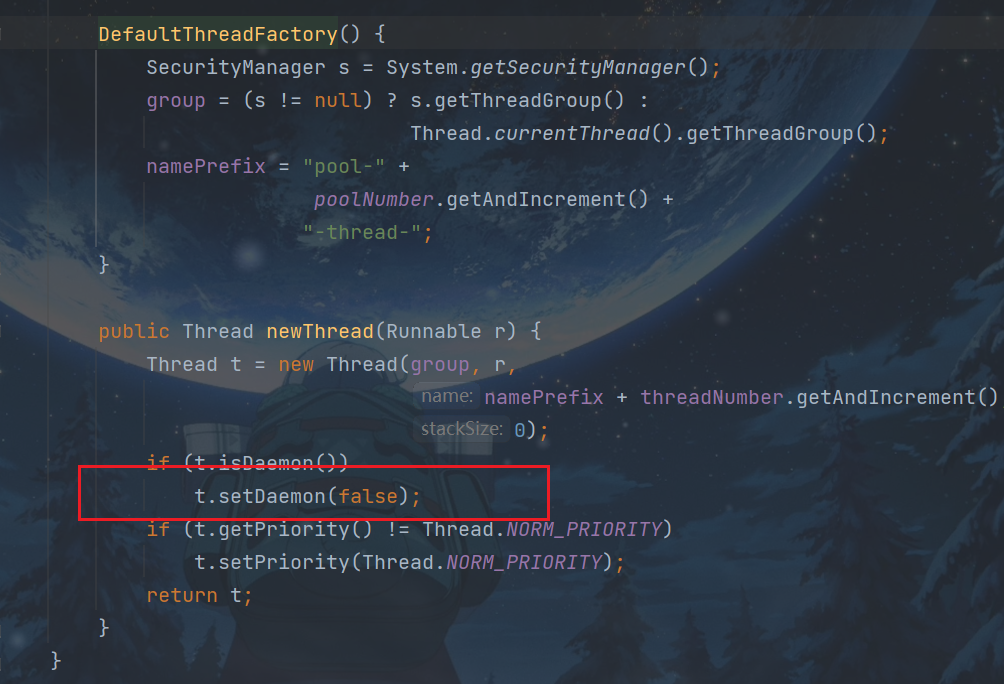
顺便看看为什么命名为pool-1-thread-2这种形式:
ctrl+B进入
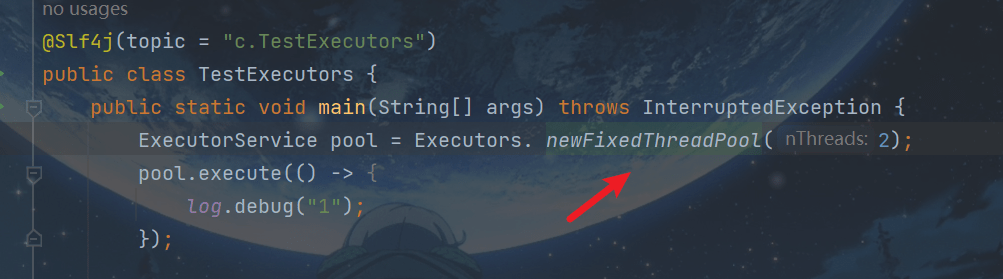
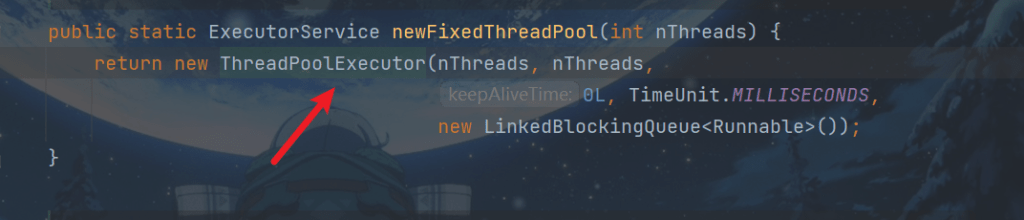
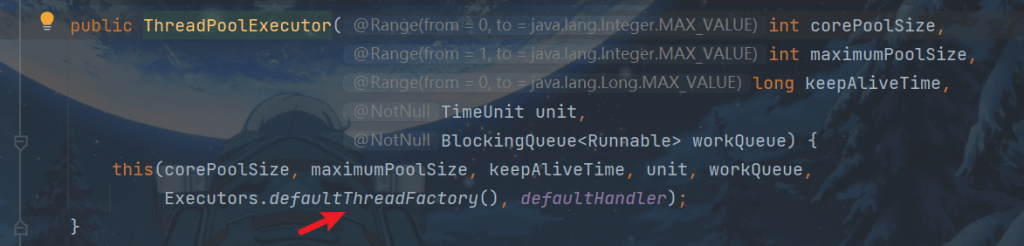
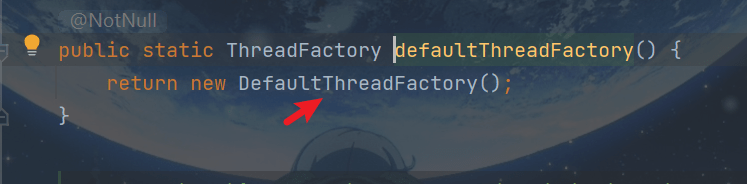
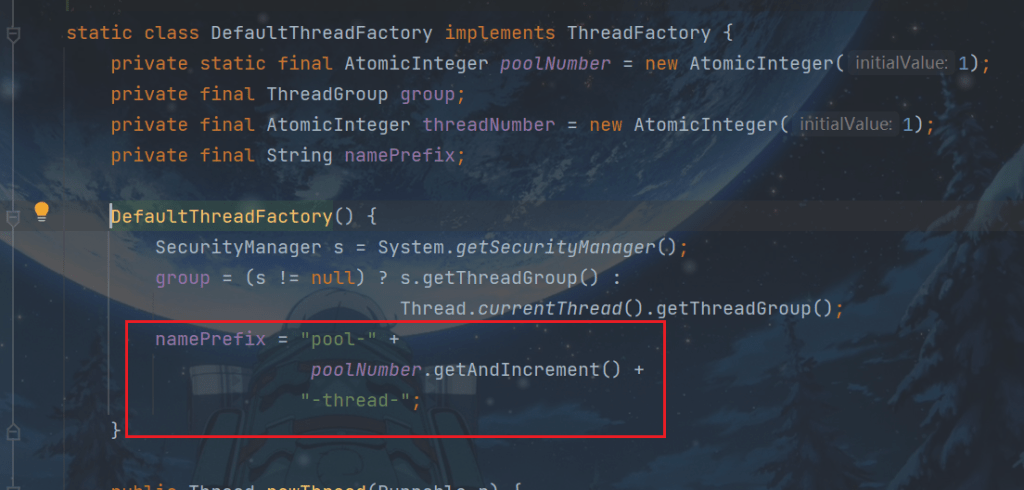
同时注意,线程池的都是非守护线程,不会随着主线程结束而结束。
自定义改变名字:
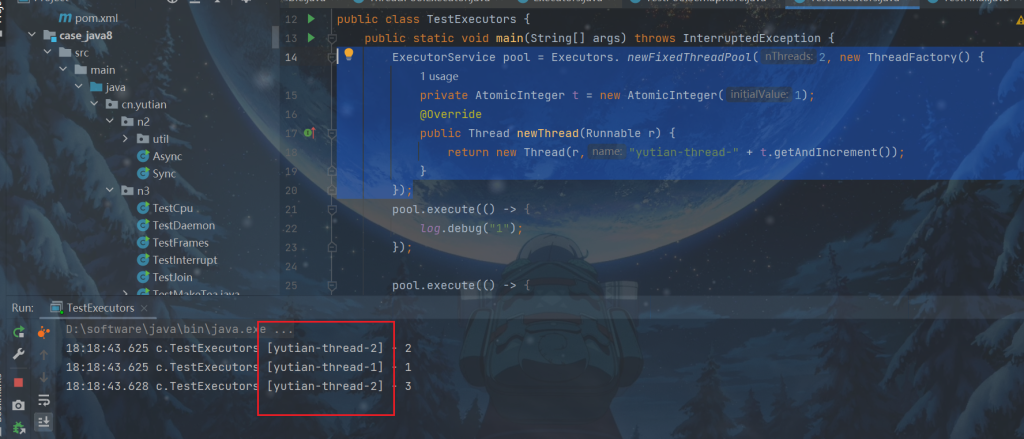
ExecutorService pool = Executors. newFixedThreadPool(2, new ThreadFactory() {
//序号
private AtomicInteger t = new AtomicInteger(1);
@Override
public Thread newThread(Runnable r) {
return new Thread(r,"yutian-thread-" + t.getAndIncrement());
}
});
2.newCachedThreadPool
newCachedThreadPool :创建一个按需创建线程的线程池,初始线程个数为0,最多线程个数为Integer.MAX_VALUE,并且阻塞队列为同步队列。keeyAliveTime=60说明只要当前线程在60s内空闲则回收。这个类型的特殊之处在于,加入同步队列的任务会被马上执行,同步队列里面最多只有一个任务。
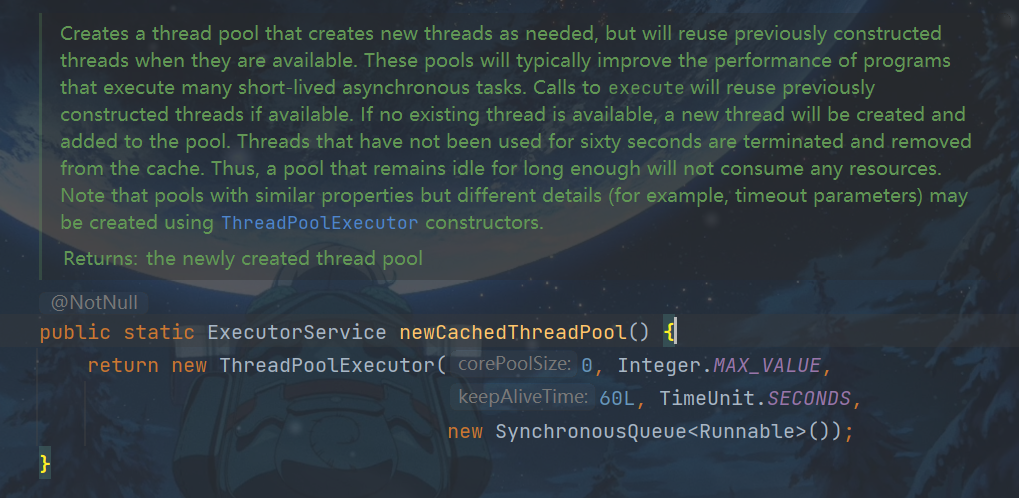
特点:
- 核心线程数是 0, 最大线程数是 Integer.MAX_VALUE,救急线程的空闲生存时间是 60s,意味着全部都是救急线程(60s 后可以回收)
- 队列采用了 SynchronousQueue 实现特点是,它没有容量,没有线程来取是放不进去的(一手交钱、一手交货)。
整个线程池表现为线程数会根据任务量不断增长,没有上限,当任务执行完毕,空闲 1分钟后释放线程。 适合任务数比较密集,但每个任务执行时间较短的情况
package cn.yutian.n8;
import lombok.extern.slf4j.Slf4j;
import java.util.concurrent.SynchronousQueue;
import static cn.yutian.n2.util.Sleeper.sleep;
@Slf4j(topic = "c.TestSynchronousQueue")
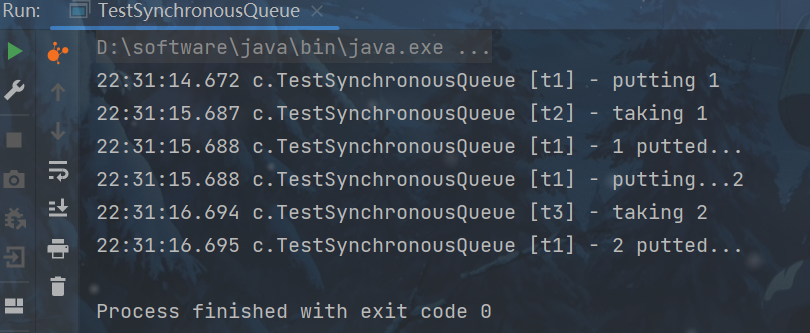
public class TestSynchronousQueue {
public static void main(String[] args) {
SynchronousQueue<Integer> integers = new SynchronousQueue<>();
new Thread(() -> {
try {
log.debug("putting {} ", 1);
integers.put(1);
log.debug("{} putted...", 1);
log.debug("putting...{} ", 2);
integers.put(2);
log.debug("{} putted...", 2);
} catch (InterruptedException e) {
e.printStackTrace();
}
},"t1").start();
sleep(1);
new Thread(() -> {
try {
log.debug("taking {}", 1);
integers.take();
} catch (InterruptedException e) {
e.printStackTrace();
}
},"t2").start();
sleep(1);
new Thread(() -> {
try {
log.debug("taking {}", 2);
integers.take();
} catch (InterruptedException e) {
e.printStackTrace();
}
},"t3").start();
}
}
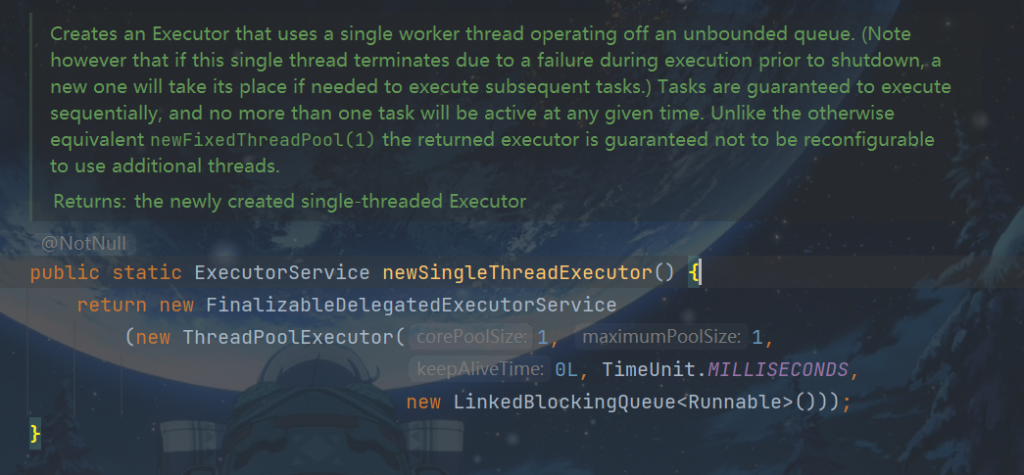
3.newSingleThreadExecutor
newSingleThreadExecutor:创建一个核心线程个数和最大线程个数都为1的线程池,并且阻塞队列长度为Integer.MAX_VALUE, keeyAliveTime=0说明只要线程个数比核心线程个数多并且当前空闲则回收。
使用场景:
希望多个任务排队执行。线程数固定为 1,任务数多于 1 时,会放入无界队列排队。任务执行完毕,这唯一的线程也不会被释放。
区别:
- 自己创建一个单线程串行执行任务,如果任务执行失败而终止那么没有任何补救措施,而线程池还会新建一个线程,保证池的正常工作
- Executors.newSingleThreadExecutor() 线程个数始终为1,不能修改。返回一个FinalizableDelegatedExecutorService,其应用的是装饰器模式,只对外暴露了 ExecutorService 接口,因此不能调用 ThreadPoolExecutor 中特有的方法。
- Executors.newFixedThreadPool(1) 初始时为1,以后还可以修改对外暴露的是 ThreadPoolExecutor 对象,可以强转后调用 setCorePoolSize 等方法进行修改
示例代码:
package cn.yutian.n8;
import lombok.extern.slf4j.Slf4j;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
@Slf4j(topic = "c.TestExecutors")
public class TestExecutors {
public static void main(String[] args) throws InterruptedException {
test2();
}
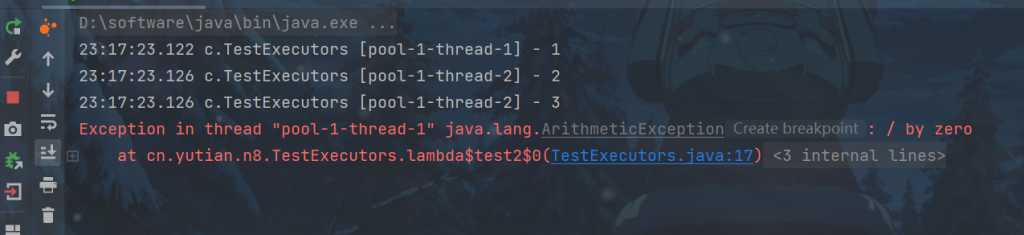
public static void test2() {
ExecutorService pool = Executors.newSingleThreadExecutor();
pool.execute(() -> {
log.debug("1");
int i = 1 / 0;
});
pool.execute(() -> {
log.debug("2");
});
pool.execute(() -> {
log.debug("3");
});
}
}
3.其他方法
其实这里,我本来想解释一下下面方法的源代码的,但是,刚好没时间,有缘人,如果你看到这,又刚好认识我,可以去催催我
execute方法的作用是提交任务command到线程池进行执行。
// 执行任务 void execute(Runnable command);
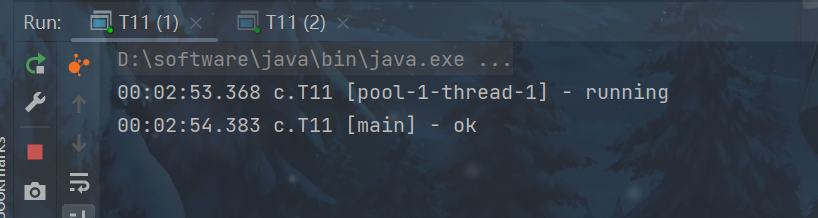
submit方法,使用保护暂停模式接受
// 提交任务 task,用返回值 Future 获得任务执行结果 Future submit(Callable task);
代码演示:
package cn.yutian.test;
import lombok.extern.slf4j.Slf4j;
import java.util.concurrent.*;
@Slf4j(topic = "c.T11")
public class T11 {
public static void main(String[] args) throws ExecutionException, InterruptedException {
ExecutorService pool = Executors.newFixedThreadPool(2);
Future<String> future = pool.submit(new Callable<String>() {
@Override
public String call() throws Exception {
log.debug("running");
Thread.sleep(1000);
return "ok";
}
});
log.debug("{}",future.get());
}
}
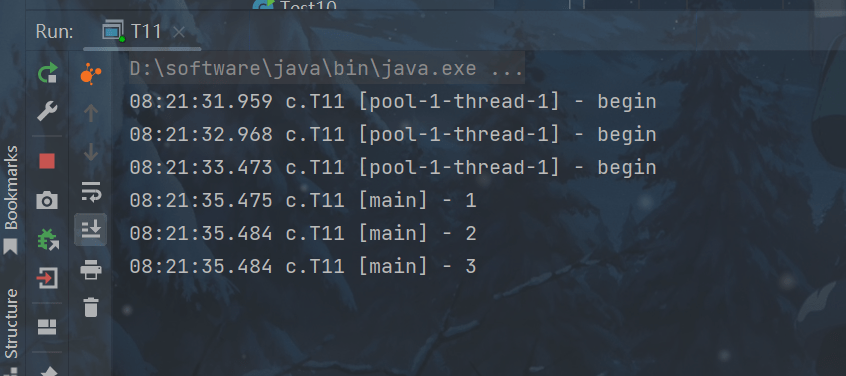
invokeAll
// 提交 tasks 中所有任务 List<Future> invokeAll(Collection<? extends Callable> tasks) throws InterruptedException;
// 提交 tasks 中所有任务,带超时时间 List<Future> invokeAll(Collection<? extends Callable> tasks, long timeout, TimeUnit unit) throws InterruptedException;
代码演示:
package cn.yutian.test;
import lombok.extern.slf4j.Slf4j;
import java.util.Arrays;
import java.util.List;
import java.util.concurrent.*;
@Slf4j(topic = "c.T11")
public class T11 {
public static void main(String[] args) throws ExecutionException, InterruptedException {
ExecutorService pool = Executors.newFixedThreadPool(1);
List<Future<String>> futures = pool.invokeAll(Arrays.asList(
() -> {
log.debug("begin");
Thread.sleep(1000);
return "1";
},
() -> {
log.debug("begin");
Thread.sleep(500);
return "2";
},
() -> {
log.debug("begin");
Thread.sleep(2000);
return "3";
}
));
futures.forEach( f -> {
try {
log.debug("{}", f.get());
} catch (InterruptedException | ExecutionException e) {
e.printStackTrace();
}
});
}
}
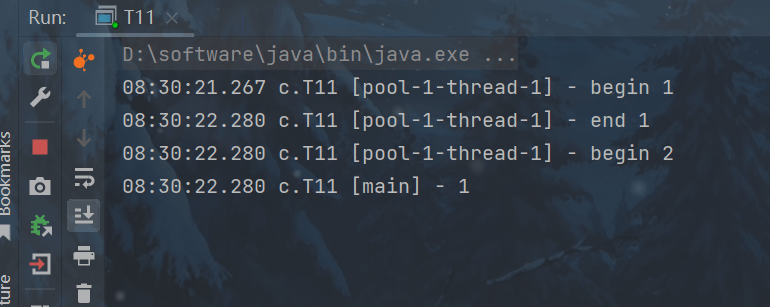
invokeAny方法
// 提交 tasks 中所有任务,哪个任务先成功执行完毕,返回此任务执行结果,其它任务取消 <T>T invokeAny(Collection<? extends Callable> tasks) throws InterruptedException, ExecutionException;
// 提交 tasks 中所有任务,哪个任务先成功执行完毕,返回此任务执行结果,其它任务取消,带超时时间 <T>T invokeAny(Collection<? extends Callable> tasks, long timeout, TimeUnit unit) throws InterruptedException, ExecutionException, TimeoutException;
代码演示:
package cn.yutian.test;
import lombok.extern.slf4j.Slf4j;
import java.util.Arrays;
import java.util.List;
import java.util.concurrent.*;
@Slf4j(topic = "c.T11")
public class T11 {
public static void main(String[] args) throws ExecutionException, InterruptedException {
ExecutorService pool = Executors.newFixedThreadPool(1);
String result = pool.invokeAny(Arrays.asList(
() -> {
log.debug("begin 1");
Thread.sleep(1000);
log.debug("end 1");
return "1";
},
() -> {
log.debug("begin 2");
Thread.sleep(500);
log.debug("end 2");
return "2";
},
() -> {
log.debug("begin 3");
Thread.sleep(2000);
log.debug("end 3");
return "3";
}
));
log.debug("{}", result);
}
}
shutdown方法
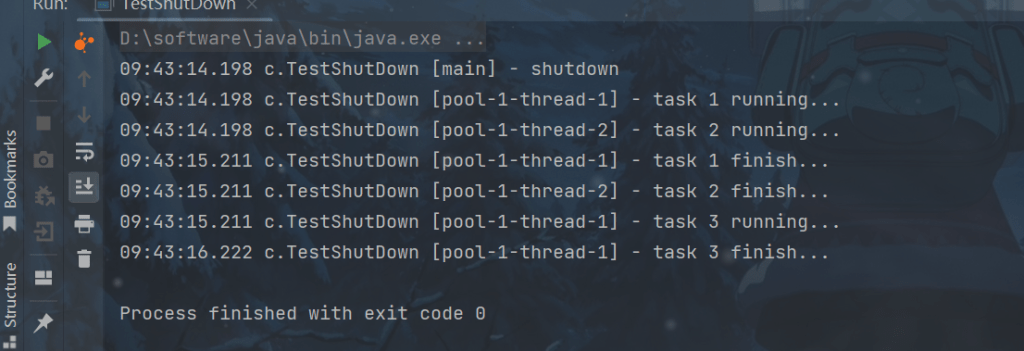
线程池状态变为 SHUTDOWN,不会接收新任务,但已提交任务会执行完,此方法不会阻塞调用线程的执行。
public void shutdown() {
final ReentrantLock mainLock = this.mainLock;
mainLock.lock();
try {
checkShutdownAccess();
// 修改线程池状态
advanceRunState(SHUTDOWN);
// 仅会打断空闲线程
interruptIdleWorkers();
onShutdown(); // 扩展点 ScheduledThreadPoolExecutor
} finally {
mainLock.unlock();
}
// 尝试终结(没有运行的线程可以立刻终结,如果还有运行的线程也不会等)
tryTerminate();
}代码演示:
package cn.yutian.n8;
import lombok.extern.slf4j.Slf4j;
import java.util.concurrent.*;
@Slf4j(topic = "c.TestShutDown")
public class TestShutDown {
public static void main(String[] args) throws ExecutionException, InterruptedException {
ExecutorService pool = Executors.newFixedThreadPool(2);
Future<Integer> result1 = pool.submit(() -> {
log.debug("task 1 running...");
Thread.sleep(1000);
log.debug("task 1 finish...");
return 1;
});
Future<Integer> result2 = pool.submit(() -> {
log.debug("task 2 running...");
Thread.sleep(1000);
log.debug("task 2 finish...");
return 2;
});
Future<Integer> result3 = pool.submit(() -> {
log.debug("task 3 running...");
Thread.sleep(1000);
log.debug("task 3 finish...");
return 3;
});
log.debug("shutdown");
pool.shutdown();
}
}
shutdownNow
线程池状态变为 STOP, 不会接收新任务,会将队列中的任务返回,并用 interrupt 的方式中断正在执行的任务。
public List shutdownNow() {
List<Runnable> tasks;
final ReentrantLock mainLock = this.mainLock;
mainLock.lock();
try {
checkShutdownAccess();
// 修改线程池状态
advanceRunState(STOP);
// 打断所有线程
interruptWorkers();
// 获取队列中剩余任务
tasks = drainQueue();
} finally {
mainLock.unlock();
}
// 尝试终结
tryTerminate();
return tasks;
}代码演示:还是上面的代码,改一下:
log.debug("shutdown");
List<Runnable> runnables = pool.shutdownNow();
log.debug("other.... {}" , runnables);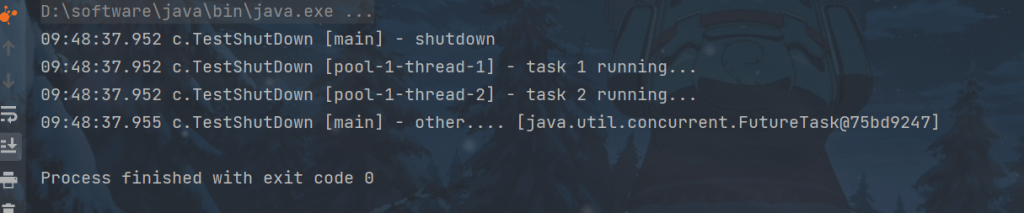
其他方法:
// 不在 RUNNING 状态的线程池,此方法就返回 true boolean isShutdown(); // 线程池状态是否是 TERMINATED boolean isTerminated(); // 调用 shutdown 后,由于调用线程并不会等待所有任务运行结束,因此如果它想在线程池 TERMINATED 后做些事 情,可以利用此方法等待 boolean awaitTermination(long timeout, TimeUnit unit) throws InterruptedException;
代码演示:
log.debug("shutdown");
pool.shutdown();
pool.awaitTermination(3, TimeUnit.SECONDS);
log.debug("----------");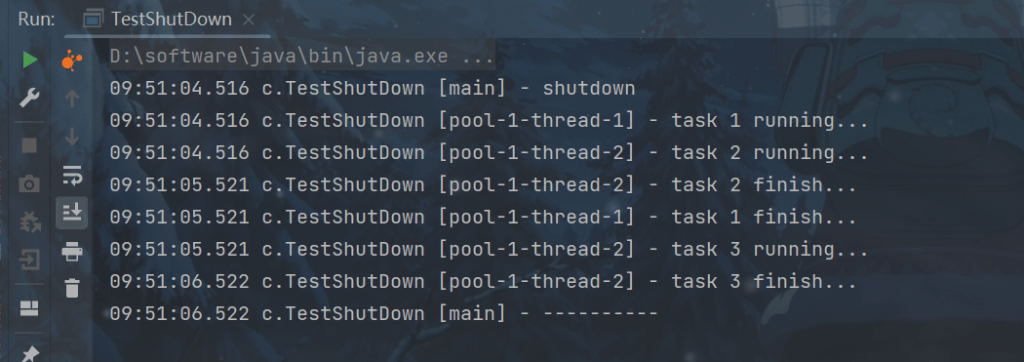
4.创建多少线程池合适呢
- 过小会导致程序不能充分地利用系统资源、容易导致饥饿
- 过大会导致更多的线程上下文切换,占用更多内存
1.CPU 密集型运算
通常采用 cpu 核数 + 1 能够实现最优的 CPU 利用率,+1 是保证当线程由于页缺失故障(操作系统)或其它原因导致暂停时,额外的这个线程就能顶上去,保证 CPU 时钟周期不被浪费
2.I/O 密集型运算
CPU 不总是处于繁忙状态,例如,当你执行业务计算时,这时候会使用 CPU 资源,但当你执行 I/O 操作时、远程RPC 调用时,包括进行数据库操作时,这时候 CPU 就闲下来了,你可以利用多线程提高它的利用率。
经验公式如下:
线程数 = 核数 * 期望 CPU 利用率 * 总时间(CPU计算时间+等待时间) / CPU 计算时间。
- 例如 4 核 CPU 计算时间是 50% ,其它等待时间是 50%,期望 cpu 被 100% 利用,套用公式4 * 100% * 100% / 50% = 8
- 例如 4 核 CPU 计算时间是 10% ,其它等待时间是 90%,期望 cpu 被 100% 利用,套用公式
4 * 100% * 100% / 10% = 40
5.任务调度线程池
在『任务调度线程池』功能加入之前,可以使用 java.util.Timer 来实现定时功能,Timer 的优点在于简单易用,但由于所有任务都是由同一个线程来调度,因此所有任务都是串行执行的,同一时间只能有一个任务在执行,前一个任务的延迟或异常都将会影响到之后的任务。出现异常也全部中断
package cn.yutian.test;
import lombok.extern.slf4j.Slf4j;
import java.util.Timer;
import java.util.TimerTask;
import java.util.concurrent.*;
import static cn.yutian.n2.util.Sleeper.sleep;
@Slf4j(topic = "c.T11")
public class T11 {
public static void main(String[] args) throws ExecutionException, InterruptedException {
Timer timer = new Timer();
TimerTask task1 = new TimerTask() {
@Override
public void run() {
log.debug("task 1");
sleep(2);
}
};
TimerTask task2 = new TimerTask() {
@Override
public void run() {
log.debug("task 2");
}
};
log.debug("start...");
timer.schedule(task1, 1000);
timer.schedule(task2, 1000);
}
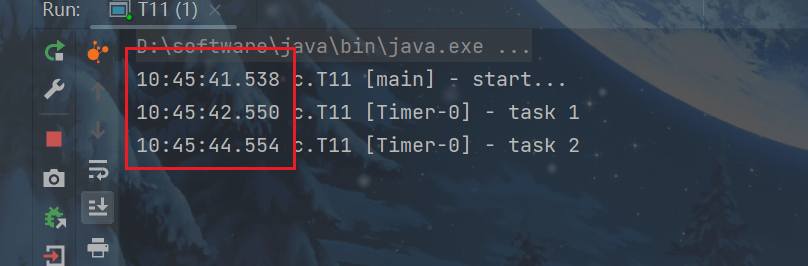
}使用 timer 添加两个任务,希望它们都在 1s 后执行,但由于 timer 内只有一个线程来顺序执行队列中的任务,因此任务1的延时,影响了任务2的执行。
使用 ScheduledExecutorService 改写:
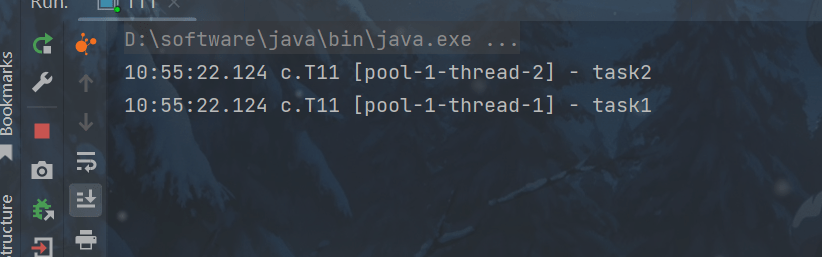
出现异常也不会中断,但是也不会出现在控制台 ,需要自己处理执行任务异常, 正确处理执行任务异常将在后面说
package cn.yutian.test;
import lombok.extern.slf4j.Slf4j;
import java.util.concurrent.*;
@Slf4j(topic = "c.T11")
public class T11 {
public static void main(String[] args) throws ExecutionException, InterruptedException {
ScheduledExecutorService pool = Executors.newScheduledThreadPool(1);
pool.schedule(() -> {
log.debug("task1");
int i = 1 / 0;
}, 1, TimeUnit.SECONDS);
pool.schedule(() -> {
log.debug("task2");
}, 1, TimeUnit.SECONDS);
}
}
scheduleAtFixedRate定时执行任务:
package cn.yutian.test;
import lombok.extern.slf4j.Slf4j;
import java.util.concurrent.*;
@Slf4j(topic = "c.T11")
public class T11 {
public static void main(String[] args) throws ExecutionException, InterruptedException {
ScheduledExecutorService pool = Executors.newScheduledThreadPool(1);
log.debug("start...");
pool.scheduleAtFixedRate(() -> {
log.debug("running...");
}, 1, 1, TimeUnit.SECONDS);
}
}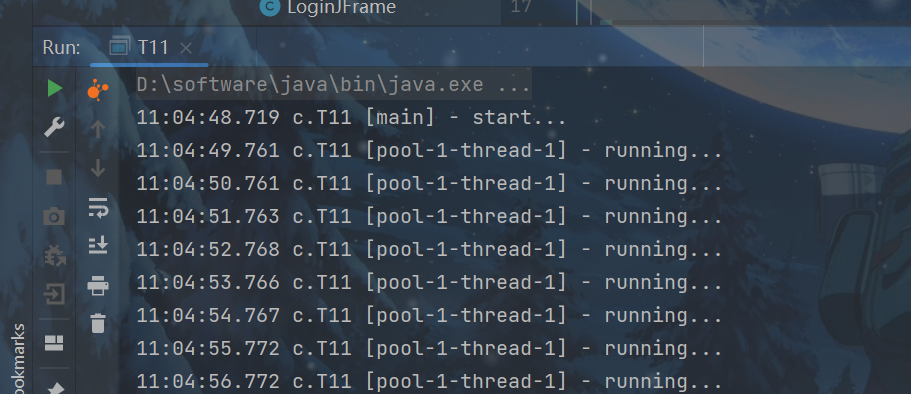
如果任务执行时间超过了间隔时间,由于任务执行时间 > 间隔时间,间隔会被撑大
scheduleWithFixedDelay 例子
scheduleWithFixedDelay 的间隔是 上一个任务结束 <-> 延时 <-> 下一个任务开始,所
以间隔都是 3s
ScheduledExecutorService pool = Executors.newScheduledThreadPool(1);
log.debug("start...");
pool.scheduleWithFixedDelay(()-> {
log.debug("running...");
try {
sleep(2);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
}, 1, 1, TimeUnit.SECONDS);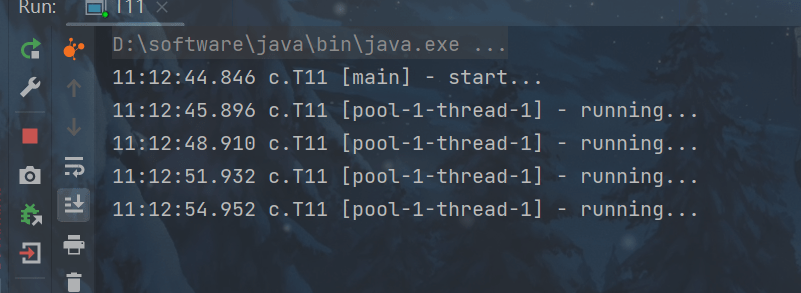
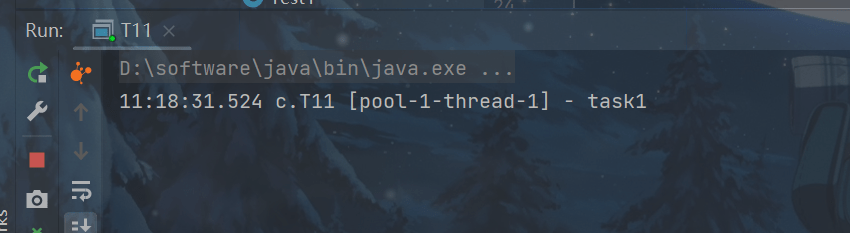
6.正确处理任务异常
注意:任务异常平不会出现
ExecutorService pool = Executors.newFixedThreadPool(1);
pool.submit(() -> {
log.debug("task1");
int i = 1 / 0;
});
正确处理执行任务异常:
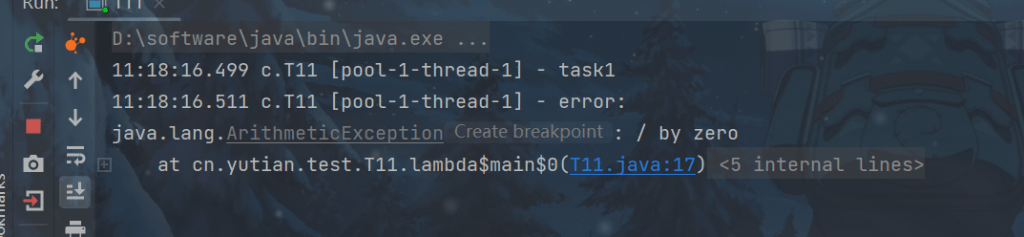
1.主动捉异常
ExecutorService pool = Executors.newFixedThreadPool(1);
pool.submit(() -> {
try {
log.debug("task1");
int i = 1 / 0;
} catch (Exception e) {
log.error("error:", e);
}
});
2:使用 Future
ExecutorService pool = Executors.newFixedThreadPool(1);
Future<Boolean> f = pool.submit(() -> {
log.debug("task1");
int i = 1 / 0;
return true;
});
log.debug("result:{}", f.get());
7.定期执行
如何让每周四 18:00:00 定时执行任务?
package cn.yutian.n8;
import java.time.DayOfWeek;
import java.time.Duration;
import java.time.LocalDateTime;
import java.util.concurrent.Executors;
import java.util.concurrent.ScheduledExecutorService;
import java.util.concurrent.TimeUnit;
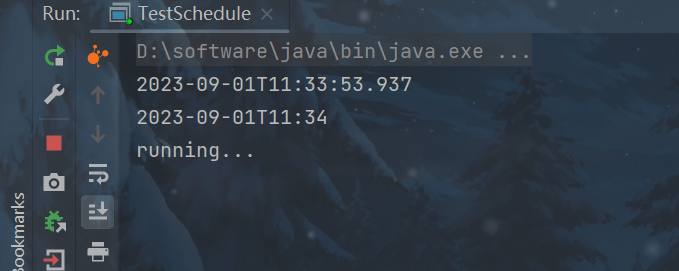
public class TestSchedule {
// 如何让每周四 18:00:00 定时执行任务?
public static void main(String[] args) {
// 获取当前时间
LocalDateTime now = LocalDateTime.now();
System.out.println(now);
// 获取周四时间
LocalDateTime time = now.withHour(11).withMinute(34).withSecond(0).withNano(0).with(DayOfWeek.FRIDAY);
// 如果 当前时间 > 本周周四,必须找到下周周四
if(now.compareTo(time) > 0) {
time = time.plusWeeks(1);
}
System.out.println(time);
// initailDelay 代表当前时间和周四的时间差
// period 一周的间隔时间
long initailDelay = Duration.between(now, time).toMillis();
long period = 1000 * 60 * 60 * 24 * 7;
ScheduledExecutorService pool = Executors.newScheduledThreadPool(1);
pool.scheduleAtFixedRate(() -> {
System.out.println("running...");
}, initailDelay, period, TimeUnit.MILLISECONDS);
}
}
8.Tomcat 线程池
Tomcat 在哪里用到了线程池:
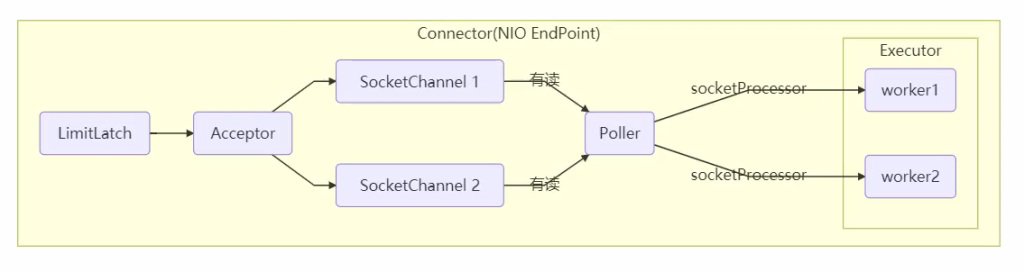
- LimitLatch 用来限流,可以控制最大连接个数,类似 J.U.C 中的 Semaphore
- Acceptor 只负责接收新的 socket 连接
- Poller 只负责监听 socket channel 是否有可读的 I/O 事件
- 一旦可读,封装一个任务对象(socketProcessor),提交给 Executor 线程池处理
- Executor 线程池中的工作线程最终负责处理请求
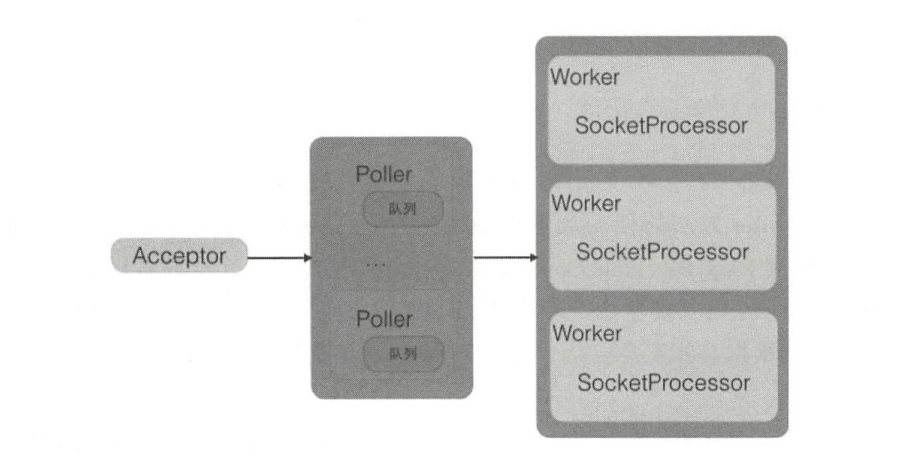
- Acceptor是套接字接受线程(Socket acceptor thread),用来接受用户的请求,并把请求封装为事件任务放入Poller的队列,一个Connector里面只有一个
- AcceptorPoller 是套接字处理线程(Socket poller thread),每个 Poller 内部都有一个独有的队列, Poller线程则从自己的队列里面获取具体的事件任务,然后将其交给Worker进行处理。Poller 线程的个数与处理器的核数有关,
- Worker是实际处理请求的线程,Worker只是组件名字,真正做事情的是SocketProcessor,它是Poller线程从自己的队列获取任务后的真正任务执行者。
Tomcat 线程池扩展了 ThreadPoolExecutor,稍有不同:
如果总线程数达到 maximumPoolSize,这时不会立刻抛 RejectedExecutionException 异常,而是再次尝试将任务放入队列,如果还失败,才抛出 RejectedExecutionException 异常
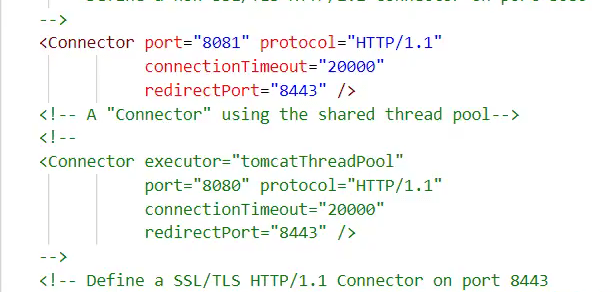
Tomcat源码server.xml
Connector 配置
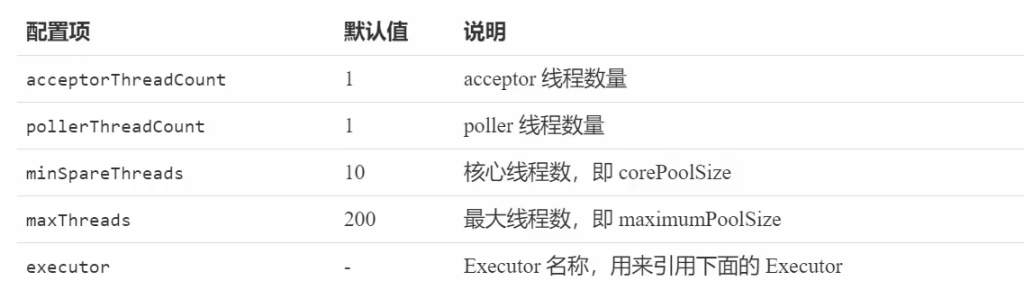
Executor 线程配置

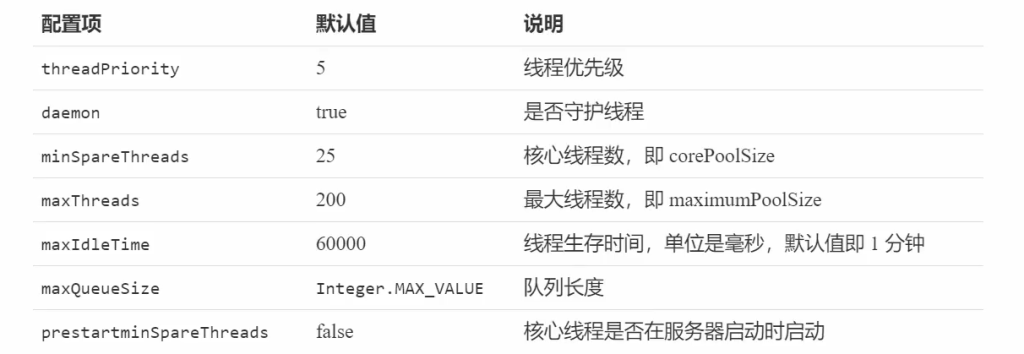
创建救急线程,逻辑改变
3. Fork/Join
- Fork/Join 是 JDK 1.7 加入的新的线程池实现,它体现的是一种分治思想,适用于能够进行任务拆分的 cpu 密集型运算。
- 所谓的任务拆分,是将一个大任务拆分为算法上相同的小任务,直至不能拆分可以直接求解。跟递归相关的一些计算,如归并排序、斐波那契数列、都可以用分治思想进行求解。
- Fork/Join 在分治的基础上加入了多线程,可以把每个任务的分解和合并交给不同的线程来完成,进一步提升了运算效率。
- Fork/Join 默认会创建与 cpu 核心数大小相同的线程池。
提交给 Fork/Join 线程池的任务需要继承 RecursiveTask(有返回值)或RecursiveAction(没有返回值),例如下面定义了一个对 1~n 之间的整数求和的任务
package cn.yutian.n8;
import lombok.extern.slf4j.Slf4j;
import java.util.concurrent.ForkJoinPool;
import java.util.concurrent.RecursiveTask;
@Slf4j(topic = "c.TestForkJoin2")
public class TestForkJoin2 {
public static void main(String[] args) {
ForkJoinPool pool = new ForkJoinPool(4);
System.out.println(pool.invoke(new MyTask(5)));
// new MyTask(5) 5+ new MyTask(4) 4 + new MyTask(3) 3 + new MyTask(2) 2 + new MyTask(1)
}
}
// 1~n 之间整数的和
@Slf4j(topic = "c.MyTask")
class MyTask extends RecursiveTask<Integer> {
private int n;
public MyTask(int n) {
this.n = n;
}
@Override
public String toString() {
return "{" + n + '}';
}
@Override
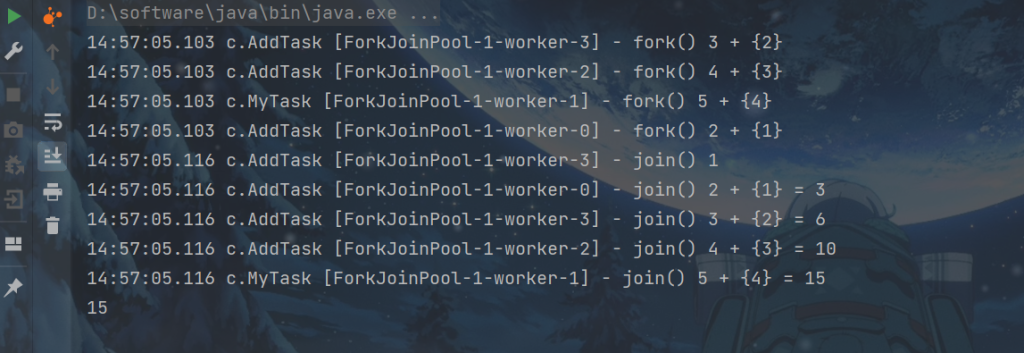
protected Integer compute() {
// 如果 n 已经为 1,可以求得结果了
if (n == 1) {
log.debug("join() {}", n);
return n;
}
// 将任务进行拆分(fork)
AddTask1 t1 = new AddTask1(n - 1);
t1.fork();
log.debug("fork() {} + {}", n, t1);
// 合并(join)结果
int result = n + t1.join();
log.debug("join() {} + {} = {}", n, t1, result);
return result;
}
}
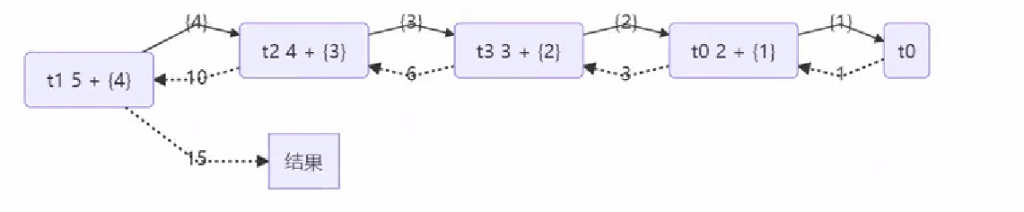
优化:
class AddTask3 extends RecursiveTask<Integer> {
int begin;
int end;
public AddTask3(int begin, int end) {
this.begin = begin;
this.end = end;
}
@Override
public String toString() {
return "{" + begin + "," + end + '}';
}
@Override
protected Integer compute() {
// 5, 5
if (begin == end) {
log.debug("join() {}", begin);
return begin;
}
// 4, 5
if (end - begin == 1) {
log.debug("join() {} + {} = {}", begin, end, end + begin);
return end + begin;
}
// 1 5
int mid = (end + begin) / 2; // 3
AddTask3 t1 = new AddTask3(begin, mid); // 1,3
t1.fork();
AddTask3 t2 = new AddTask3(mid + 1, end); // 4,5
t2.fork();
log.debug("fork() {} + {} = ?", t1, t2);
int result = t1.join() + t2.join();
log.debug("join() {} + {} = {}", t1, t2, result);
return result;
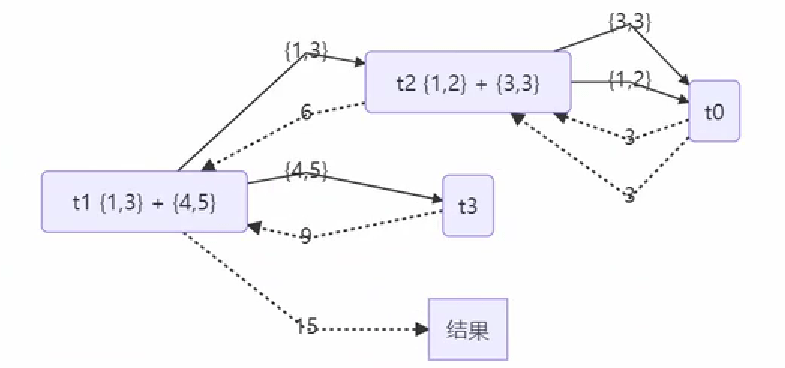
}
}
4. 获取线程池状态
如果想在线程池外部去获得线程池内部任务的执行状态,有几种方法可以实现。
1.isTerminated()方法可以判断线程池的运行状态,但是需要程序中主动调用了线程池的 shutdown()方法。
package n4;
import java.util.concurrent.*;
public class tt1 {
public static void main(String[] args) throws InterruptedException {
ExecutorService service = Executors.newFixedThreadPool(3);
service.submit(() -> {
System.out.println("begin...");
try {
Thread.sleep(1);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
System.out.println("end...");
});
service.submit(() -> {
System.out.println("begin...");
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
System.out.println("end..." );
});
service.submit(() -> {
System.out.println("begin...");
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
System.out.println("end...");
});
service.submit(() -> {
try {
Thread.sleep(3000);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
service.shutdown();
});
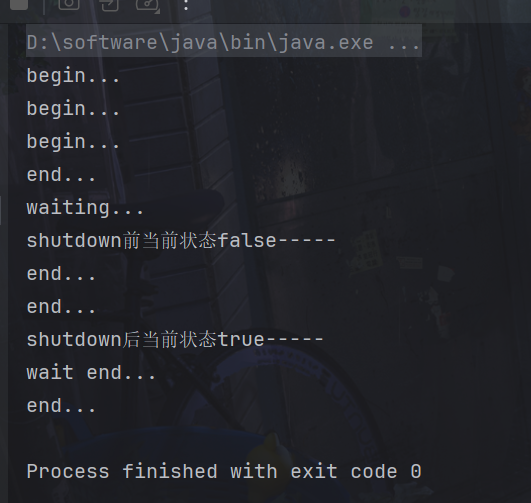
try {
System.out.println("waiting...");
System.out.println("shutdown前当前状态" + service.isTerminated() + "-----");
Thread.sleep(4000);
System.out.println("shutdown后当前状态" + service.isTerminated() + "-----");
System.out.println("wait end...");
System.out.println("end...");
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
}
}输出如下:
2..get()方法,get()方法来获得任务的执行结果,当线程池中的任务没执行完之前,
future.get()方法会一直阻塞,直到任务执行结束。
package n4;
import java.util.concurrent.*;
import lombok.extern.slf4j.Slf4j;
@Slf4j(topic = "c.TT")
public class tt2 {
public static void main(String[] args) throws InterruptedException {
ExecutorService service = Executors.newFixedThreadPool(4);
Future<Integer> submit1 = service.submit(() -> {
log.debug("begin...");
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
log.debug("end...");
return 1;
});
Future<Integer> submit2 = service.submit(() -> {
log.debug("begin...");
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
log.debug("end...");
return 2;
});
Future<Integer> submit3 = service.submit(() -> {
log.debug("begin...");
try {
Thread.sleep(9000);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
log.debug("end...");
return 3;
});
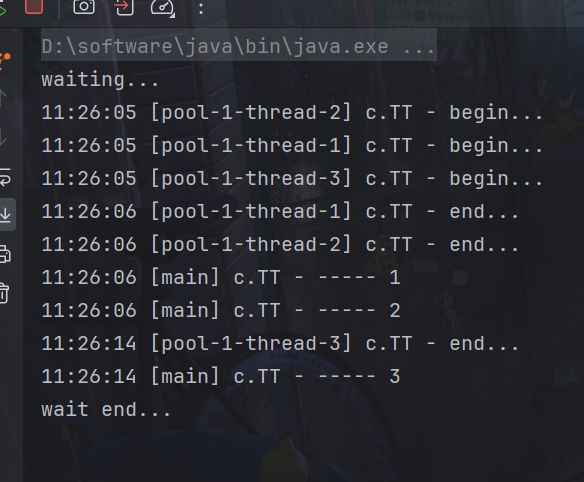
System.out.println("waiting...");
try {
log.debug("----- " + submit1.get());
log.debug("----- " + submit2.get());
log.debug("----- " + submit3.get());
} catch (ExecutionException e) {
throw new RuntimeException(e);
}
System.out.println("wait end...");
}
}运行:
3.还有方法就是下面的Java 并发包中线程同步器
参考资料
黑马程序员深入学习Java并发编程:https://www.bilibili.com/video/BV16J411h7Rd
汪文君著《Java高并发编程详解》
翟陆续著《Java并发编程之美》