代码、内容参考来自于包括《操作系统真象还原》、《一个64位操作系统的设计与实现》以及《ORANGE’S:一个操作系统的实现》。
内存的使用都是通过位图来管理的,无论内存的分配或释放,本质上都是在设置相关位图中的相应位,都是在读写位图。回收物理地址就是将物理内存池位图中的相应位清0,无需将该4KB物理页框逐字节清0。回收虚拟地址就是将虚拟内存池位图中的相应位清0。分配则是相反的,也就是将位图中相应位置为1 即可。
我们分配内存时在函数malloc_page中,步骤如下:
- 在虚拟地址池中分配虚拟地址,相关的函数是vaddr_get,此函数操作的是内核虚拟内存池位图”kernel_vaddr.vaddr_bitmap”或用户虚拟内存池位图”pcb->userprog_vaddr.vaddr_bitmap”。
- 在物理内存池中分配物理地址,相关的函数是palloc,此函数操作的是内核物理内存池位图”kernel_pool->pool_bitmap”或用户物理内存池位图”user_pool->pool_bitmap”。
- 在页表中完成虚拟地址到物理地址的映射,相关的函数是page_table_add。
对应,释放内存方法定义在函数mfree_page:
- 在物理地址池中释放物理页地址,相关的函数是pfree,操作的位图同palloc。
- 在页表中去掉虚拟地址的映射,原理是将虚拟地址对应pte的P位置0,相关的函数是page_tablepte_remove。
- 在虚拟地址池中释放虚拟地址,相关的函数是vaddr_remove,操作的位图同vaddr_get。
接下来就是实现函数mfree_page了。
同样修改/kernel/memory.c
先定义三个函数:
/* 将物理地址 pg_phy_addr 回收到物理内存池 */
void pfree(uint32_t pg_phy_addr) {
struct pool* mem_pool;
uint32_t bit_idx = 0;
if(pg_phy_addr >= user_pool.phy_addr_start) {
// 用户物理内存池
mem_pool = &user_pool;
bit_idx = (pg_phy_addr - user_pool.phy_addr_start) / PG_SIZE;
} else {
// 内核物理内存池
mem_pool = &kernel_pool;
bit_idx = (pg_phy_addr - kernel_pool.phy_addr_start) / PG_SIZE;
}
bitmap_set(&mem_pool->pool_bitmap, bit_idx, 0); // 将位图中该位清 0
}
/* 去掉页表中虚拟地址 vaddr 的映射, 只去掉 vaddr 对应的 pte */
static void page_table_pte_remove(uint32_t vaddr) {
uint32_t* pte = pte_ptr(vaddr);
*pte &= ~PG_P_1; // 将页表项 pte 的 P 位置 0
asm volatile("invlpg %0" : : "m"(vaddr) : "memory"); // 更新 tlb
}
/* 在虚拟地址池中释放以 _vaddr 起始的连续 pg_cnt 个虚拟页地址 */
static void vaddr_remove(enum pool_flags pf, void* _vaddr, uint32_t pg_cnt) {
uint32_t bit_idx_start = 0, vaddr = (uint32_t) _vaddr, cnt = 0;
if(pf == PF_KERNEL) {
// 内核虚拟内存池
bit_idx_start = (vaddr - kernel_vaddr.vaddr_start) / PG_SIZE;
while(cnt < pg_cnt) {
bitmap_set(&kernel_vaddr.vaddr_bitmap, bit_idx_start + (cnt++), 0);
}
} else {
// 用户虚拟内存池
struct task_struct* cur_thread = running_thread();
bit_idx_start = (vaddr - cur_thread->userprog_vaddr.vaddr_start) / PG_SIZE;
while(cnt < pg_cnt) {
bitmap_set(&cur_thread->userprog_vaddr.vaddr_bitmap, bit_idx_start + (cnt++), 0);
}
}
}函数pfree接受一个参数,即物理页框地址pg_phy_addr,功能是将物理页框回收到相应的物理内存池,也就是只回收一个物理页。先根据物理地址池的起始地址判断pg_phy_addr属于哪个物理内存池,用变量mem_pool指向物理内存池,bit_idx为物理地址在相应物理内存池中的偏移量,最后通过代码”bitmap_set(&mem_pool->pool_bitmap, bit_idx, 0)”在位图中回收该位。
函数page_table_pte_remove接受一个参数,即虚拟地址vaddr,将pte中的P位置0。函数体中,先调用pte_ptr(vaddr)获取虚拟地址所在的pte指针,然后在下一行,通过代码”*pte &=~PG_P_1″使pte中的P位取反为0。除此之外,就是刷新tlb。pte已经被修改,因此咱们要把此pte更新到tlb中,tlb页表的高速缓存,俗称快表,tlb是处理器提供的、用于加速虚拟地址到物理地址的转换过程。当页表发生变化时,tlb中缓存的数据也应该及时更新,否则程序会运行出错。更新TLB有两种方式,一是用invlpg指令更新单条虚拟地址条目,另外一个是重新加载cr3寄存器,这将直接清空TLB,相当于更新整个页表。这里只更新了虚拟地址vaddr对应的pte,invlpg指令去单独更新vaddr对应的缓存。invlpg的指令格式为”invlpg m”,其中m是操作数,表示虚拟地址内存,m并不是立即数形式的虚拟地址,它必须是实实在在的内存地址的形式。比如更新虚拟地址0x12345678的缓存,指令是 invalpg [0x12345678],而不是 invalpg 0x12345678,invalpg是汇编指令,因此用下面的一行内联汇编代码”asm volatile (“invlpg %0″::”m” (vaddr):”memory”)”来更新虚拟地址vaddr在 tlb缓存中的条目,也就是把页表中vaddr所在的pte重新写入tlb。invlpg的操作数m是内存地址,因此位于内联汇编代码输入部中的vaddr,其约束是内存约束m。
函数是vaddr_remove接受3个参数,pf是虚拟内存池标志,_vaddr是待释放的虚拟地址,pg_cnt是连续的虚拟页框数。函数功能是在虚拟地址池中释放以_vaddr起始的连续pg_cnt个虚拟页地址。虚拟内存地址的管理是在虚拟内存池的位图中,因此先根据pf判断是处理哪个虚拟内存池,然后再用位图函数bitmap_set将虚拟地址在虚拟内存池位图中相应的位清0。如果是内核,就针对内核的虚拟内存池kernel_vaddr操作,先bit_idx_start = (vaddr – kernel_vaddr.vaddr_start) / PG_SIZE计算虚拟地址vaddr在位图kernel_vaddr中的偏移量,存入变量bit_idx_start中,然后循环pg_cnt次,依次将虚拟内存池位图中的相应位清0,针对用户虚拟内存池的处理与此同理。
接下来整合到函数mfree_page
修改/kernel/memory.c
添加mfree_page函数
/* 释放以虚拟地址 vaddr 为起始的 cnt 个物理页框 */
void mfree_page(enum pool_flags pf, void* _vaddr, uint32_t pg_cnt) {
uint32_t pg_phy_addr;
uint32_t vaddr = (uint32_t) _vaddr, page_cnt = 0;
ASSERT(pg_cnt >= 1 && vaddr % PG_SIZE == 0);
// 获取虚拟地址 vaddr 对应的物理地址
pg_phy_addr = addr_v2p(vaddr);
// 确保待释放的物理内存在低端 1MB+1KB 大小的页目录 + 1KB 大小的页表地址外
ASSERT((pg_phy_addr % PG_SIZE) == 0 && pg_phy_addr >= 0x102000);
// 判断 pg_phy_addr 属于用户物理内存池还是内核物理内存池
if(pg_phy_addr >= user_pool.phy_addr_start) {
// 位于用户物理内存池
vaddr -= PG_SIZE;
while(page_cnt < pg_cnt) {
vaddr += PG_SIZE;
pg_phy_addr = addr_v2p(vaddr);
// 确保物理地址属于用户物理地址池
ASSERT((pg_phy_addr % PG_SIZE) == 0 && pg_phy_addr >= user_pool.phy_addr_start);
// 先将对应的物理页框归还到内存池
pfree(pg_phy_addr);
// 再从页表中清除此虚拟地址所在的页表项 pte
page_table_pte_remove(vaddr);
page_cnt++;
}
// 清空虚拟地址的位图中的相应位
vaddr_remove(pf, _vaddr, pg_cnt);
} else {
// 位于内核物理内存池
vaddr -= PG_SIZE;
while (page_cnt < pg_cnt) {
vaddr += PG_SIZE;
pg_phy_addr = addr_v2p(vaddr);
// 确保待释放的物理内存只属于内核物理地址池
ASSERT((pg_phy_addr % PG_SIZE) == 0 &&
pg_phy_addr >= kernel_pool.phy_addr_start &&
pg_phy_addr < user_pool.phy_addr_start);
// 先将对应的物理页框归还到内存池
pfree(pg_phy_addr);
// 再从页表中清除此虚拟地址所在的页表框 pte
page_table_pte_remove(vaddr);
page_cnt++;
}
// 清空虚拟地址的位图中的相应位
vaddr_remove(pf, _vaddr, pg_cnt);
}
}mfree_page函数接受3个参数,pf是内存池标志,_vaddr是待释放的虚拟地址,pg_cnt是连续的页框数,功能是释放以虚拟地址vaddr为起始的cnt个物理页框。
内存回收工作分为三大步骤,先调用pfree清空物理地址位图中的相应位,再调用page_table_pte_remove删除页表中此地址的pte,最后调用vaddr_remove清除虚拟地址位图中的相应位。
pg_phy_addr = addr_v2p(vaddr)先调用addr_v2p(vaddr)获取虚拟地址vaddr对应的物理地址,将其保存在pg_phy_addr 中,然后根据pg_phy_addr的值判断它属于内核的物理内存池还是用户物理内存池。 内核物理内存池 kernel_pool的地址位于用户物理内存池user_pool的前面,即kernel_pool的地址在低地址处,所以可以通过代码”if (pg_phy_addr >= user_pool.phy_addr_start)”判断物理地址pg_phy_addr所属的物理内存池。 如果pg_phy_addr大于user_pool的起始物理地址,说明pg_phy_addr属于用户内存池。
接下来是针对用户物理内存池的处理,通过while循环处理pg_cnt个页框,每个循环中,都是调用addr_v2p(vaddr)得到vaddr 的物理地址pg_phy_addr,然后调用pfree(pg_phy_addr)在物理内存池位图中清0相应位。 再调用page_table pte_remove(vaddr)清除pte,pg_cnt个页框处理完成后,再调用函数vaddr_remove(pf,_vaddr, pg_cnt)在虚拟地址池位图中清0相应位。 后面针对内核内存池的逻辑是一样的。
上面实现的mfree_page只能释放页框级别的内存块。 sys_free 是内存释放的统一接口,无论是页框级别的内存和小的内存块,都统一用sys_free处理。 sys_free针对这两种内存的处理有各自的方法,对于大内存的处理称之为释放,就是把页框在虚拟内存池和物理内存池的位图中将相应位置0。对于小内存的处理称之为回收,是将arena中的内存块重新放回到内存块描述符中的空闲块链表free_list。
同样修改/kernel/memory.c
添加sys_free函数
sys_free只接受1个参数,内存指针ptr,函数功能是释放ptr指向的内存。
/* 回收内存 ptr */
void sys_free(void* ptr) {
ASSERT(ptr != NULL);
if(ptr != NULL) {
enum pool_flags PF;
struct pool* mem_pool;
// 判断是线程, 还是进程
if(running_thread()->pgdir == NULL) {
ASSERT((uint32_t) ptr >= K_HEAP_START);
PF = PF_KERNEL;
mem_pool = &kernel_pool;
} else {
PF = PF_USER;
mem_pool = &user_pool;
}
lock_acquire(&mem_pool->lock);
struct mem_block* b = ptr;
// 把 mem_block 转换成 arena, 获取元信息
struct arena* a = block2arena(b);
ASSERT(a->large == 0 || a->large == 1);
if(a->desc == NULL && a->large == true) {
// 大于 1024 的内存
mfree_page(PF, a, a->cnt);
} else {
// 小于等于 1024 的内存块
// 先将内存块回收到 free_list
list_append(&a->desc->free_list, &b->free_elem);
// 再判断此 arena 中的内存块是否都是空闲, 如果是就释放 arena(整个arena)
if(++a->cnt == a->desc->blocks_per_arena) {
uint32_t block_idx;
for(block_idx = 0; block_idx < a->desc->blocks_per_arena; block_idx++) {
struct mem_block* b = arena2block(a, block_idx);
ASSERT(elem_find(&a->desc->free_list, &b->free_elem));
list_remove(&b->free_elem);
}
mfree_page(PF, a, 1);
}
}
lock_release(&mem_pool->lock);
}
}在函数体前部,判断调用者是内核线程,还是用户进程,并初始化内存池标记PF和内存池指针mem_pool。随后在struct mem_block* b = ptr将ptr赋值给内存块指针b,然后通过”struct arena* a=block2arena(b)”获取内存块b所在的 arena指针,此目的是获取arena中的元信息,通过元信息中的变量desc和large的值分别进行下一步处理。
如果a->desc的值为NULL并且a->large的值为true,这说明待释放的内存(也就是ptr指向的内存)并不是在arena中的小内存块,而是大于1024字节的大内存,其大小是1个或多个页框,页框的数量是由arena元信息中的变量cnt记录的。这是我们在sysmalloc中进行内存分配时约定好的, “a->desc为NULL,并且a->large为true”表示此arena只被用于大内存分配,并不是被拆分成多个内存块,因此不存在此arena被多次共享的情况,完全可以释放。如果代码”if (a->desc==NULL && a->large==true)”条件成立的话,就调用”mfree_page(PF, a, a->cnt)”释放a->cnt个页框。如果不成立的话,表示待释放的内存是小内存块,流程就进入了“list_append(&a->desc->free_list, &b->free_elem)”,将此内存块回收到此内存块描述符的free_list中。
接下来在if(++a->cnt == a->desc->blocks_per_arena) 将“++a->cnt”后的结果与内存块描述符中的blocks_per_arena比较,如果相等,这表示此arena中的空闲内存块已经达到最大数,说明此arena已经没人使用了,可以释放。
接下来通过for循环,将此arena中的所有内存块从内存块描述符的free_list中去掉,遍历结束后,通 过”mfree_page(PF, a, 1)”释放此arena。
对应在/kernel/memory.h添加三个函数
/* 释放以虚拟地址 vaddr 为起始的 cnt 个物理页框 */ void mfree_page(enum pool_flags pf, void* _vaddr, uint32_t pg_cnt); /* 将物理地址 pg_phy_addr 回收到物理内存池 */ void pfree(uint32_t pg_phy_addr); /* 回收内存 ptr */ void sys_free(void* ptr); void* sys_malloc(uint32_t size);
接下来修改main.c文件看看效果
#include "print.h"
#include "init.h"
#include "debug.h"
#include "memory.h"
#include "thread.h"
#include "interrupt.h"
#include "console.h"
#include "process.h"
#include "syscall-init.h"
#include "syscall.h"
#include "stdio.h"
void k_thread_a(void*);
void k_thread_b(void*);
void u_prog_a(void);
void u_prog_b(void);
int prog_a_pid = 0, prog_b_pid = 0;
int main() {
put_str("I am kernel\n");
init_all();
intr_enable(); // 打开中断, 使时钟中断起作用
thread_start("k_thread_a", 31, k_thread_a, "I am thread_a");
thread_start("k_thread_b", 31, k_thread_b, "I am thread_b ");
while(1);
return 0;
}
/* 在线程中运行的函数 */
void k_thread_a(void* arg) {
char* para = arg;
void* addr1;
void* addr2;
void* addr3;
void* addr4;
void* addr5;
void* addr6;
void* addr7;
console_put_str(" thread_a start\n");
int max = 1000;
while (max-- > 0) {
int size = 128;
addr1 = sys_malloc(size);
size *= 2;
addr2 = sys_malloc(size);
size *= 2;
addr3 = sys_malloc(size);
sys_free(addr1);
addr4 = sys_malloc(size);
size *= 2; size *= 2; size *= 2; size *= 2;
size *= 2; size *= 2; size *= 2;
addr5 = sys_malloc(size);
addr6 = sys_malloc(size);
sys_free(addr5);
size *= 2;
addr7 = sys_malloc(size);
sys_free(addr6);
sys_free(addr7);
sys_free(addr2);
sys_free(addr3);
sys_free(addr4);
}
console_put_str(" thread_a end\n");
while(1);
}
/* 在线程中运行的函数 */
void k_thread_b(void* arg) {
char* para = arg;
void* addr1;
void* addr2;
void* addr3;
void* addr4;
void* addr5;
void* addr6;
void* addr7;
void* addr8;
void* addr9;
int max = 1000;
console_put_str(" thread_b start\n");
while (max-- > 0) {
int size = 9;
addr1 = sys_malloc(size);
size *= 2;
addr2 = sys_malloc(size);
size *= 2;
sys_free(addr2);
addr3 = sys_malloc(size);
sys_free(addr1);
addr4 = sys_malloc(size);
addr5 = sys_malloc(size);
addr6 = sys_malloc(size);
sys_free(addr5);
size *= 2;
addr7 = sys_malloc(size);
sys_free(addr6);
sys_free(addr7);
sys_free(addr3);
sys_free(addr4);
size *= 2; size *= 2; size *= 2;
addr1 = sys_malloc(size);
addr2 = sys_malloc(size);
addr3 = sys_malloc(size);
addr4 = sys_malloc(size);
addr5 = sys_malloc(size);
addr6 = sys_malloc(size);
addr7 = sys_malloc(size);
addr8 = sys_malloc(size);
addr9 = sys_malloc(size);
sys_free(addr1);
sys_free(addr2);
sys_free(addr3);
sys_free(addr4);
sys_free(addr5);
sys_free(addr6);
sys_free(addr7);
sys_free(addr8);
sys_free(addr9);
}
console_put_str(" thread_b end\n");
while(1);
}
/* 测试用户进程 */
void u_prog_a(void) {
char* name = "prog_a";
printf(" I am %s, my pid:%d%c", name, getpid(),'\n');
while(1);
}
/* 测试用户进程 */
void u_prog_b(void) {
char* name = "prog_b";
printf(" I am %s, my pid:%d%c", name, getpid(), '\n');
while(1);
}执行结果如下:
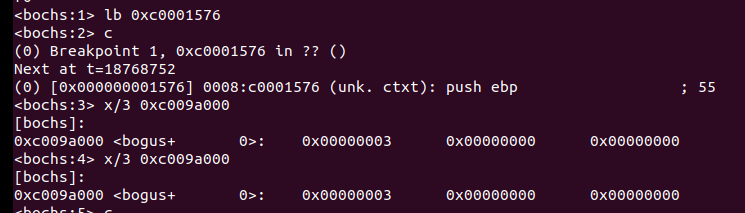
0x3 的二进制是 11,这表示用了 2 个页框,原因是创建两个线程时各用了1个页框做其pcb。
接下来完成系统调用 malloc 和 free
同样修改lib/user/syscall.h
#ifndef __LIB_USER_SYSCALL_H
#define __LIB_USER_SYSCALL_H
#include "stdint.h"
/* 用来存放子功能号 */
enum SYSCALL_NR {
SYS_GETPID,
SYS_WRITE,
SYS_MALLOC,
SYS_FREE
};
uint32_t getpid(void);
uint32_t write(char* str);
void* malloc(uint32_t size);
void free(void* ptr);
#endiflib/user/syscall.c添加两个函数
/* 申请 size 字节大小的内存, 并返回结果 */
void* malloc(uint32_t size) {
return (void*) _syscall1(SYS_MALLOC, size);
}
/* 释放 ptr 指向的内存 */
void free(void* ptr) {
_syscall1(SYS_FREE, ptr);
}
修改userprog/syscall-init.c
#include "memory.h"
/* 初始化系统调用 */
void syscall_init(void) {
put_str("syscall_init start\n");
syscall_table[SYS_GETPID] = sys_getpid;
syscall_table[SYS_WRITE] = sys_write;
syscall_table[SYS_MALLOC] = sys_malloc;
syscall_table[SYS_FREE] = sys_free;
put_str("syscall_init done\n");
}
修改main.c查看结果
#include "print.h"
#include "init.h"
#include "debug.h"
#include "memory.h"
#include "thread.h"
#include "interrupt.h"
#include "console.h"
#include "process.h"
#include "syscall-init.h"
#include "syscall.h"
#include "stdio.h"
void k_thread_a(void*);
void k_thread_b(void*);
void u_prog_a(void);
void u_prog_b(void);
int prog_a_pid = 0, prog_b_pid = 0;
int main() {
put_str("I am kernel\n");
init_all();
intr_enable(); // 打开中断, 使时钟中断起作用
process_execute(u_prog_a, "u_prog_a");
process_execute(u_prog_b, "u_prog_b");
thread_start("k_thread_a", 31, k_thread_a, "I am thread_a");
thread_start("k_thread_b", 31, k_thread_b, "I am thread_b");
while(1);
return 0;
}
/* 在线程中运行的函数 */
void k_thread_a(void* arg) {
void* addr1 = sys_malloc(256);
void* addr2 = sys_malloc(255);
void* addr3 = sys_malloc(254);
console_put_str(" thread_a malloc addr:0x");
console_put_int((int)addr1);
console_put_char(',');
console_put_int((int)addr2);
console_put_char(',');
console_put_int((int)addr3);
console_put_char('\n');
int cpu_delay = 100000;
while(cpu_delay-- > 0);
sys_free(addr1);
sys_free(addr2);
sys_free(addr3);
while(1);
}
/* 在线程中运行的函数 */
void k_thread_b(void* arg) {
void* addr1 = sys_malloc(256);
void* addr2 = sys_malloc(255);
void* addr3 = sys_malloc(254);
console_put_str(" thread_b malloc addr:0x");
console_put_int((int)addr1);
console_put_char(',');
console_put_int((int)addr2);
console_put_char(',');
console_put_int((int)addr3);
console_put_char('\n');
int cpu_delay = 100000;
while(cpu_delay-- > 0);
sys_free(addr1);
sys_free(addr2);
sys_free(addr3);
while(1);
}
/* 测试用户进程 */
void u_prog_a(void) {
void* addr1 = malloc(256);
void* addr2 = malloc(255);
void* addr3 = malloc(254);
printf(" prog_a malloc addr:0x%x,0x%x,0x%x\n", (int)addr1, (int)addr2, (int)addr3);
int cpu_delay = 100000;
while(cpu_delay-- > 0);
free(addr1);
free(addr2);
free(addr3);
while(1);
}
/* 测试用户进程 */
void u_prog_b(void) {
void* addr1 = malloc(256);
void* addr2 = malloc(255);
void* addr3 = malloc(254);
printf(" prog_b malloc addr:0x%x,0x%x,0x%x\n", (int)addr1, (int)addr2, (int)addr3);
int cpu_delay = 100000;
while(cpu_delay-- > 0);
free(addr1);
free(addr2);
free(addr3);
while(1);
}执行结果如下:
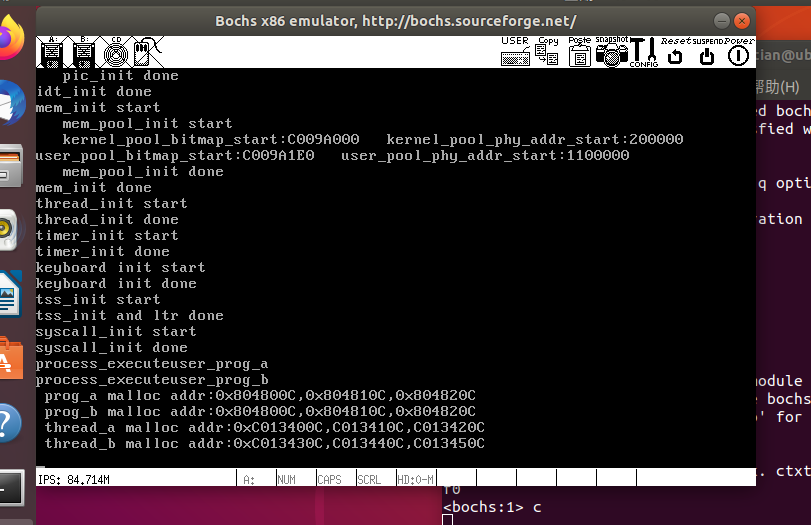
本次main.c中启了4个任务,分别是2个用户进程和2个内核线程。 它们分别都申请了256、255、254字节大小的内存,因此它们对应的内存块规格都应该是256字节。 所有内核线程共享内存空间,因此线程函数k_thread_a和k_thread_b所申请的内存应该会有地址累加的情况。 用户进程拥有独立的内存空间,因此在申请内存时,都会从自己的堆空间从头算起,并不会产生地址累加的情况。 256的十六进制形式是0x100,比较方便查看地址累加的情况,这就是我们选择规格为256字节内存块的原因。
用户进程prog_a三次malloc调用,返回的地址分别是0x804800c、0x804810c、 0x804820c,它们各相差0x100,也就是差256字节,用户进程prog_b与它相同,原因是用户进程独享内 存空间,虚拟地址并不冲突。 线程thread_a调用sys_malloc后返回的地址分别是0xc013400c、0xc013410c、 0xc013420c,地址之间也是相差0x100,即256字节。 下面的线程thread_b同样调用sys_malloc,返回的 地址出现了累加的现象,在k_thread_a地址分配的基础上,从0xc013430c开始,然后依次是0xc013440c 和 Oxc013450c,原因是内核线程共享内存空间,虚拟地址必须唯一。
参考
郑钢著操作系统真象还原
田宇著一个64位操作系统的设计与实现
丁渊著ORANGE’S:一个操作系统的实现