readUTF()源码解析
在学习张宏老师的《自己动手写Java虚拟机时》,发现了一个问题

所以,就以此为契机,查看一下源码;
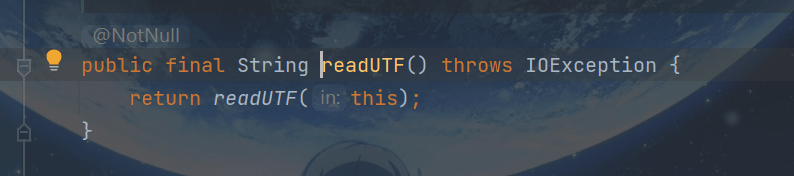
ctrl+B再进去一下:
1.完整源码
源码如下:
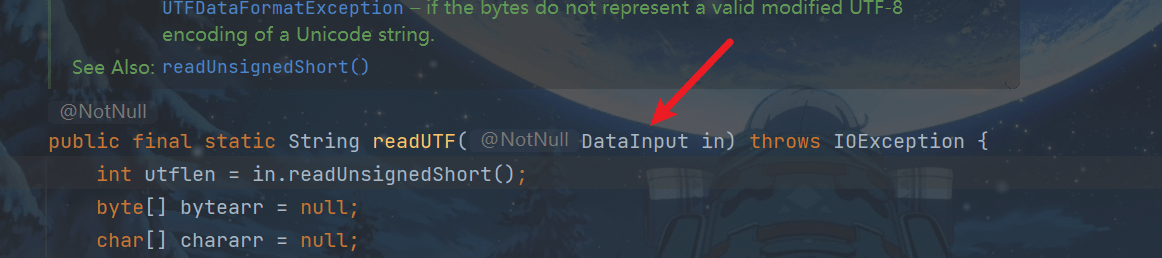
public final static String readUTF(DataInput in) throws IOException {
int utflen = in.readUnsignedShort();
byte[] bytearr = null;
char[] chararr = null;
if (in instanceof DataInputStream) {
DataInputStream dis = (DataInputStream)in;
if (dis.bytearr.length < utflen){
dis.bytearr = new byte[utflen*2];
dis.chararr = new char[utflen*2];
}
chararr = dis.chararr;
bytearr = dis.bytearr;
} else {
bytearr = new byte[utflen];
chararr = new char[utflen];
}
int c, char2, char3;
int count = 0;
int chararr_count=0;
in.readFully(bytearr, 0, utflen);
while (count < utflen) {
c = (int) bytearr[count] & 0xff;
if (c > 127) break;
count++;
chararr[chararr_count++]=(char)c;
}
while (count < utflen) {
c = (int) bytearr[count] & 0xff;
switch (c >> 4) {
case 0: case 1: case 2: case 3: case 4: case 5: case 6: case 7:
/* 0xxxxxxx*/
count++;
chararr[chararr_count++]=(char)c;
break;
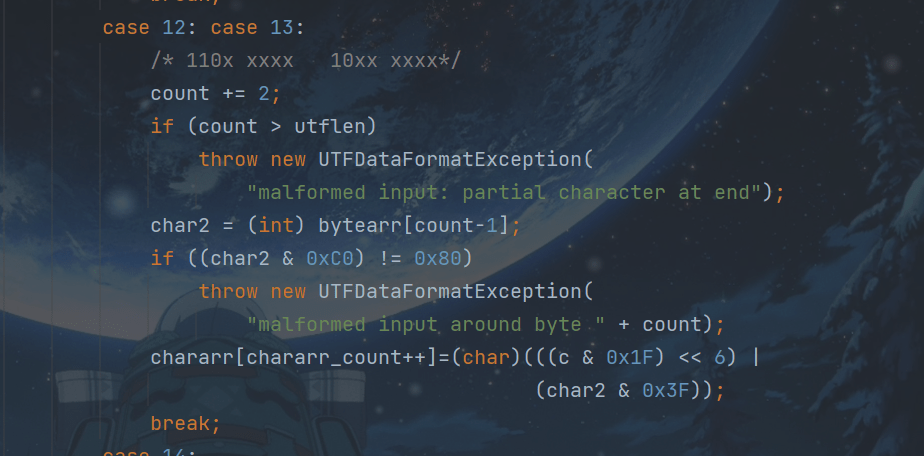
case 12: case 13:
/* 110x xxxx 10xx xxxx*/
count += 2;
if (count > utflen)
throw new UTFDataFormatException(
"malformed input: partial character at end");
char2 = (int) bytearr[count-1];
if ((char2 & 0xC0) != 0x80)
throw new UTFDataFormatException(
"malformed input around byte " + count);
chararr[chararr_count++]=(char)(((c & 0x1F) << 6) |
(char2 & 0x3F));
break;
case 14:
/* 1110 xxxx 10xx xxxx 10xx xxxx */
count += 3;
if (count > utflen)
throw new UTFDataFormatException(
"malformed input: partial character at end");
char2 = (int) bytearr[count-2];
char3 = (int) bytearr[count-1];
if (((char2 & 0xC0) != 0x80) || ((char3 & 0xC0) != 0x80))
throw new UTFDataFormatException(
"malformed input around byte " + (count-1));
chararr[chararr_count++]=(char)(((c & 0x0F) << 12) |
((char2 & 0x3F) << 6) |
((char3 & 0x3F) << 0));
break;
default:
/* 10xx xxxx, 1111 xxxx */
throw new UTFDataFormatException(
"malformed input around byte " + count);
}
}
// The number of chars produced may be less than utflen
return new String(chararr, 0, chararr_count);
}
}
2.源码解释
readUTF的一般作用是它将Unicode字符串读取为modified UTF-8并作为字符串返回。
解释:
readUTF的作用是它读取以modified UTF-8格式编码的Unicode字符串的表示,然后作为字符串返回。
1.第一步
首先传入一个DataInput
DataInput接口提供了从二进制流中读取字节并从中重构任何Java基本类型中的数据的功能。
2.第二步
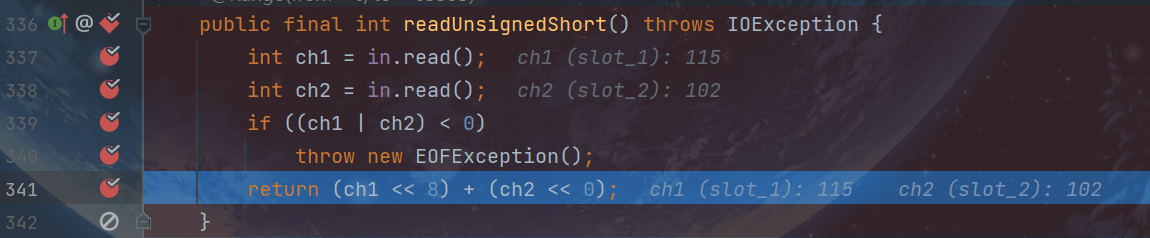
调用DataInput接口的readUnsignedShort()方法
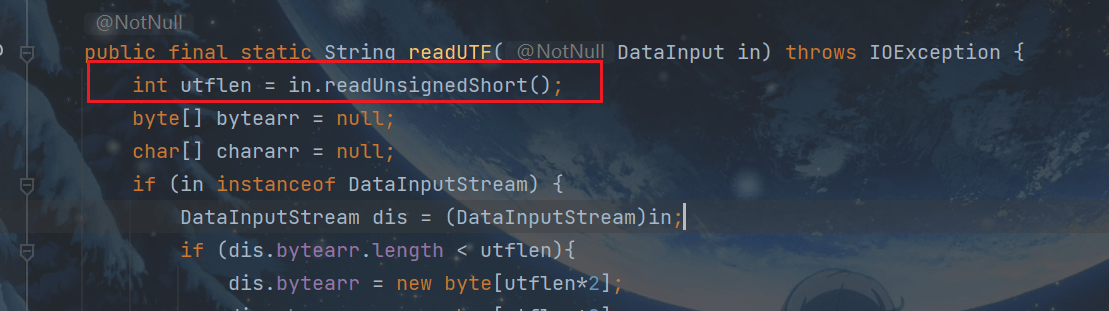
其实,就是调用实现了DataInput接口的DataInputStream的readUnsignedShort()方法

这个方法的具体实现为
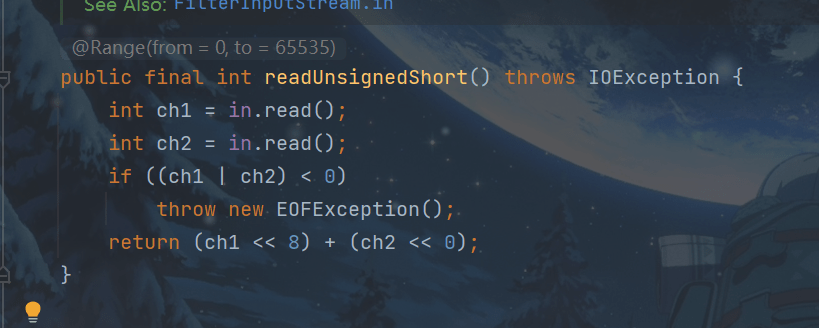
read方法:从这个输入流中读取下一个字节的数据。返回值byte为int型,取值范围为0到255。如果由于到达流的末尾而没有可用的字节,则返回值-1。此方法阻塞,直到输入数据可用、检测到流的末尾或抛出异常为止。这个方法只是执行in.read()并返回结果。
用read方法读取一个字节返回这个字节的Unicode编码,再用read方法读取下一个字节返回这个字节的Unicode编码,当读取一个字节的数据,到达流的末尾而没有可用的字节,则返回值-1。此时ch1和ch2才或运算小于零,而抛出EOFException。
否则返回ch1左移8位和ch2左移0位之和,
比如,第一个字符为s,第二个字符为f
s的Unicode编码为115,二进制是01110011

左移8位为0111001100000000

f的Unicode编码为115,二进制是01100110,左移0位不变

s左移8位和f左移0位之和,就是0111001101100110,也就是29542

如图:
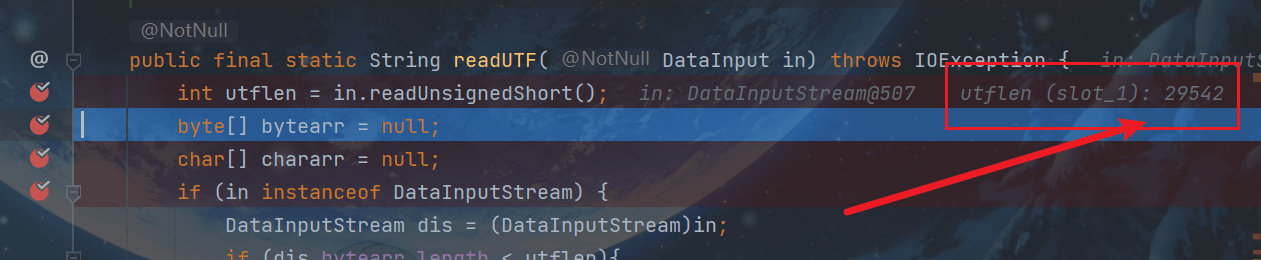
也就是让其变为两个字节存储的二进制字符。读取两个字节,并按照readUnsignedShort方法的方式构造一个无符号16位整数。
3.第三步
将这些字节转换为字符:
分四种情况:
3.1.0xxxxxxx
- 如果组的第一个字节匹配位模式0xxxxxxx(其中x表示“可能是0或1”),则该组仅由该字节组成。字节被零扩展以形成一个字符。
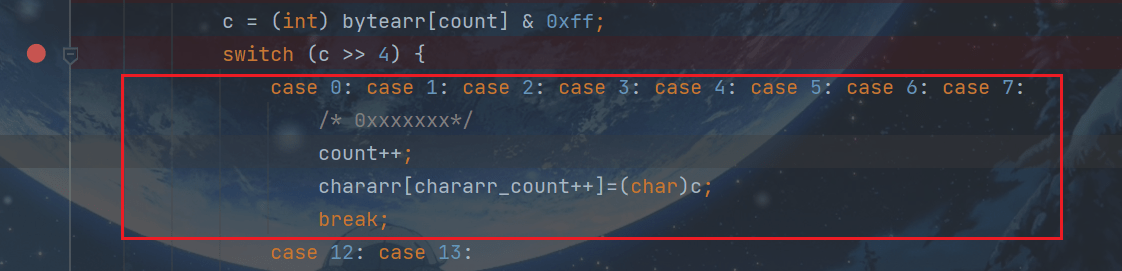
直接break,最后返回new String(chararr, 0, chararr_count),方法结束。
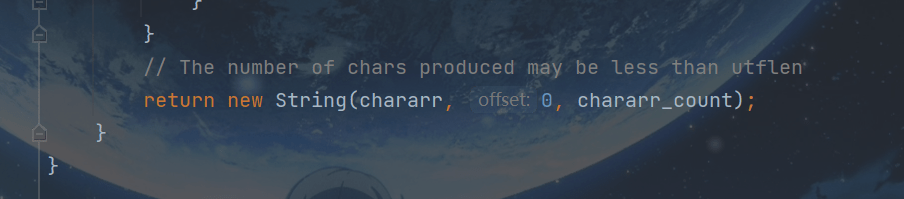
3.2.110xxxxx
- 如果组的第一个字节匹配位模式110xxxxx,则该组由字节a和第二个字节b组成。如果没有字节b(因为字节a是要读取的最后一个字节),或者如果字节b不匹配位模式10xxxxxx,则抛出UTFDataFormatException。
否则,组将转换为字符(对于a,只要110后面5个位就行,二进制11111转换十进制是31,也就是与0x1F就行。b同理,与0x3F就行):
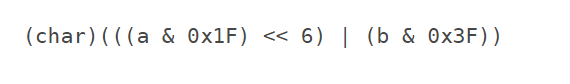
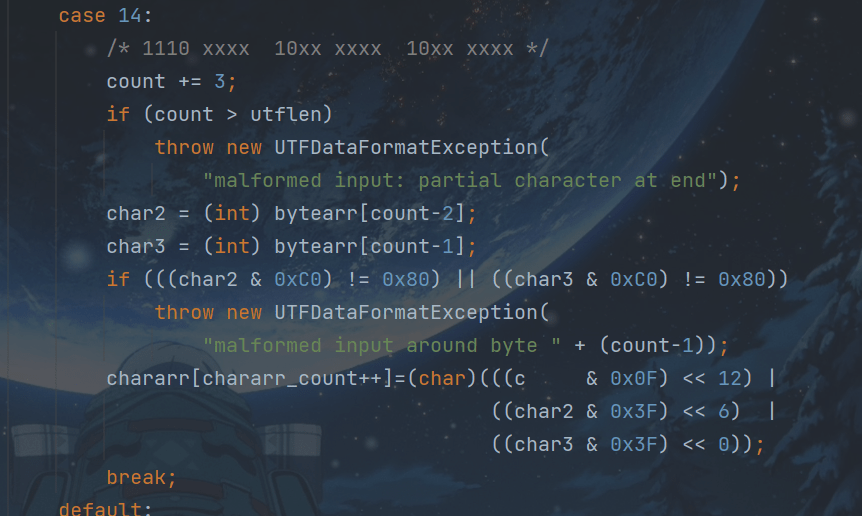
3.3.1110xxxx
- 如果组的第一个字节匹配位模式1110xxxx,则该组由字节a和另外两个字节b和c组成。如果没有字节c(因为字节a是要读取的最后两个字节之一),或者字节b或字节c不匹配位模式10xxxxxx,则抛出UTFDataFormatException。否则,组将转换为字符:
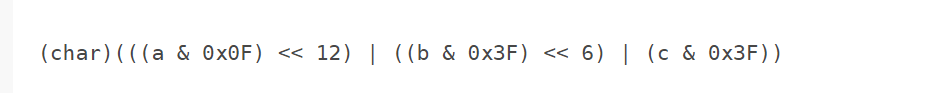
3.4.1111xxxx或模式10xxxxxx匹配
- 如果组的第一个字节与模式1111xxxx或模式10xxxxxx匹配,则抛出一个UTFDataFormatException。
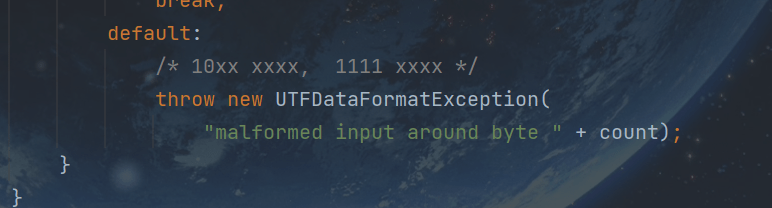
而如果在整个过程中任何时候遇到文件结束,则抛出EOFException。
在通过这个过程将每个组转换为字符之后,将按照从输入流读取相应组的相同顺序收集字符,以形成一个字符串,并返回该字符串。
DataOutput接口的writeUTF方法可用于写入适合该方法读取的数据。
下次再讲吧
参考: