1.基本概念
因为当多条命令执行时,需要等待是上一条命令执行成功再执行,增加了Request/Response protocols and round-trip time (RTT,请求/响应协议和往返时间) ,同时需要redis多次调用read()和write()系统方法,频繁切换用户态和内核态,影响性能。
客户端和服务器通过网络连接,数据包从客户机传输到服务器,再从服务器返回到客户机以携带应答都需要时间。这个时间被称为RTT(往返时间)。
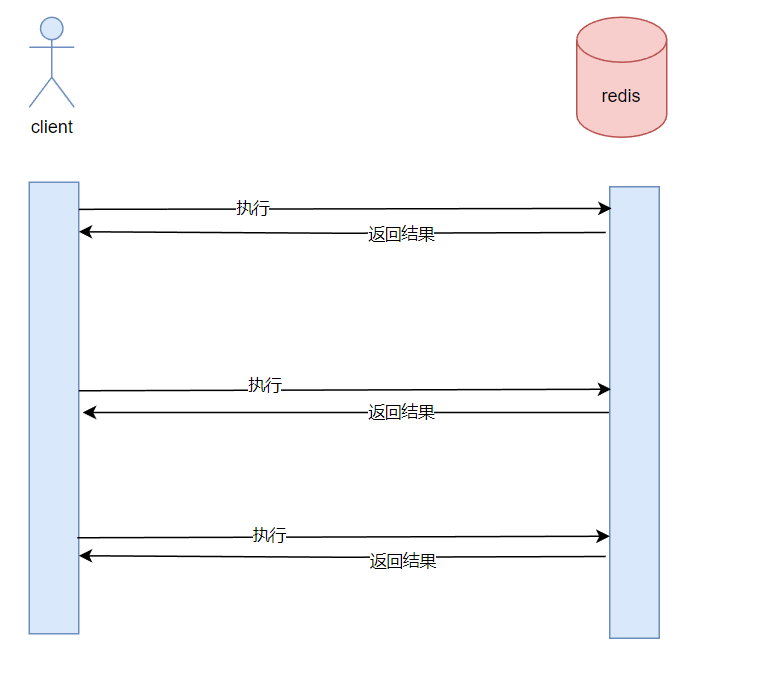
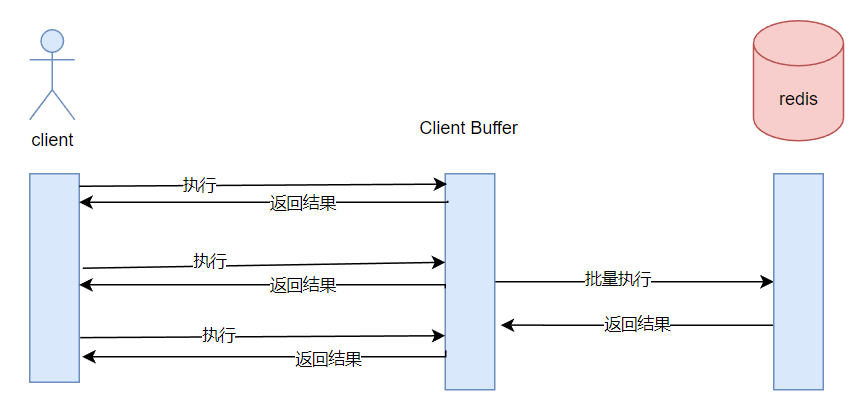
就带来了管道(pipeline)的概念。批处理命令。
2.使用方法
新建一个文件pipeline.txt,
vim pipeline.txt
加入需要批处理的命令,比如
set k1 v1 set k2 v2 set k3 v3 hset people name make
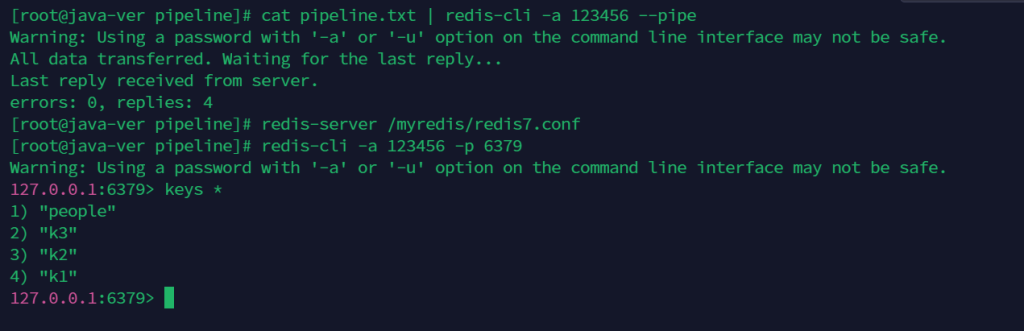
使用管道批量执行,在linux执行,无需进入redis客户端。
cat pipeline.txt | redis-cli -a 123456 --pipe

正常
注意:
pipeline不是原子性的
重要提示:
当客户端使用pipeline发送命令时,服务器将被迫使用内存将响应排队。因此,需要使用pipeline发送大量命令,最好将它们分批发送,每个批次包含一个合理的数量,例如10k个命令,读取回复,然后再次发送另一个10k个命令,以此类推。速度几乎是相同的,但是使用的额外内存最多是为这些10k命令的响应排队所需的内存。