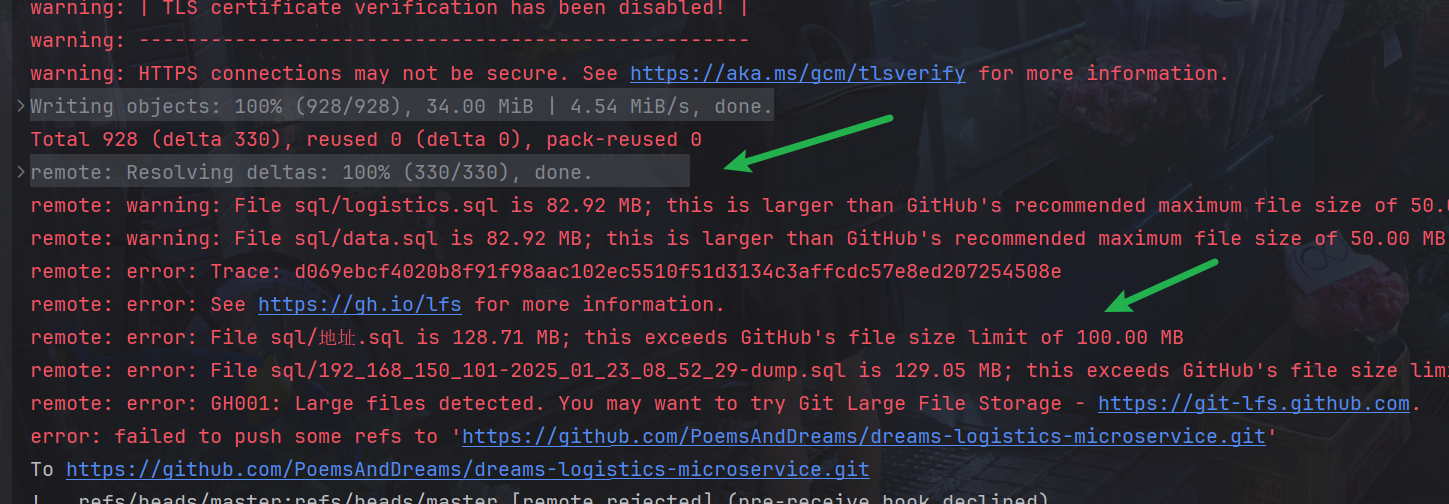
笔记参考尚硅谷宋红康:
JVM全套教程:https://www.bilibili.com/video/BV1PJ411n7xZ
1.概述
- Java字节码对于虚拟机,就好像汇编语言对于计算机,属于基本执行指令。
- Java虚拟机的指令由一个字节长度的、代表着某种特定操作含义的数字(称为操作码, Opcode)以及跟随其后的零至多个代表此操作所需参数(称为操作数, Operands)而构成。由于Java虚拟机采用面向操作数栈而不是寄存器的结构,所以大多数的指令都不包含操作数,只有一个操作码。
- 由于限制了 Java 虚拟机操作码的长度为一个字节(即 0~255),这意味着指令集的操作码总数不可能超过256 条。
- 官方文档:Chapter 6. The Java Virtual Machine Instruction Set (oracle.com)
- 熟悉虚拟机的指令对于动态字节码生成、反编译Class文件、Class文件修补都有着非常重要的价值。因此,阅读字节码作为了解 Java 虚拟机的基础技能,需要熟练掌握常见指令。
1.1执行模型
如果不考虑异常处理的话.那么Java虚拟机的解释器可以使用下面这个伪代码当做最基本的执行模型来理解
do{
自动计算PC寄存器的值加1;
根据PC寄存器的指示位置,从字节码流中取出操作码;
if(字节码存在操作数) 从字节码流中取出操作数;
执行操作码所定义的操作;
}while(字节码长度>0);
1.2字节码与数据类型
在Java虚拟机的指令集中,大多数的指令都包含了其操作所对应的数据类型信息。例如,iload指令用于从局部变量表中加载int型的数据到操作数栈中,而fload指令加载的则是float类型的数据。
对于大部分与数据类型相关的字节码指令,它们的操作码助记符中都有特殊的字符来表明专门为哪种数据类型服务
- i代表对int类型的数据操作,
- l代表long
- s代表short
- b代表byteI
- c代表char
- f代表float
- d代表double
也有一些指令的助记符中没有明确地指明操作类型的字母,如arraylength指令,它没有代表数据类型的特殊字符,但操作数永远只能是一个数组类型的对象。
还有另外一些指令,如无条件跳转指令goto则是与数据类型无关的。
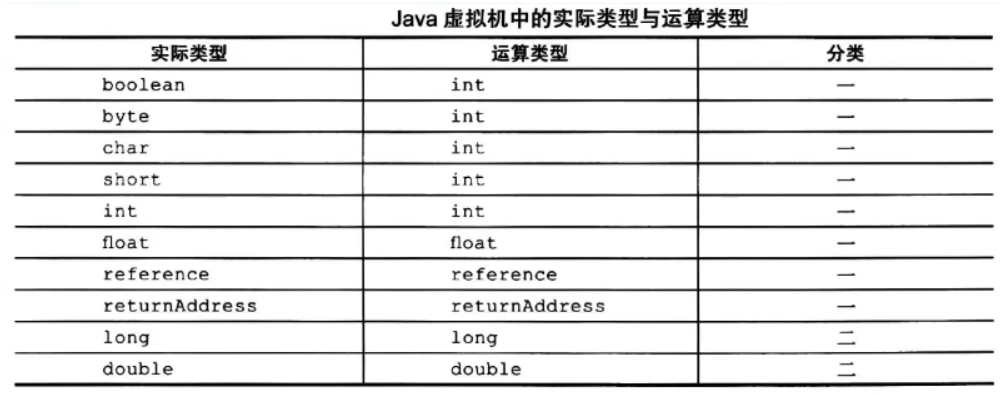
大部分的指令都没有支持整数类型byte,char和short,甚至没有任何指令支持boolean类型,编译器会在编译运行期将byte和short类型的数据带符号扩展(Sign-Extend)为相应的int类型数据,将boolean和char类型扩展(Zero-Extend)为相应的int类型数据。与之类似,在处理boolean、byte、short和char类型的数组时,也会转换为使用对应的int类型的字节码指令来处理。因此,大多数对于boolean、byte、short和char类型数据的操作,实际上都是使用相应的int类型作为运算类型。
1.3指令分类
由于完全介绍和学习这些指令需要花费大量时间。为了让大家能够更快地熟悉和了解这些基本指令,这里将JVM中的字节码指令集按用途大致分成 9 类。
- 加载与存储指令
- 算术指令
- 类型转换指令
- 对象的创建与访问指令
- 方法调用与返回指令
- 操作数栈管理指令
- 比较控制指令
- 异常处理指令
- 同步控制指令
在做值相关操作时:
- 一个指令,可以从局部变量表、常量池、堆中对象、方法调用、系统调用中等取得数据,这些数据(可能是值可能是对象的引用)被压入操作数栈。
- 一个指令,也可以从操作数栈中取出一到多个值(pop多次),完成赋值、加减乘除、方法传参、系统调用等等操作。
2.加载与存储指令
加载和存储指令
1、作用
加载和存储指令用于将数据从栈帧的局部变量表和操作数栈之间来回传递。
2、常用指令
- 1、【局部变量压栈指令】将一个局部变量加载到操作数栈: xload、xload_<n> (其中x为i、l、f、d、a,n 为 0到 3)
- 2、【常量入栈指令】将一个常量加载到操作数栈:bipush、sipush、ldc、ldc_w、ldc2_w、aconst_null、 iconst_m1、 iconst_<i>、lconst_<l>、fconst_<f>、dconst_<d>
- 3、 【出栈装入局部变量表指令】将一个数值从操作数栈存储到局部变量表: xstore、 xstore_<n> (其中x为i、l、f、d、a,n 为 0 到 3);xastore(其中x为i、l、f、d、a、b、c、s)
- 4、扩充局部变量表的访问索引的指令: wide.
注意:
- 上面所列举的指令助记符中,有一部分是以尖括号结尾的(例如iload_<n>)。这些指令助记符实际上代表了一组指令(例如iload_<n>代表了iload_0、 iload_1、 iload_2和iload_3这几个指令) 。这几组指令都是某个带有一个操作数的通用指令(例如iload)的特殊形式,对于这若干组特殊指令来说,它们表面上没有操作数,不需要进行取操作数的动作,但操作数都隐含在指令中。比如:iload_0:将局部变量表中索引为0位置上的数据压入操作数栈中。n 为 0到 3,所以iload 4:将局部变量表中索引为4位置上的数据压入操作数栈中。
- 除此之外,它们的语义与原生的通用指令完全一致(例如iload_0的语义与操作数为0时的iload指令语义完全一致)。在尖括号之间的字母指定了指令隐含操作数的数据类型,<n>代表非负的整数, <i>代表是int类型数据,<l>代表是long类型, <f>代表float类型, <d>代表double类型。
- 对于boolean、byte、short和char类型数据的操作,使用相应的int类型来表示。
2.1再谈操作数栈与局部变量表
1、操作数栈(Operand Stacks)
我们知道, Java字节码是Java虚拟机所使用的指令集。因此,它与Java虚拟机基于栈的计算模型是密不可分的.在解释执行过程中,每当为Java方法分配栈桢时, Java虚拟机往往需要开辟一块额外的空间作为操作数栈,来存放计算的操作数以及返回结果。具体来说便是:执行每一条指令之前, Java虚拟机要求该指令的操作数已被压入操作数栈中,在执行指令时, Java虚拟机会将该指令所需的操作数弹出,并且将指令的结果重新压入栈中。
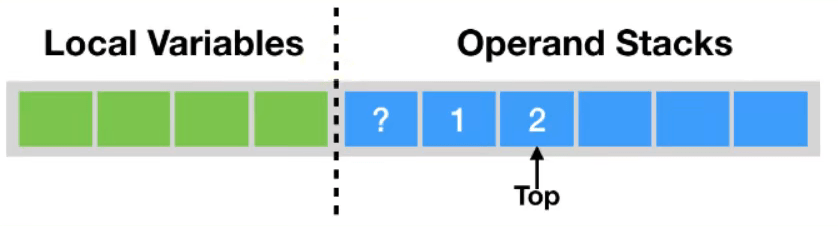
以加法指令iadd为例。假设在执行该指令前,栈顶的两个元素分别为int值1和int值2,那么iadd指令将弹出这两个 int,并将求得的和 int 值 3 压入栈中。

由于iadd指令只消耗栈顶的两个元素,因此,对于离栈顶距离为2的元素,即图中的问号, iadd指令并不关心它是否存在,更加不会对其进行修改。
2、局部变量表(Local Variables)
Java方法栈核的另外一个重要组成部分则是局部变量区,字节码程序可以将计算的结果缓存在局部变量区之中。实际上, Java虚拟机将局部变量区当成一个数组,依次存放this指针(仅非静态方法) ,所传入的参数,以及字节码中的局部变量。和操作数栈一样,long类型以及 double 类型的值将占据两个单元,其余类型仅占据一个单元。
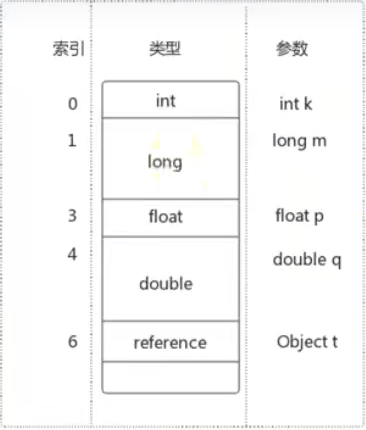
public void foq(long l, float f){
{
int i = 0;
}
{
String s = "Hello, World";
}
}对应的图示:

在栈帧中,与性能调优关系最为密切的部分就是局部变量表。局部变量表中的变量也是重要的垃圾回收根节点,只要被局部变量表中直接或间接引用的对象都不会被回收。
在方法执行时,虚拟机使用局部变量表完成方法的传递。
2.2局部变量压栈指令
局部变量压栈指令将给定的局部变量表中的数据压入操作数栈。
这类指令大体可以分为:
- xload_<n> (x为i、1、f、d、a, n为 0 到 3)
- xload (x为i、l、f、d、 a)
说明:在这里,x的取值表示数据类型。
- 指令xload_n表示将第n个局部变量压入操作数栈,比如iload_1、fload_0、 aload_0等指令。其中aload_n表示将一个对象引用压栈。
- 指令xload通过指定参数的形式,把局部变量压入操作数栈,当使用这个命令时,表示局部变量的数量可能超过了3个,比如指令iload、fload等。
package com.yutian.java;
import java.util.Date;
public class LoadAndStoreTest {
//1.局部变量压栈指令
public void load(int num, Object obj,long count,boolean flag,short[] arr) {
System.out.println(num);
System.out.println(obj);
System.out.println(count);
System.out.println(flag);
System.out.println(arr);
}
//2.常量入栈指令
public void pushConstLdc() {
int i = -1;
int a = 5;
int b = 6;
int c = 127;
int d = 128;
int e = 32767;
int f = 32768;
}
public void constLdc() {
long a1 = 1;
long a2 = 2;
float b1 = 2;
float b2 = 3;
double c1 = 1;
double c2 = 2;
Date d = null;
}
//3.出栈装入局部变量表指令
public void store(int k, double d) {
int m = k + 2;
long l = 12;
String str = "琪亚娜";
float f = 10.0F;
d = 10;
}
public void foo(long l, float f) {
{
int i = 0;
}
{
String s = "Hello, World";
}
}
}
局部变量压栈指令(只关注这类指令,其余之后再谈)
对应代码:
//1.局部变量压栈指令
public void load(int num, Object obj,long count,boolean flag,short[] arr) {
System.out.println(num);
System.out.println(obj);
System.out.println(count);
System.out.println(flag);
System.out.println(arr);
}
对应jclass
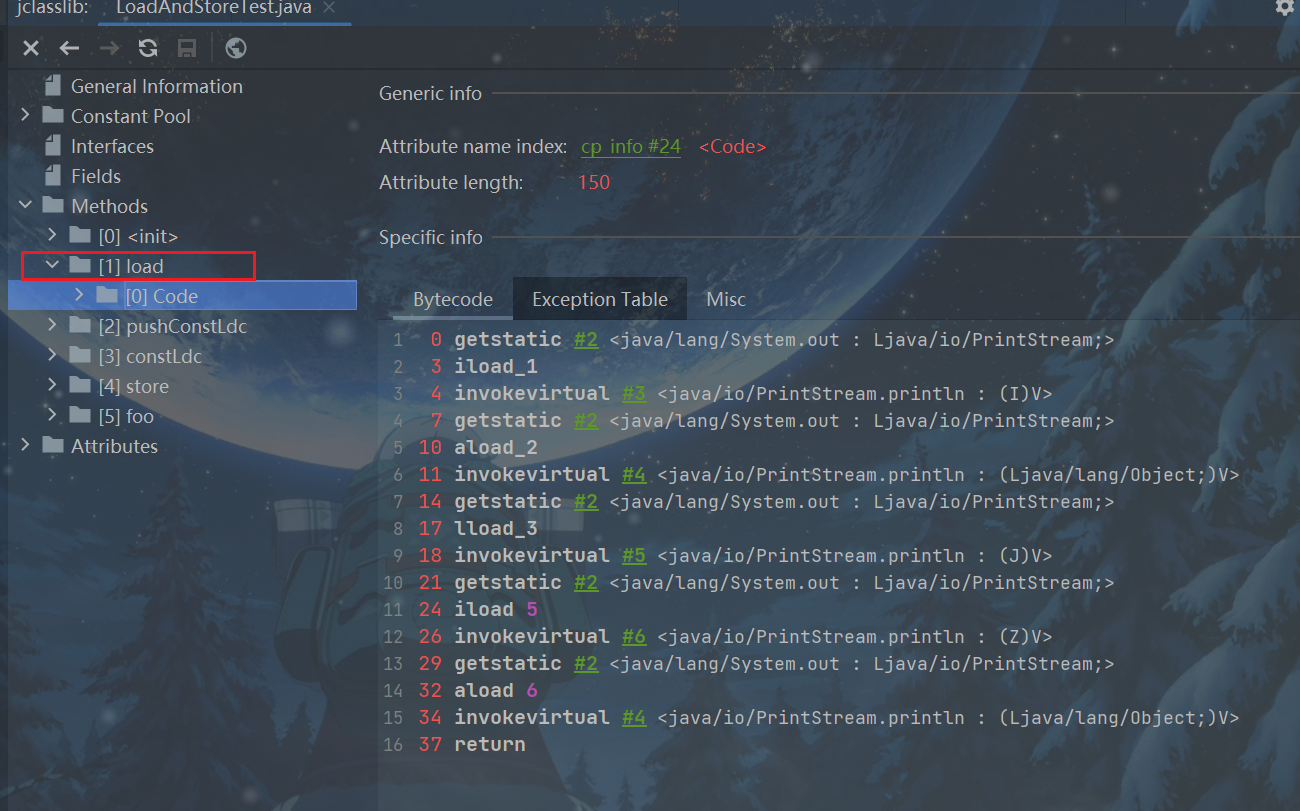
对应局部变量表
注意:(iload 5 )操作的是flag,是boolean类型,使用相应的int类型来表示。

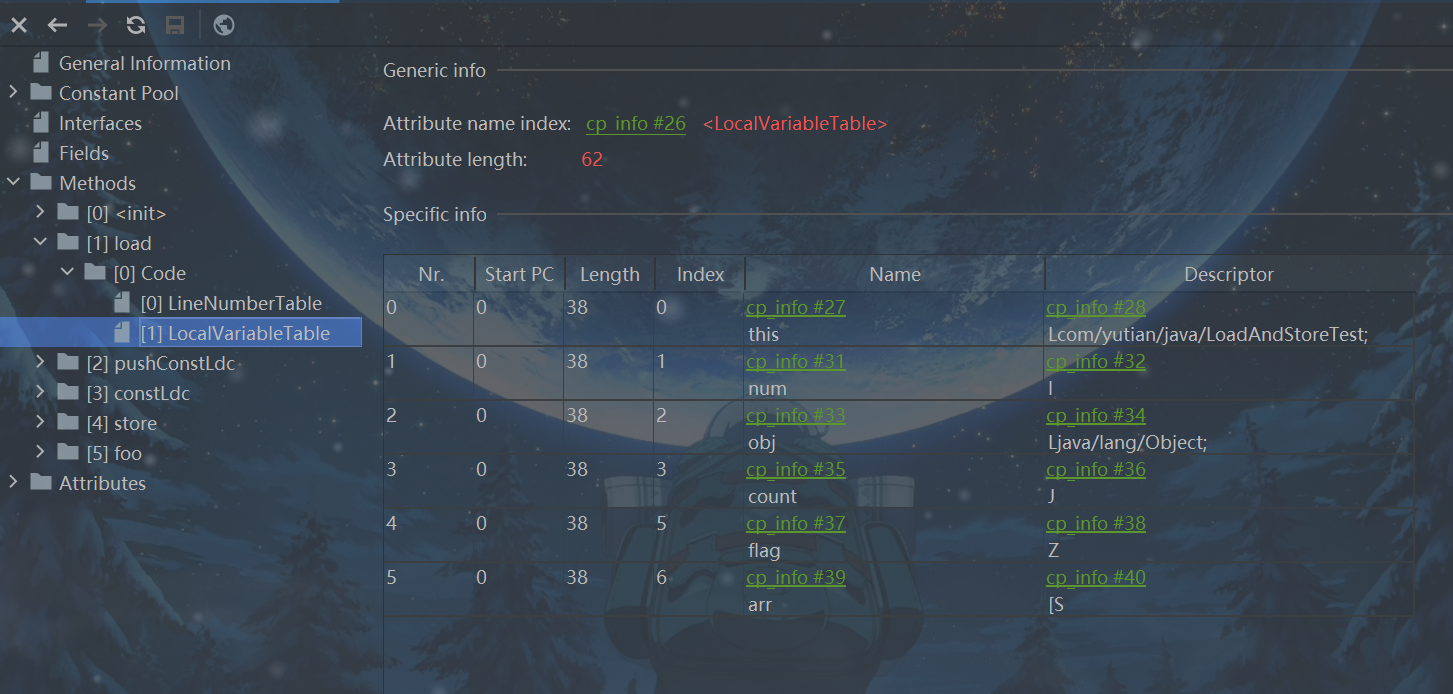
局部变量压栈指令将给定的局部变量表中的数据压入操作数栈。

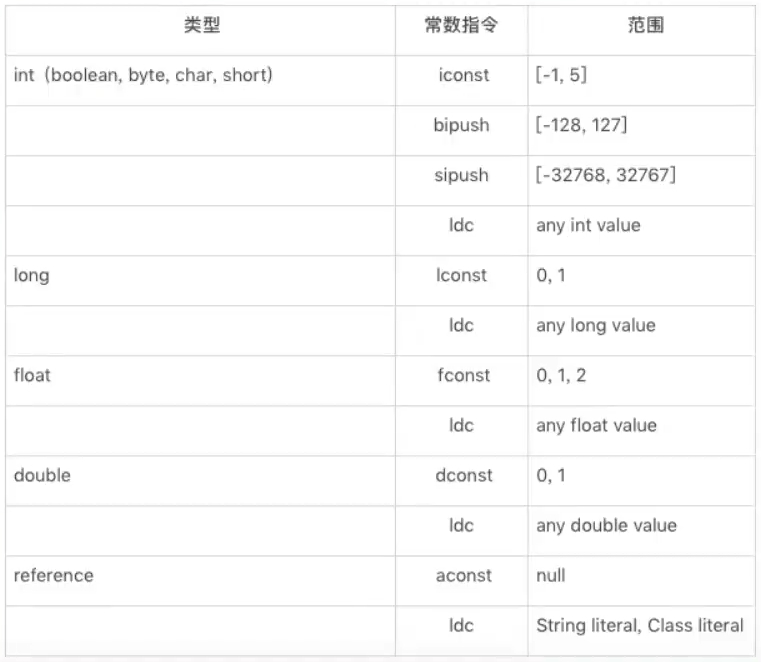
2.3常量入栈指令
常量入栈指令的功能是将常数压入操作数栈,根据数据类型和入栈内容的不同,又可以分为const系列、push系列和ldc指令。
指令const系列:
用于对特定的常量入栈,入栈的常量隐含在指令本身里,指令有: iconst_<i> (i从-1到5)、lconst_<l> (l从0到1)、fconst_<f> (f从0到2)、dconst_<d> (d从0到1)、 aconst_null.
注意:
- iconst_m1将-1压入操作数栈;
- iconst_x (x为0到5) 将x压入栈;
- lconst_0、lconst_1分别将长整数0和1压入栈;
- fconst_0、fconst_1、fconst_2分别将浮点数0、1、2压入栈;
- dconst_0和dconst_1分别将double型0和1压入栈。
- aconst_null将null压入操作数栈;
从指令的命名上不难找出规律,指令助记符的第一个字符总是喜欢表示数据类型,i表示整数,l表示长整数,f表示浮点数,d表示双精度浮点,习惯上用a表示对象引用。如果指令隐含操作的参数,会以下划线形式给出。
指令push系列:
当数超过上述范围,就使用push(整数,其余直接使用ldc)
- 主要包括bipush和sipush,它们的区别在于接收数据类型的不同,bipush接收8位整数作为参数,sipush接收16位整数,它们都将参数压入栈。
指令ldc系列:
- 如果以上指令都不能满足需求,那么可以使用万能的ldc指令,它可以接收一个8位的参数,该 参数指向常量池中的int、float或者String的索引,将指定的内容压入堆栈。
- 类似的还有ldc_w.它接收两个8位参数,能支持的索引范围大于ldc.如果要压入的元素是long或者double类型的,则使用ldc2_w指令,使用方式都是类似的。
//2.常量入栈指令
public void pushConstLdc() {
int i = -1;
int a = 5;
int b = 6;
int c = 127;
int d = 128;
int e = 32767;
int f = 32768;
}
public void constLdc() {
long a1 = 1;
long a2 = 2;
float b1 = 2;
float b2 = 3;
double c1 = 1;
double c2 = 2;
Date d = null;
}
对应字节码:
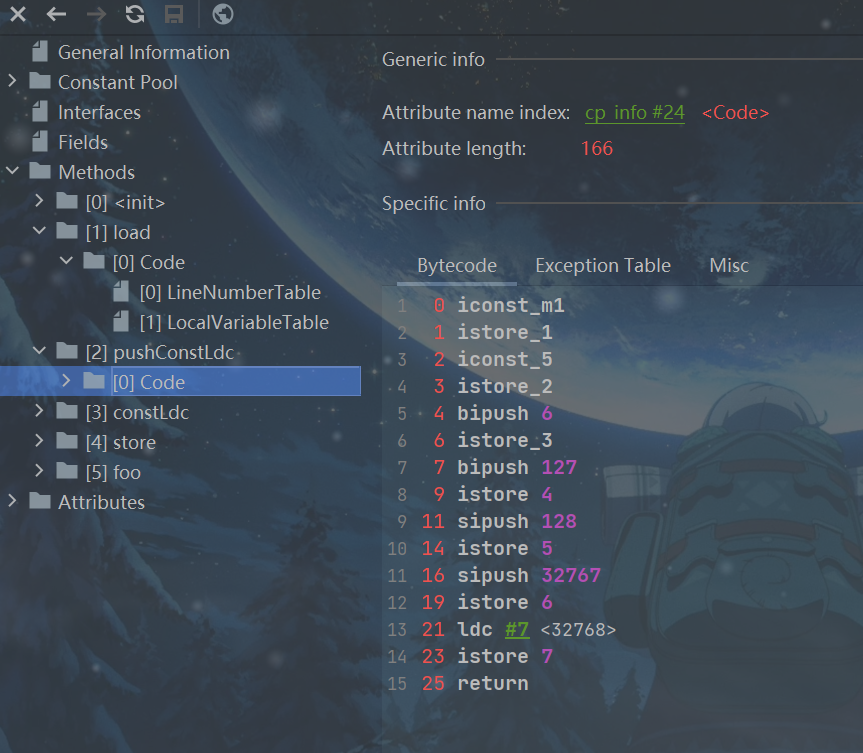
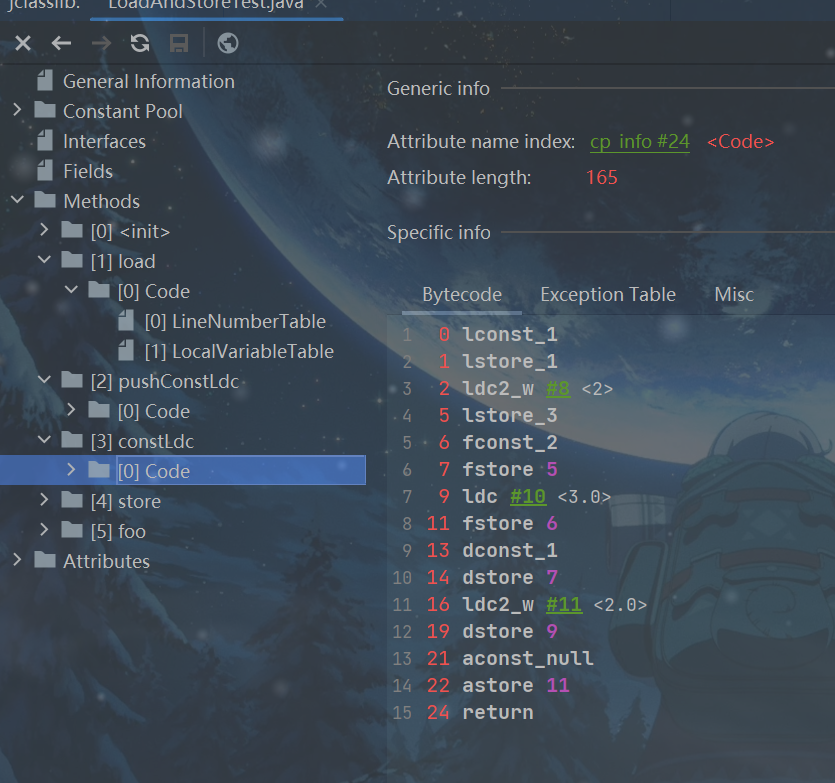
2.3出栈装入局部变量表指令
出栈装入局部变量表指令用于将操作数栈中栈顶元素弹出后,装入局部变量表的指定位置,用于给局部变量赋值。
这类指令主要以xstore的形式存在,比如xstore (x为i、l、f、d、 a)、 xstore_n (x为i、l、f、d、 a, n为0 至 3)。
- 其中,指令istore_n将从操作数栈中弹出一个整数,并把它赋值给局部变量索引n位置。
- 指令xstore由于没有隐含参数信息,故需要提供一个byte类型的参数类指定目标局部变量表的位置。
说明:
- 一般说来,类似像store这样的命令需要带一个参数,用来指明将弹出的元素放在局部变量表的第几个位置。但是,为了尽可能压缩指令大小,使用专门的istore_1指令表示将弹出的元素放置在局部变量表第1个位置。类似的还有istore_0、 istore_2、 istore_3,它们分别表示从操作数栈顶弹出一个元素,存放在局部变量表第0、2、3个位置。
- 由于局部变量表前几个位置总是非常常用,因此这种做法虽然增加了指令数量,但是可以大大压缩生成的字节码的体积,如果局部变量表很大,需要存储的槽位大于3,那么可以使用istore指令,外加一个参数,用来表示需要存放的槽位位置。
//3.出栈装入局部变量表指令
public void store(int k, double d) {
int m = k + 2;
long l = 12;
String str = "琪亚娜";
float f = 10.0F;
d = 10;
}
public void foo(long l, float f) {
{
int i = 0;
}
{
String s = "Hello, World";
}
}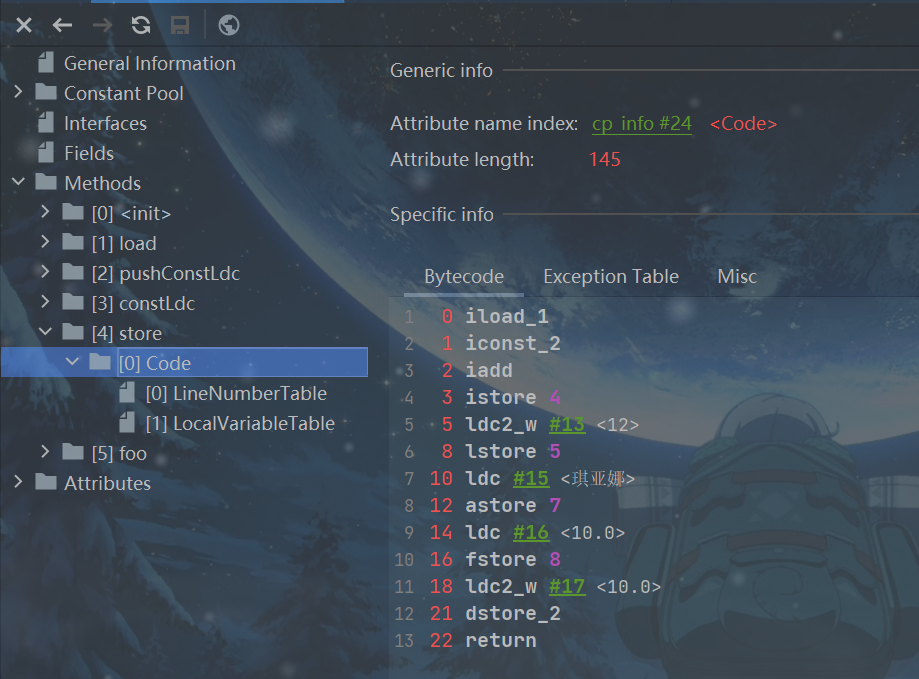

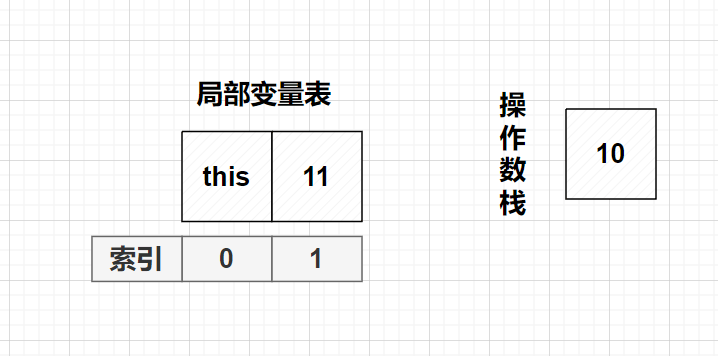
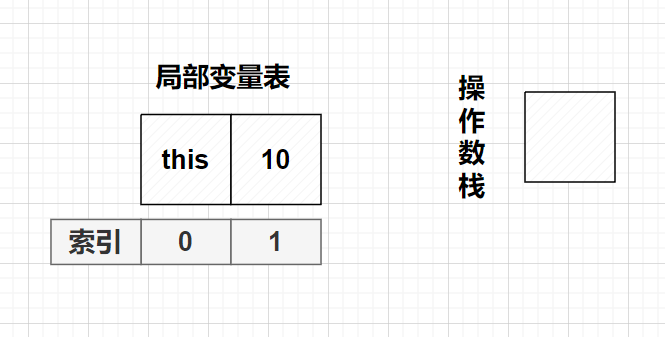
注意:局部变量表里应该存的是具体值,因为方法没被调用,这里用名字代替一下
依次入栈

出栈,add()后,入栈

注意:如果的索引范围大于ldc.且要压入的元素是long或者double类型的,则使用ldc2_w指令
3.算术指令
1.作用:
算术指令用于对两个操作数栈上的值进行某种特定运算,并把结果重新压入操作数栈。
2.分类:
大体上算术指令可以分为两种:对整型数据进行运算的指令与对浮点类型数据进行运算的指令。
3.byte、short、char和boolean类型说明:
在每一大类中,都有针对Java虚拟机具体数据类型的专用算术指令。但没有直接支持byte、 short、char和boolean类型的算术指令,对于这些数据的运算,都使用int类型的指令来处理。此外,在处理boolean、byte、short和char类型的数组时,也会转换为使用对应的int类型的字节码指令来处理。
4.运算时的溢出
数据运算可能会导致溢出,例如两个很大的正整数相加,结果可能是一个负数。其实Java虚拟机规范并无明确规定过整型数据溢出的具体结果,仅规定了在处理整型数据时,只有除法指令以及求余指令中当出现除数为0时会导致虚拟机抛出异常ArithmeticException。
5.运算模式
- 向最接近数舍入模式: JVM要求在进行浮点数计算时,所有的运算结果都必须舍入到适当的精度,非精确结果必须舍入为可被表示的最接近的精确值,如果有两种可表示的形式与该值一样接近,将优先选择最低有效位为零的;
- 向零舍入模式:将浮点数转换为整数时,采用该模式,该模式将在目标数值类型中选择一个最接近但是不大于原值的数字作为最精确的舍入结果;
6.NaN值使用
当一个操作产生溢出时,将会使用有符号的无穷大表示,如果某个操作结果没有明确的数学定义的话,将会使用NaN值来表示。而且所有使用NaN值作为操作数的算术操作,结果都会返回NaN;
@Test
public void method1(){
int i = 10;
int j = i / 0;
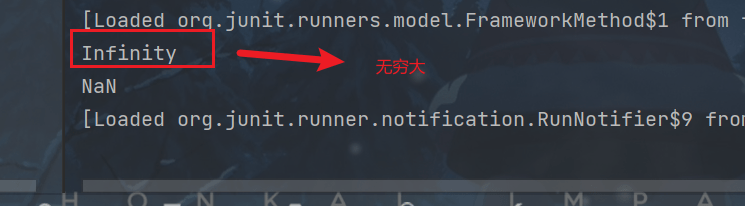
System.out.println(j);//无穷大
double d1 = 0.0;
double d2 = d1 / 0.0;
System.out.println(d2);//NaN: not a number
}输出如下:

@Test
public void method1(){
int i = 10;
double j = i / 0.0;
System.out.println(j);//无穷大
double d1 = 0.0;
double d2 = d1 / 0.0;
System.out.println(d2);//NaN: not a number
}输出如下:
所有算术指令
所有的算术指令包括:
- 加法指令: iadd、ladd、fadd、dadd
- 减法指令: isub、lsub、 fsub、dsub
- 乘法指令:imul、lmul、 fmul、dmul
- 除法指令: idiv、ldiv、fdiv、 ddiv
- 求余指令:irem、lrem、frem、drem //remainder:余数
- 取反指令: ineg、 lneg、 fneg、 dneg //negation:取反
- 自增指令: iinc
- 位运算指令,又可分为:
(1)位移指令: ishl、ishr、iushr、lshl、lshr、lushr
(2)按位或指令: ior、lor
(3)按位与指令: iand、land
(4)按位异或指令: ixor、lxor - 比较指令: dcmpg、dcmpl、fcmpg、fcmpl、lcmp
package com.yutian.java;
import org.junit.Test;
public class ArithmeticTest {
@Test
public void method1(){
int i = 10;
double j = i / 0.0;
System.out.println(j);//无穷大
double d1 = 0.0;
double d2 = d1 / 0.0;
System.out.println(d2);//NaN: not a number
}
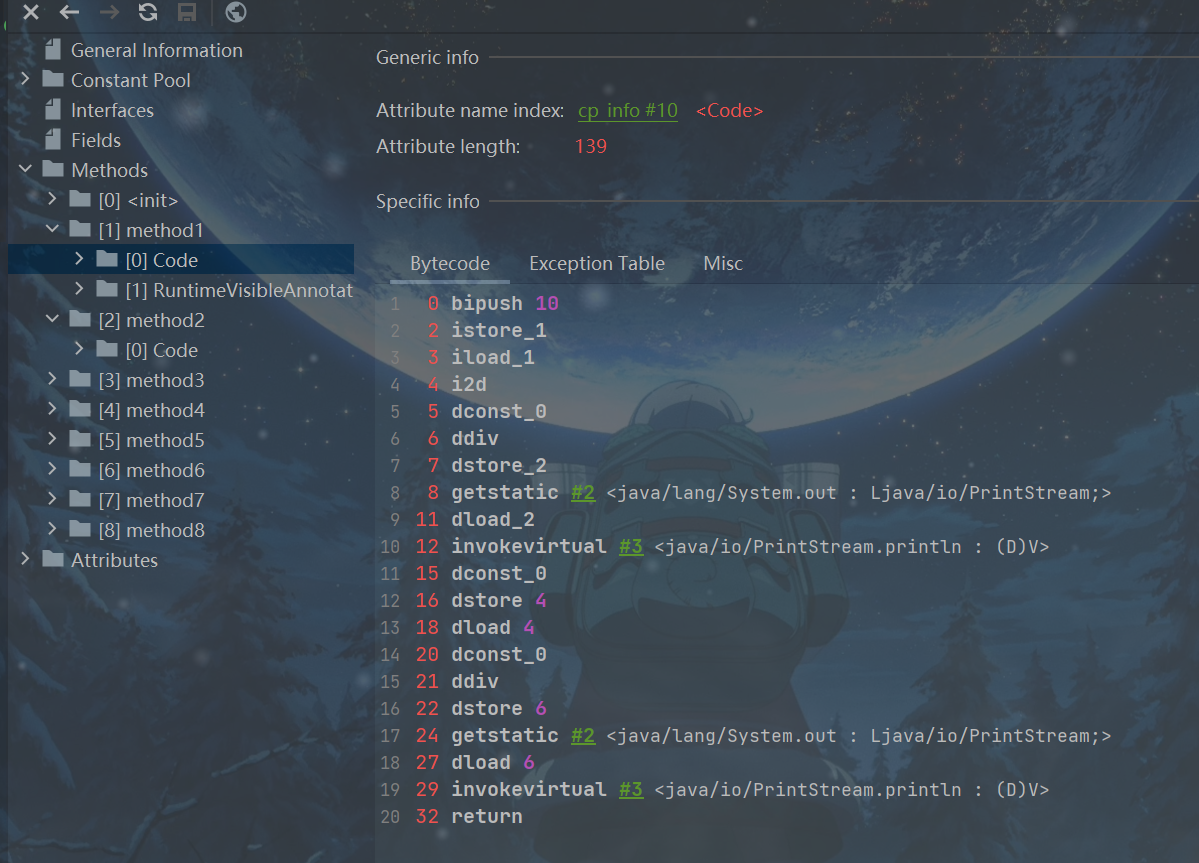
public void method2(){
float i = 10;
float j = -i;
i = -j;
}
public void method3(int j){
int i = 100;
// i = i + 10;
i += 10;
}
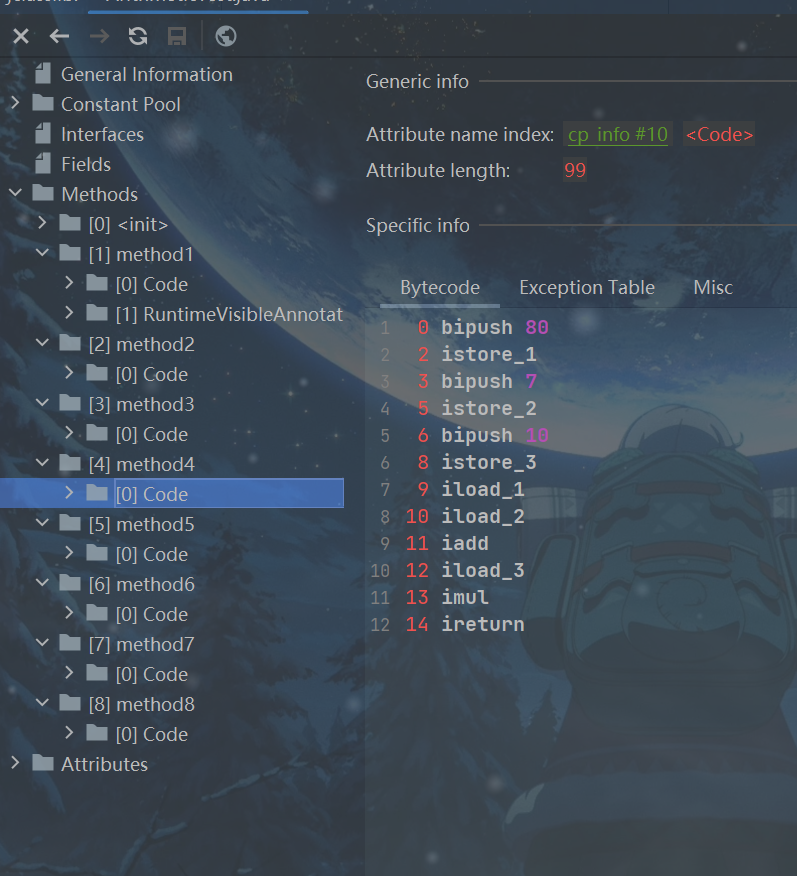
public int method4(){
int a = 80;
int b = 7;
int c = 10;
return (a + b) * c;
}
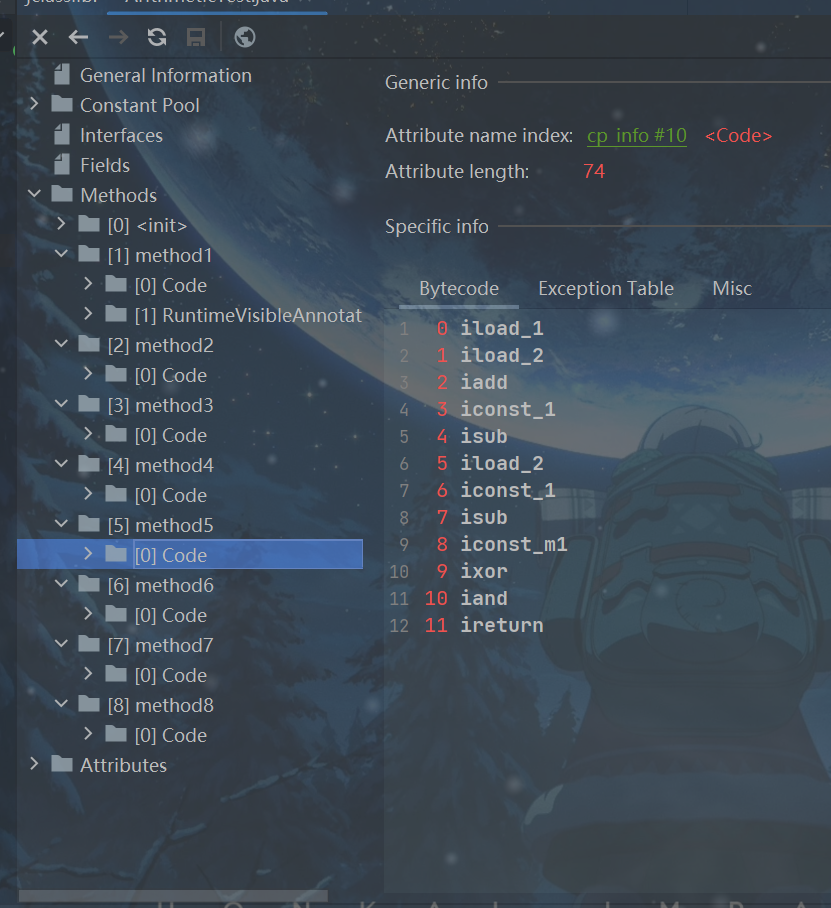
public int method5(int i ,int j){
return ((i + j - 1) & ~(j - 1));
}
//关于(前)++和(后)++
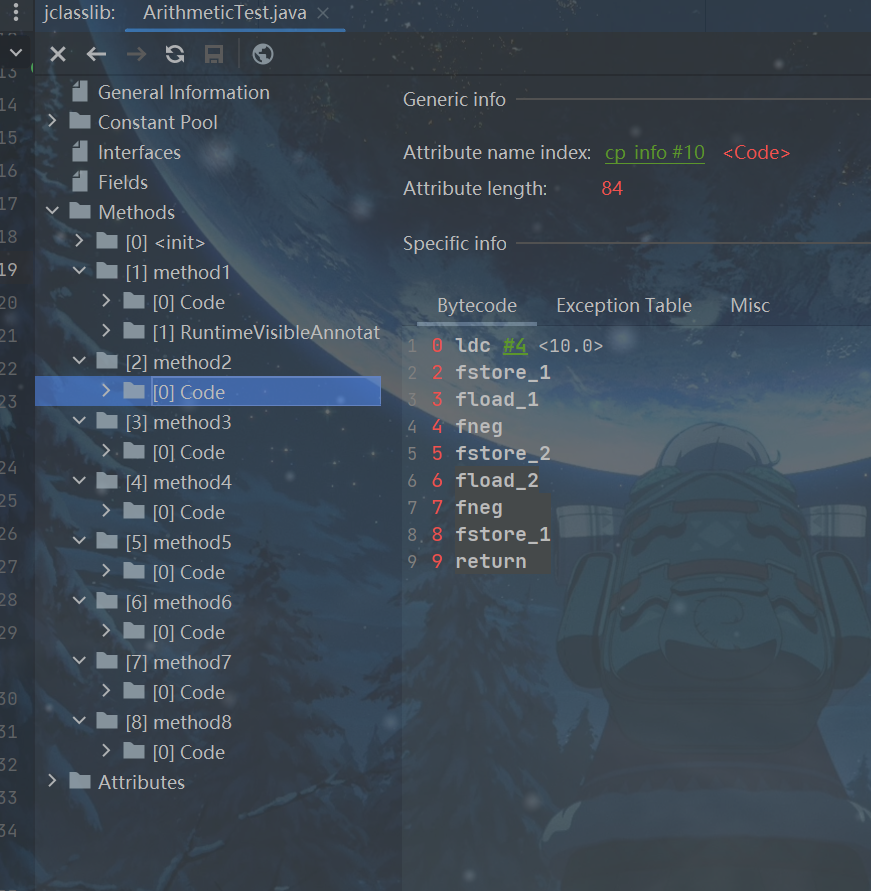
public void method6(){
int i = 10;
i++;
// ++i;
// for(int j = 0;j < 10;j++){}
}
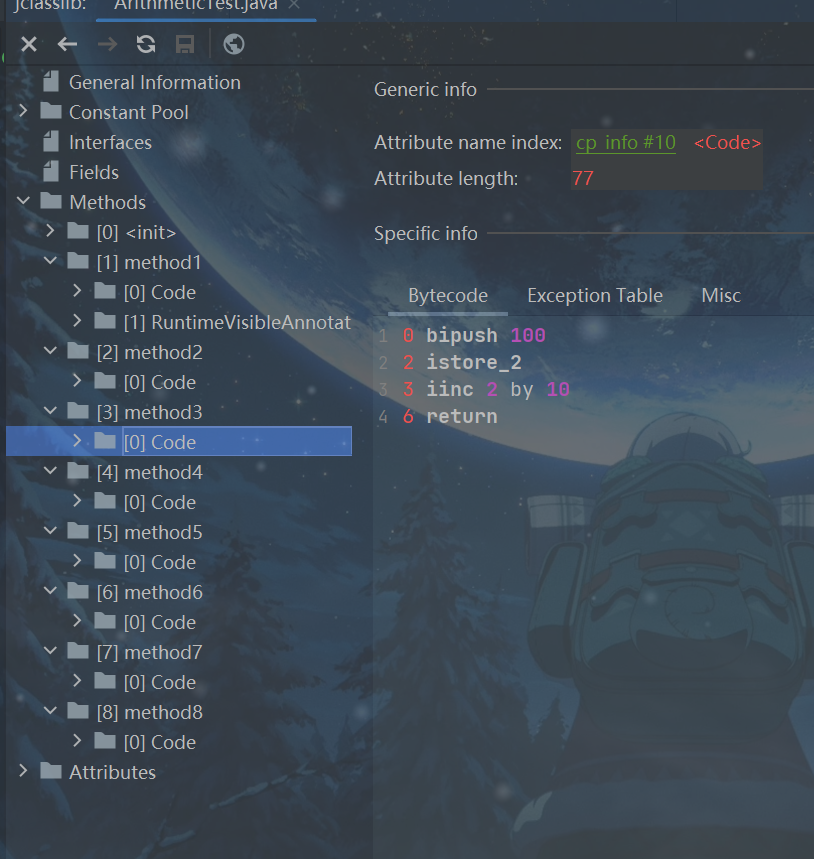
public void method7(){
int i = 10;
int a = i++;
int j = 20;
int b = ++j;
}
//思考
public void method8(){
int i = 10;
i = i++;
System.out.println(i);//10
}
}
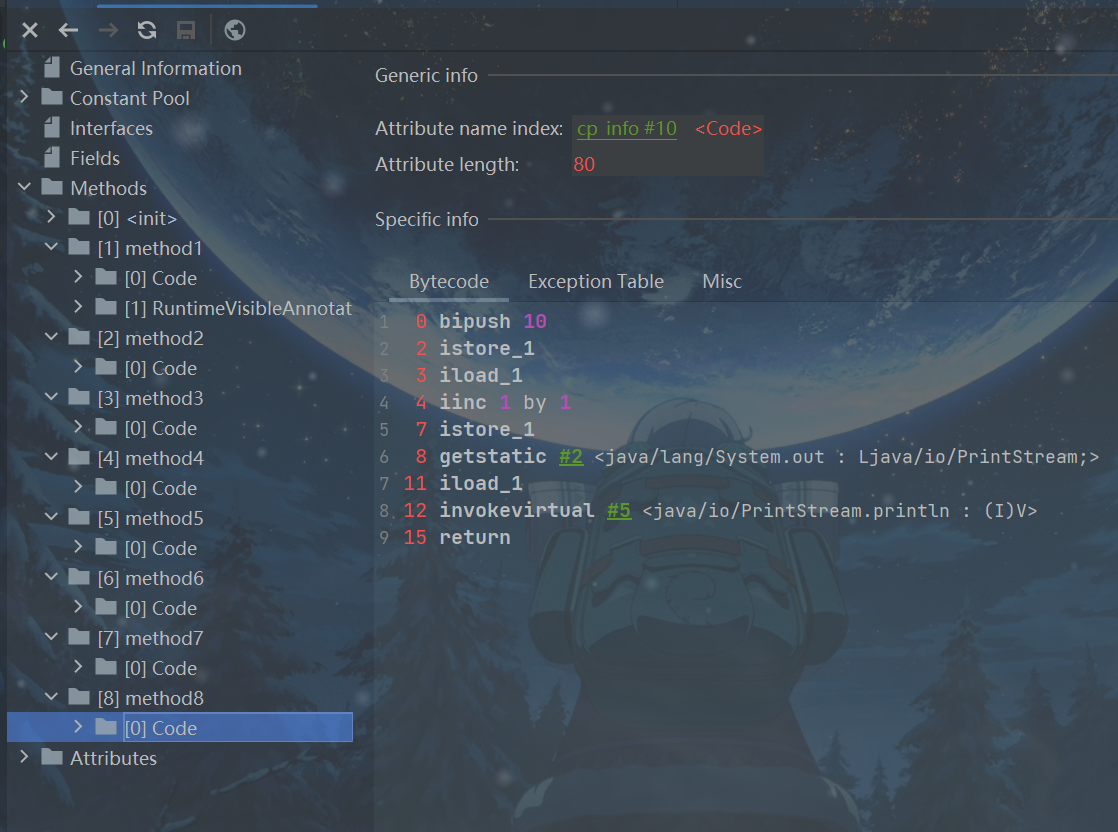
彻底搞定++运算符
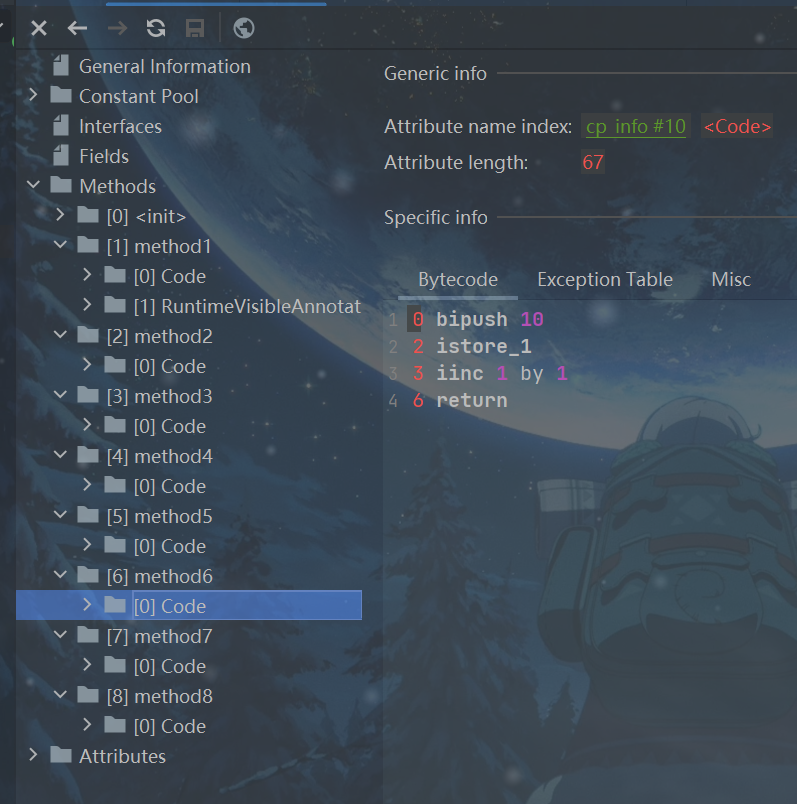
//关于(前)++和(后)++
public void method6(){
int i = 10;
i++;
}
//关于(前)++和(后)++
public void method6(){
int i = 10;
++i;
}在不涉及运算,不赋值的时候字节码指令完全一样。
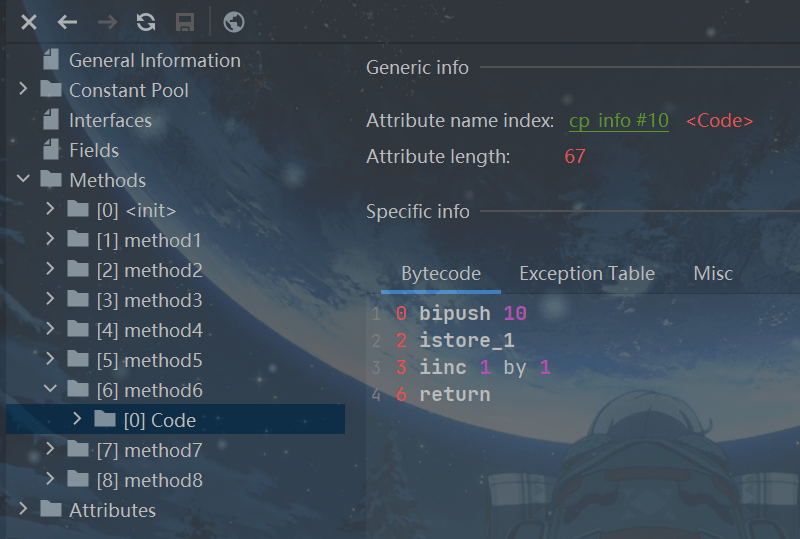
下面通过代码和画图理顺一下字节码指令
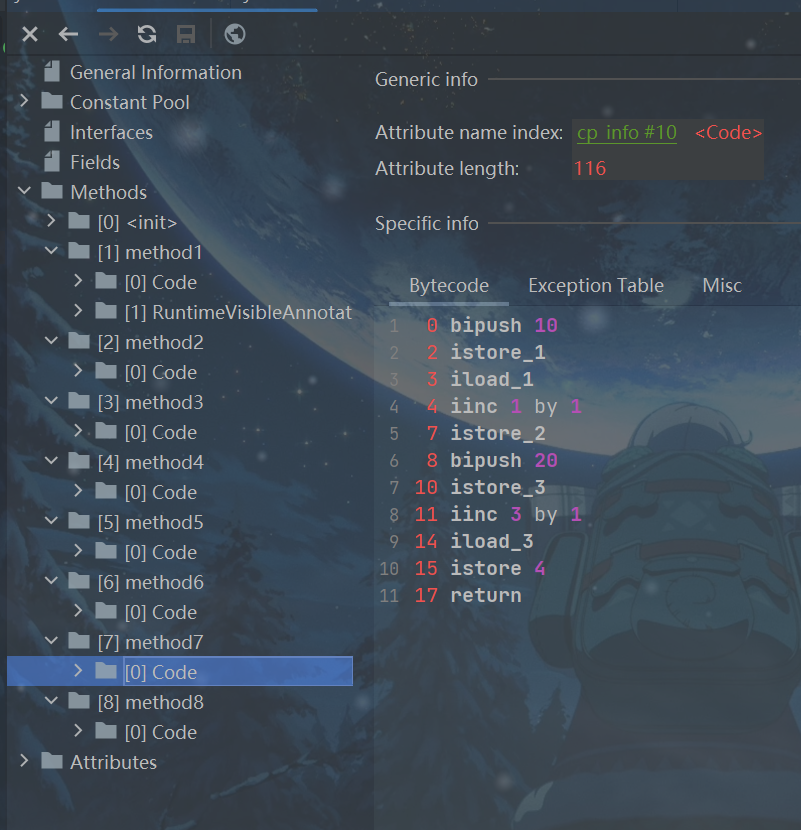
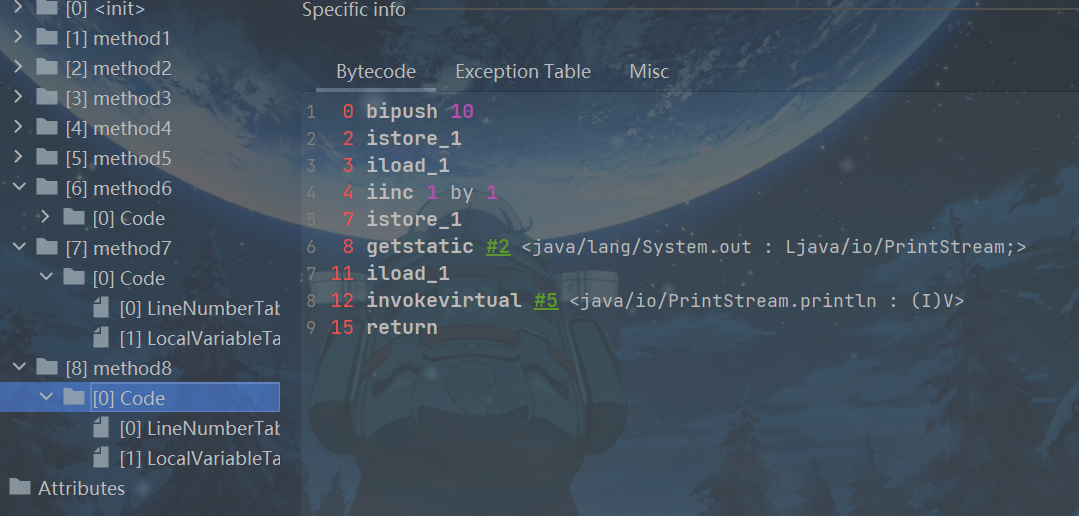
public void method7(){
int i = 10;
int a = i++;
int j = 20;
int b = ++j;
}
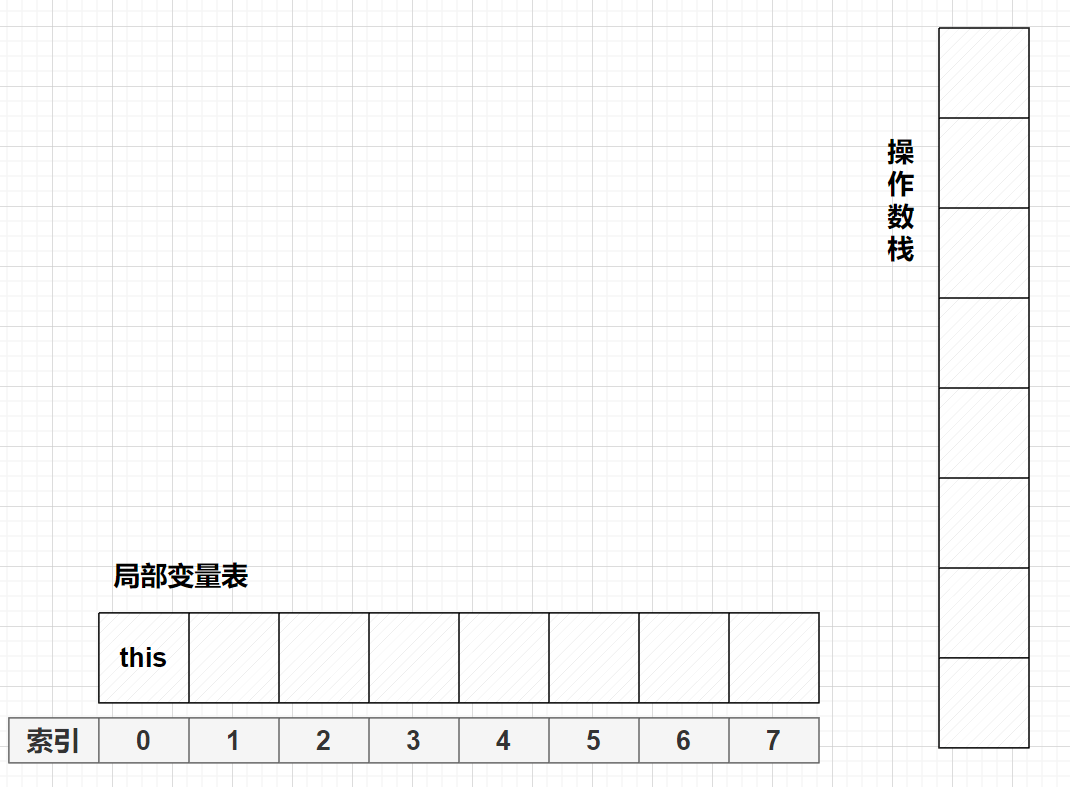
假设从我们的角度看,一开始我们并不知道局部变量表和栈的大小
初始:
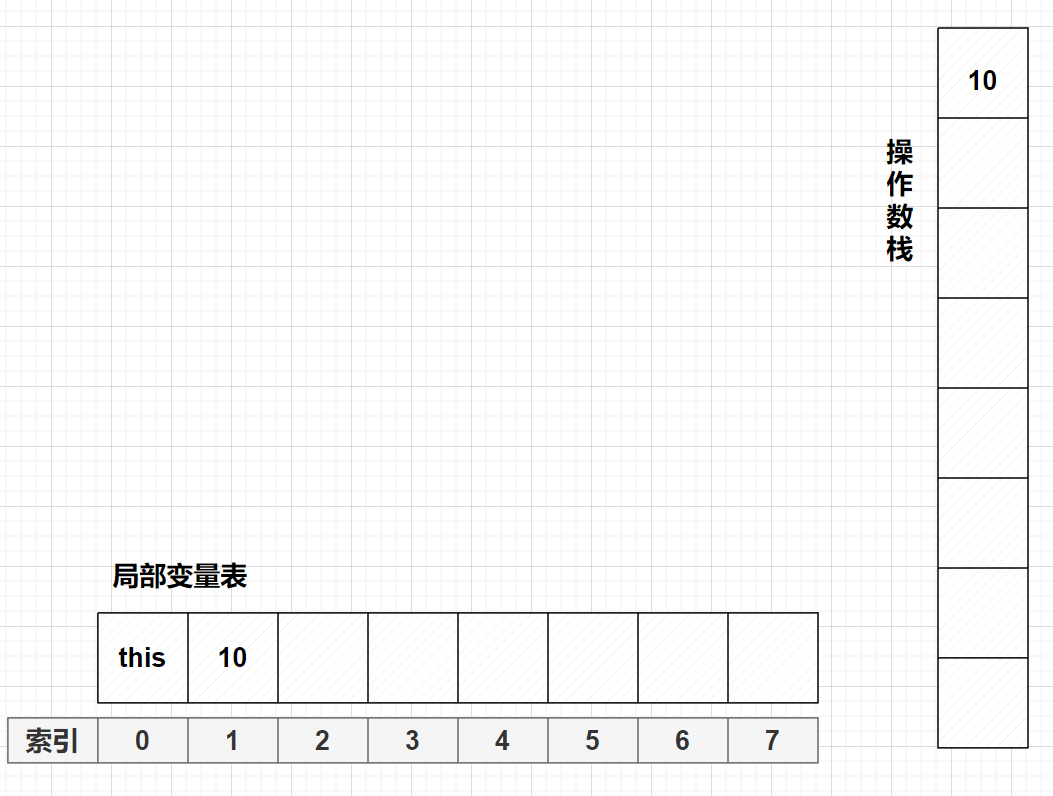
bipush 10(常量入栈指令)后

istore_1(局部变量压栈指令)

iload_1
iinc 1 by 1
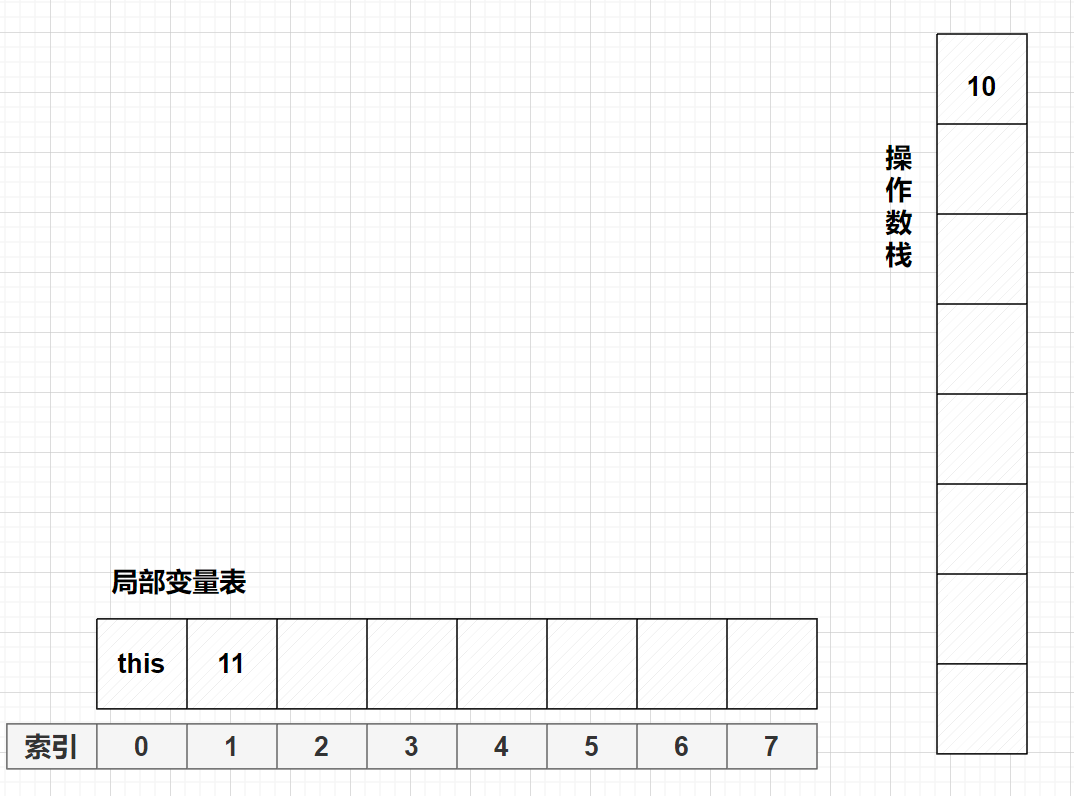
istore_2,此时的a值为10,放在索引为2的位置
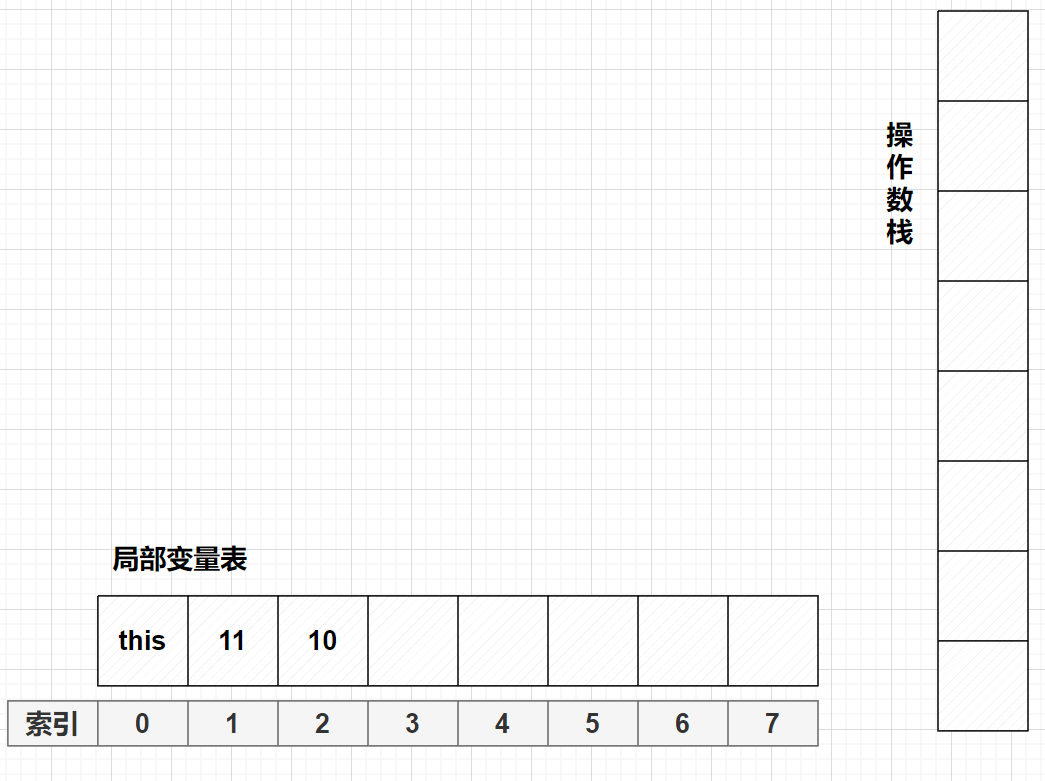
bipush 20
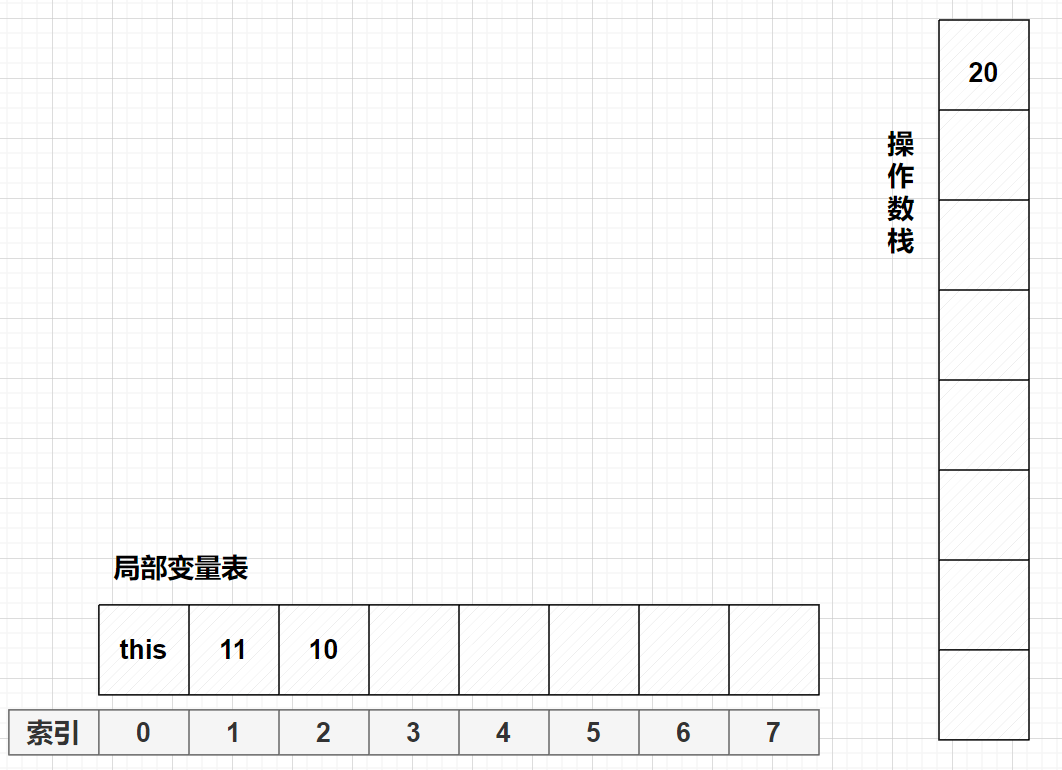
istore_3
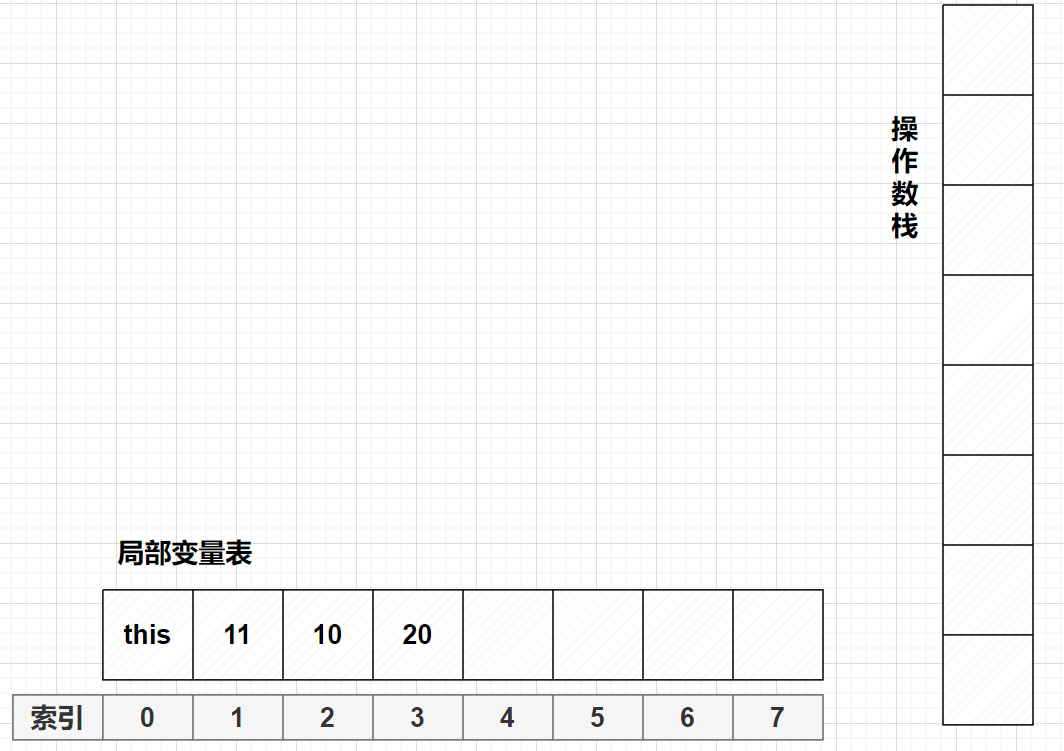
iinc 3 by 1,此时放在索引为3的位置加一,j值变为21

iload_3

istore 4,此时的b值为21,放在索引为4的位置

最后return
如上图,++运算符过程就是如此
最后,我们容易能猜出局部变量表和栈的大小
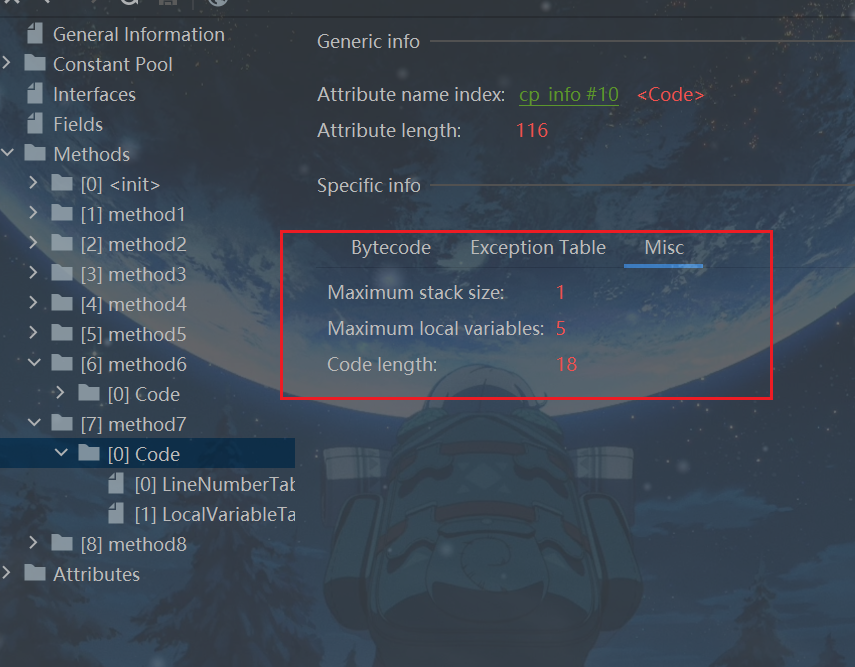
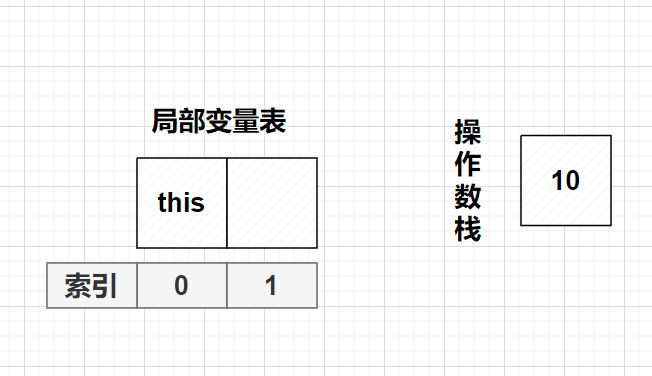
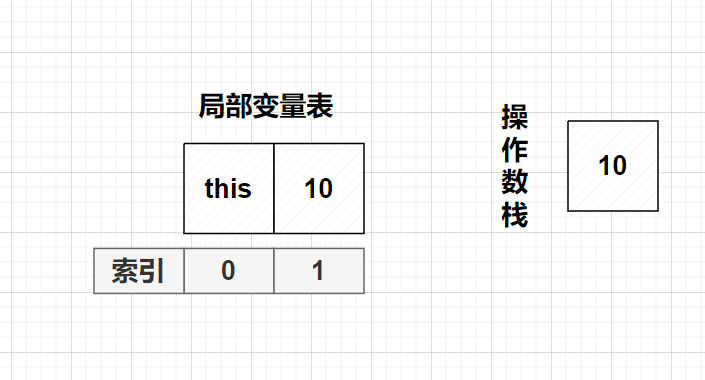
//思考
public void method8(){
int i = 10;
i = i++;
System.out.println(i);//10
}同上的方法,容易推出i还是10

比较指令的说明
- 比较指令的作用是比较栈顶两个元素的大小,并将比较结果入栈。
- 比较指令有: dcmpg, dcmpl、fcmpg、fcmpl、lcmp.与前面讲解的指令类似。首字符d表示double类型,f表示float,l表示long.
- 对于double和float类型的数字,由于NaN的存在,各有两个版本的比较指令。以float为例,有fcmpg和fcmpl两个指令,它们的区别在于在数字比较时,若遇到NaN值,处理结果不同。
- 指令dempl和dempg也是类似的,根据其命名可以推测其含义,在此不再赘述。
- 指令lcmp针对long型整数,由于long型整数没有NaN值,故无需准备两套指令。
举例:指令fcmpg和fcmpl都从栈中弹出两个操作数,并将它们做比较,设栈项的元素为v2,栈顶顺位第2位的元素为v1,若v1=v2,则压入0:若v1>v2则压入1:若v1<v2则压入-1.
两个指令的不同之处在于,如果遇到NaN值, fcmpg会压入1,而fcmpl会压入-1.
4.类型转换指令
1、类型转换指令说明
① 类型转换指令可以将两种不同的数值类型进行相互转换。
②这些转换操作一般用于实现用户代码中的显式类型转换操作,或者用来处理字节码指令集中数据类型相关指令无法与数据类型一一对应的问题。
1.宽化类型转换
宽化类型转换(Widening Numeric Conversions)
1.转换规则:
Java虚拟机直接支持以下数值的宽化类型转换(widening numeric conversion,小范围类型向大范围类型的安全转换)。也就是说,并不需要指令执行,包括:
- 从int类型到long、float或者double类型。对应的指令为: i2l、i2f、i2d
- 从long类型到float、double类型。对应的指令为:l2f、l2d
- 从float类型到double类型。对应的指令为:f2d
- 简化为:int –> long –> float –> double
//针对于宽化类型转换的基本测试
public void upCast1(){
int i = 10;
long l = i;
float f = i;
double d = i;
float f1 = l;
double d1 = l;
double d2 = f1;
}
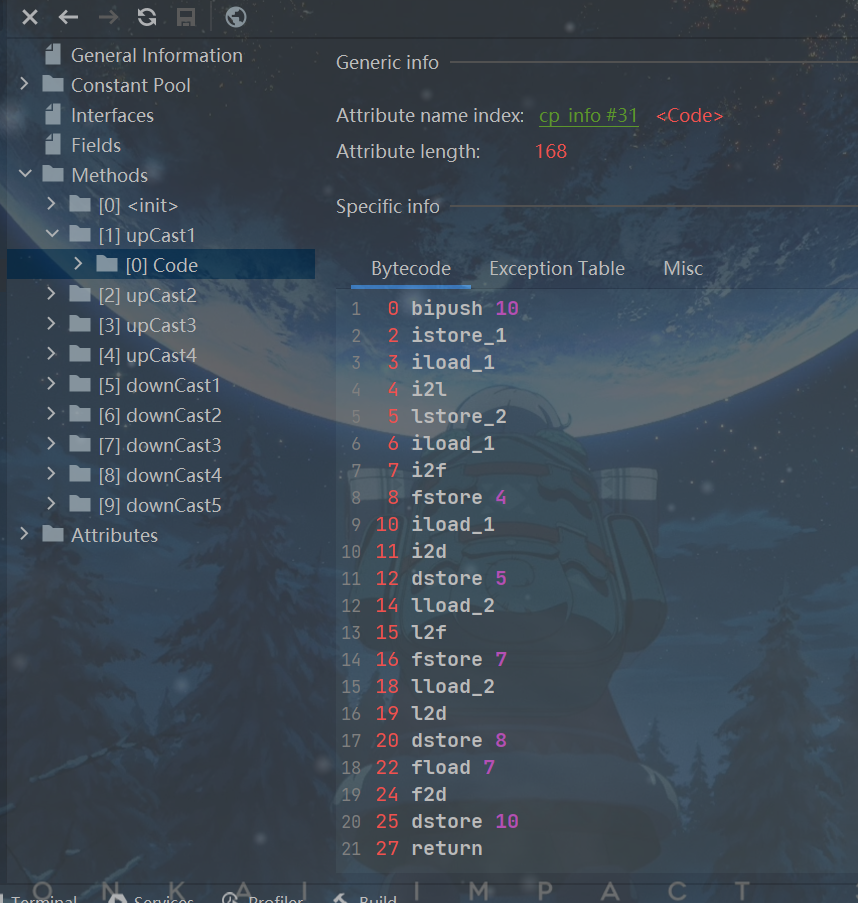
2. 精度损失问题
2.1 宽化类型转换是不会因为超过目标类型最大值而丢失信息的,例如,从int转换到 long,或者从int转换到double.都不会丢失任何信息,转换前后的值是精确相等的。
2.2 从int、long类型数值转换到float,或者long类型数值转换到double时,将可能发生精度丢失——可能丢失掉几个最低有效位上的值,转换后的浮点数值是根据IEEE754最接近舍入模式所得到的正确整数值。
原因:
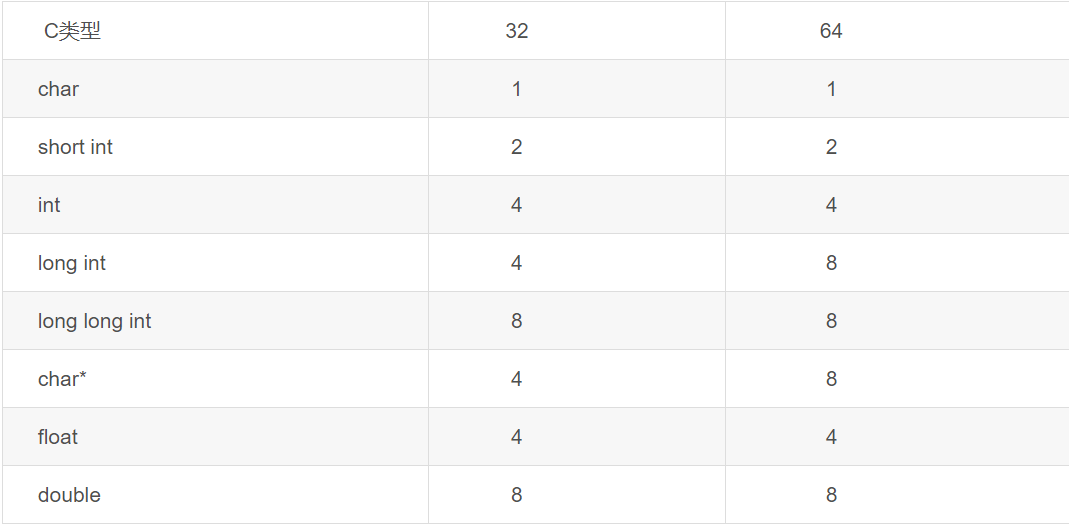
尽管宽化类型转换实际上是可能发生精度丢失的,但是这种转换永远不会导致Java虚拟机抛出运行时异常。
//举例:精度损失的问题
@Test
public void upCast2(){
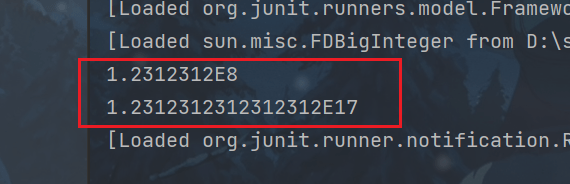
int i = 123123123;
float f = i;
System.out.println(f);//123123120
long l = 123123123123L;
l = 123123123123123123L;
double d = l;
System.out.println(d);//123123123123123120
}
3.补充说明
从byte、char和short类型到int类型的宽化类型转换实际上是不存在的。对于byte类型转为int,虚拟机并没有做实质性的转化处理,只是简单地通过操作数栈交换了两个数据。而将byte转为long时,使用的是i2l,可以看到在内部byte在这里已经等同于int类型处理,类似的还有short类型,这种处理方式有两个特点:
一方面可以减少实际的数据类型,如果为short和byte都准备一套指令,那么指令的数量就会大增,而虚拟机目前的设计上,只愿意使用一个字节表示指令,因此指令总数不能超过256个,为了节省指令资源,将short和byte当做int处理也在情理之中。
另一方面,由于局部变量表中的槽位固定为32位,无论是byte或者short存入局部变量表,都会占用32位空间。从这个角度说,也没有必要特意区分这几种数据类型。
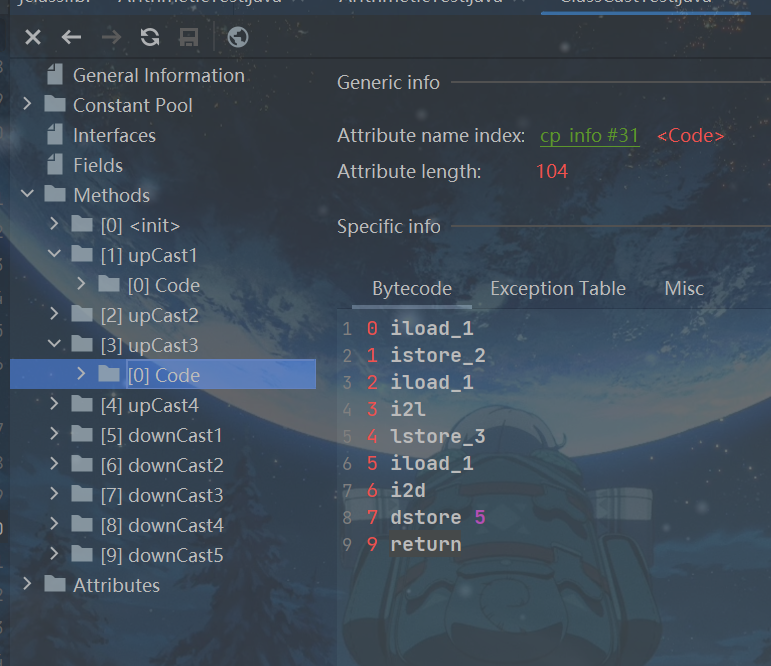
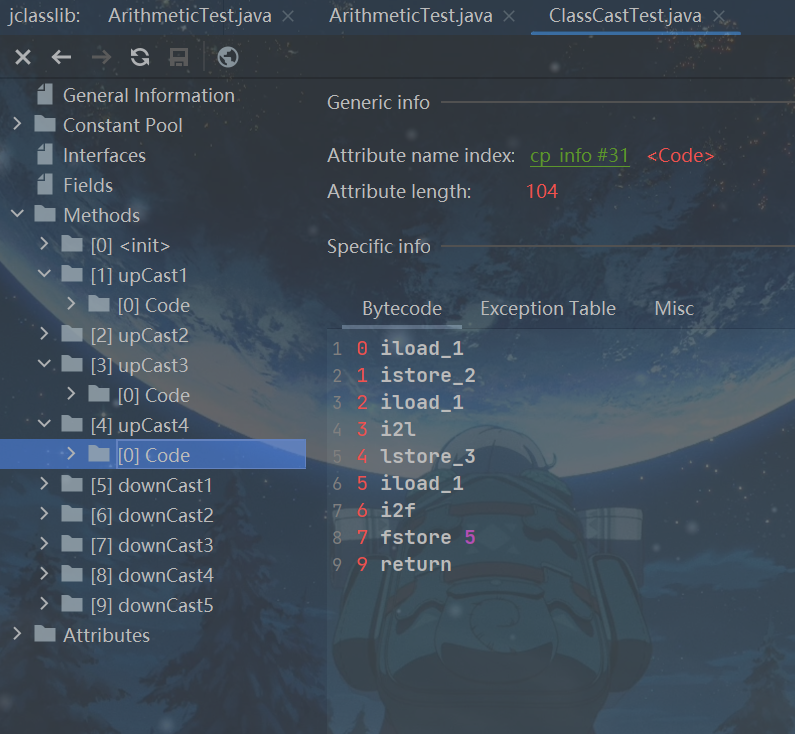
//针对于byte、short等转换为容量大的类型时,将此类型看做int类型处理。
public void upCast3(byte b){
int i = b;
long l = b;
double d = b;
}
public void upCast4(short s){
int i = s;
long l = s;
float f = s;
}
2.窄化类型转换(强制类型转换)
窄化类型转换(Narrowing Numeric Conversion)
1.转换规则
Java虚拟机也直接支持以下窄化类型转换:
- 从int类型至byte、short或者char类型。对应的指令有:i2b、i2s、i2c
- 从long类型到int类型。对应的指令有:l2i
- 从float类型到int或者long类型。对应的指令有:f2i、f2l
- 从double类型到int、long或者float类型。对应的指令有:d2i、d2l、d2f
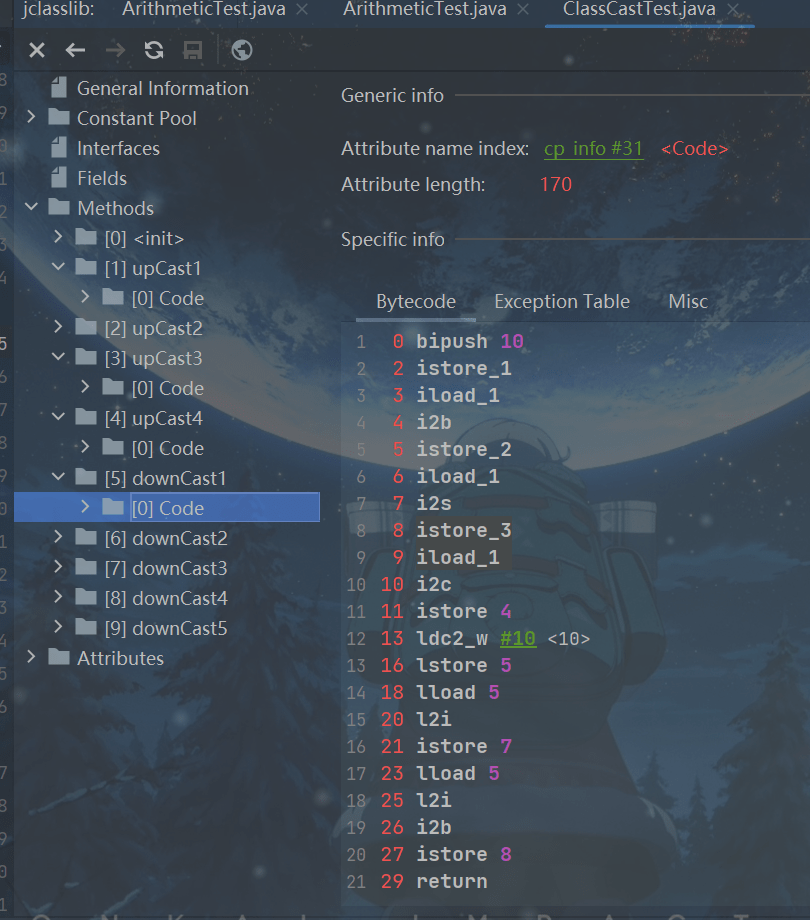
//窄化类型转换
//基本的使用
public void downCast1(){
int i = 10;
byte b = (byte)i;
short s = (short)i;
char c = (char)i;
long l = 10L;
int i1 = (int)l;
byte b1 = (byte) l;
}
public void downCast2(){
float f = 10;
long l = (long)f;
int i = (int)f;
byte b = (byte)f;
double d = 10;
byte b1 = (byte)d;
}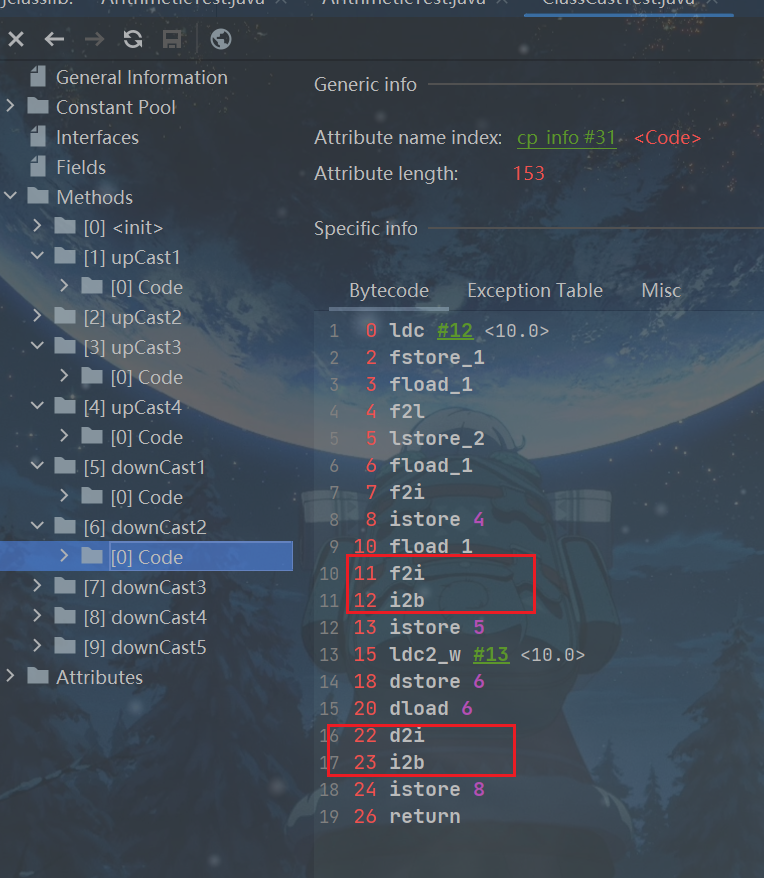
注意:short转换成byte,会把short当成int,使用i2b:
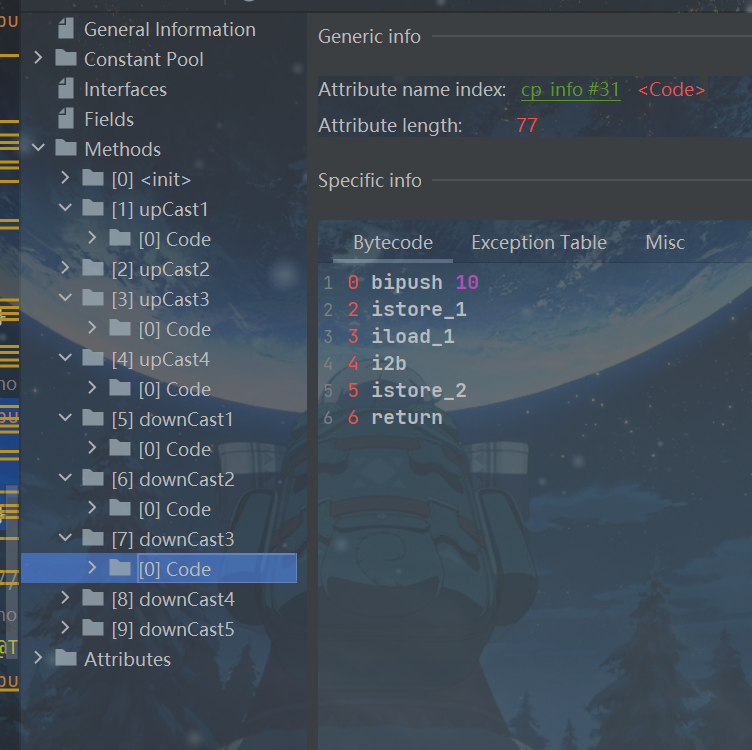
public void downCast3(){
short s = 10;
byte b = (byte)s;
}
2. 精度损失问题
窄化类型转换可能会导致转换结果具备不同的正负号、不同的数量级,因此,转换过程很可能会导致数值丢失精度。
尽管数据类型窄化转换可能会发生上限溢出、下限溢出和精度丢失等情况,但是Java虚拟机规范中明确规定数值类型的窄化转换指令永远不可能导致虚拟机抛出运行时异常
//窄化类型转换的精度损失
@Test
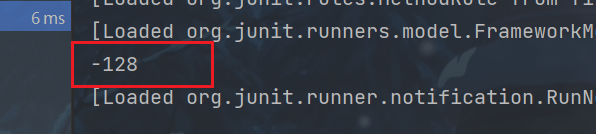
public void downCast4(){
int i = 128;
byte b = (byte)i;
System.out.println(b);
}
3. 补充说明
3.1 当将一个浮点值窄化转换为整数类型T (T限于int或long类型之一)的时候,将遵循以下转换规则:
- 如果浮点值是NaN,那转换结果就是int或long类型的0。
- 如果浮点值不是无穷大的话,浮点值使用IEEE 754的向零舍入模式取整,获得整数值v,如果v在目标类型T(int或long)的表示范围之内,那转换结果就是v。否则,将根据v的符号,转换为T所能表示的最大或者最小正数
3.2 当将一个 double 类型窄化转换为 float 类型时,将遵循以下转换规则:
通过向最接近数舍入模式舍入一个可以使用float类型表示的数字。最后结果根据下面这3条规则判断:
- 如果转换结果的绝对值太小而无法使用float来表示,将返回 float类型的正负零。
- 如果转换结果的绝对值太大而无法使用 float来表示,将返回 float类型的正负无穷大。
- 对于double 类型的 NaN值将按规定转换为 float类型的 NaN值.
@Test
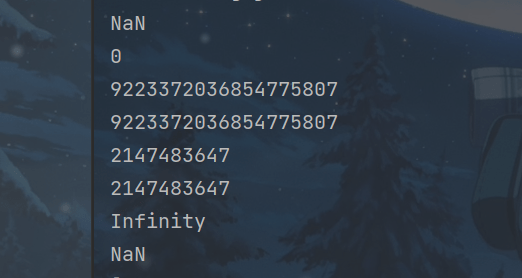
public void downCast5(){
double d1 = Double.NaN; //0.0 / 0.0
int i = (int)d1;
System.out.println(d1);
System.out.println(i);
double d2 = Double.POSITIVE_INFINITY;
long l = (long)d2;
int j = (int)d2;
System.out.println(l);
System.out.println(Long.MAX_VALUE);
System.out.println(j);
System.out.println(Integer.MAX_VALUE);
float f = (float)d2;
System.out.println(f);
float f1 = (float)d1;
System.out.println(f1);
}
参考资料:
尚硅谷宋红康:JVM全套教程:https://www.bilibili.com/video/BV1PJ411n7xZ
周志明:深入理解java虚拟机
张秀宏:自己动手写Java虚拟机 (Java核心技术系列)